Mahout安装部署
0x01 简介
Mahout 是一套具有可扩充能力的机器学习类库。它提供机器学习框架的同时,还实现了一些可扩展的机器学习领域经典算法的实现,可以帮助开发人员更加方便快捷地创建智能应用程序。通过和 Apache Hadoop 分布式框架相结合,Mahout 可以有效地使用分布式系统来实现高性能计算。
0x02 安装配置Mahout
2.1 下载安装
下载地址:http://archive.apache.org/dist/mahout/
安装版本:apache-mahout-distribution-0.11.1.tar.gz
$ tar -zxvf apache-mahout-distribution-0.11.1.tar.gz
$ mv apache-mahout-distribution-0.11.1 /home/hadoop/cloud/mahout-0.11.1
$ ln -s /home/hadoop/cloud/mahout-0.11.1 /home/hadoop/cloud/mahout
2.2 配置环境变量
# vim /etc/profile
export MAHOUT_HOME=/home/hadoop/mahout
export PATH=$PATH:$MAHOUT_HOME/bin:$MAHOUT_HOME/conf
使配置立即生效
# source /etc/profile
# su hadoop
$ source /etc/profile
2.3 验证
然后在单机上检验Mahout是否安装完成。使用如下命令看是否能呈现出Mahout中一些集成的算法。
[hadoop@master bin]$ ./mahout
MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.
Running on hadoop, using /home/hadoop/cloud/hadoop/bin/hadoop and HADOOP_CONF_DIR=/home/hadoop/cloud/hadoop/etc/hadoop
MAHOUT-JOB: /home/hadoop/cloud/mahout/mahout-examples-0.11.1-job.jar
An example program must be given as the first argument.
Valid program names are:
arff.vector: : Generate Vectors from an ARFF file or directory
baumwelch: : Baum-Welch algorithm for unsupervised HMM training
canopy: : Canopy clustering
cat: : Print a file or resource as the logistic regression models would see it
cleansvd: : Cleanup and verification of SVD output
clusterdump: : Dump cluster output to text
clusterpp: : Groups Clustering Output In Clusters
cmdump: : Dump confusion matrix in HTML or text formats
cvb: : LDA via Collapsed Variation Bayes (0th deriv. approx)
cvb0_local: : LDA via Collapsed Variation Bayes, in memory locally.
describe: : Describe the fields and target variable in a data set
evaluateFactorization: : compute RMSE and MAE of a rating matrix factorization against probes
fkmeans: : Fuzzy K-means clustering
hmmpredict: : Generate random sequence of observations by given HMM
itemsimilarity: : Compute the item-item-similarities for item-based collaborative filtering
kmeans: : K-means clustering
lucene.vector: : Generate Vectors from a Lucene index
matrixdump: : Dump matrix in CSV format
matrixmult: : Take the product of two matrices
parallelALS: : ALS-WR factorization of a rating matrix
qualcluster: : Runs clustering experiments and summarizes results in a CSV
recommendfactorized: : Compute recommendations using the factorization of a rating matrix
recommenditembased: : Compute recommendations using item-based collaborative filtering
regexconverter: : Convert text files on a per line basis based on regular expressions
resplit: : Splits a set of SequenceFiles into a number of equal splits
rowid: : Map SequenceFile<Text,VectorWritable> to {SequenceFile<IntWritable,VectorWritable>, SequenceFile<IntWritable,Text>}
rowsimilarity: : Compute the pairwise similarities of the rows of a matrix
runAdaptiveLogistic: : Score new production data using a probably trained and validated AdaptivelogisticRegression model
runlogistic: : Run a logistic regression model against CSV data
seq2encoded: : Encoded Sparse Vector generation from Text sequence files
seq2sparse: : Sparse Vector generation from Text sequence files
seqdirectory: : Generate sequence files (of Text) from a directory
seqdumper: : Generic Sequence File dumper
seqmailarchives: : Creates SequenceFile from a directory containing gzipped mail archives
seqwiki: : Wikipedia xml dump to sequence file
spectralkmeans: : Spectral k-means clustering
split: : Split Input data into test and train sets
splitDataset: : split a rating dataset into training and probe parts
ssvd: : Stochastic SVD
streamingkmeans: : Streaming k-means clustering
svd: : Lanczos Singular Value Decomposition
testnb: : Test the Vector-based Bayes classifier
trainAdaptiveLogistic: : Train an AdaptivelogisticRegression model
trainlogistic: : Train a logistic regression using stochastic gradient descent
trainnb: : Train the Vector-based Bayes classifier
transpose: : Take the transpose of a matrix
validateAdaptiveLogistic: : Validate an AdaptivelogisticRegression model against hold-out data set
vecdist: : Compute the distances between a set of Vectors (or Cluster or Canopy, they must fit in memory) and a list of Vectors
vectordump: : Dump vectors from a sequence file to text
viterbi: : Viterbi decoding of hidden states from given output states sequence
如果看到上述的信息,恭喜你,已经基本安装成功了,很简单的。
但是这里要重点强调一下:上面出现的信息
MAHOUT_LOCAL is not set; adding HADOOP_CONF_DIR to classpath.
Running on hadoop, using /home/hadoop/hadoop-2.2.0/bin/hadoop and HADOOP_CONF_DIR=/home/hadoop/hadoop-2.2.0/etc/hadoop
MAHOUT-JOB: /home/hadoop/apache-mahout-distribution-0.11.0/mahout-examples-0.11.0-job.jar
并不是说配置有误,恰恰相反,要是配置了变量 MAHOUT_LOCAL,那么完全体现不出 Mahout 的威力了,具体的可参考下面的解释
Mahout运行配置可以在 \(MAHOUT_HOME/bin/mahout 里面进行设置,实际上\)MAHOUT_HOME/bin/mahout就是Mahout在命令行的启动脚本,这一点与Hadoop相似,但也又不同
Hadoop在 $HADOOP_HOME\conf 下面还提供了专门的hadoop-env.sh文件进行相关环境变量的配置,而Mahout在conf目录下没有提供这样的文件
MAHOUT_LOCAL 与 HADOOP_CONF_DIR 这两个参数是控制 Mahout 是在本地运行还是在 Hadoop 上运行的关键。
$MAHOUT_HOME/bin/mahout 文件指出,只要设置MAHOUT_LOCAL 的值为一个非空(not empty string)值,则不管用户有没有设置 HADOOP_CONF_DIR 和 HADOOP_HOME 这两个参数,Mahout 都以本地模式运行;换句话说,如果要想 Mahout 运行在Hadoop上,则 MAHOUT_LOCAL 必须为空
HADOOP_CONF_DIR参数指定Mahout运行Hadoop模式时使用的Hadoop配置信息,这个文件目录一般指向的是$HADOOP_HOME目录下的conf目录
除此之外,我们还应该设置 JAVA_HOME 或者 MAHOUT_JAVA_HOME 变量,以及必须将 Hadoop 的执行文件加入到PATH中。要想使用本地模式运行,只需在 $MAHOUT_HOME/bin/mahout 添加一条设置MAHOUT_LOCAL为非空的语句即可
【参考】http://blog.csdn.net/u011414200/article/details/47857655
0x03 测试用例
3.1 准备数据
下载测试数据放到$MAHOUT_HOME/testdata目录下载一个文件synthetic_control.data
文件可能在浏览器中自动打开,另存为即可。
3.2 创建测试目录
创建测试目录testdata,并把数据导入到这个tastdata目录中(这里的目录的名字只能是testdata)
$ hadoop fs -mkdir -p /user/hadoop/testdata
//上传文件
$ hadoop fs -put /home/hadoop/synthetic_control.data
3.3 使用kmeans算法测试
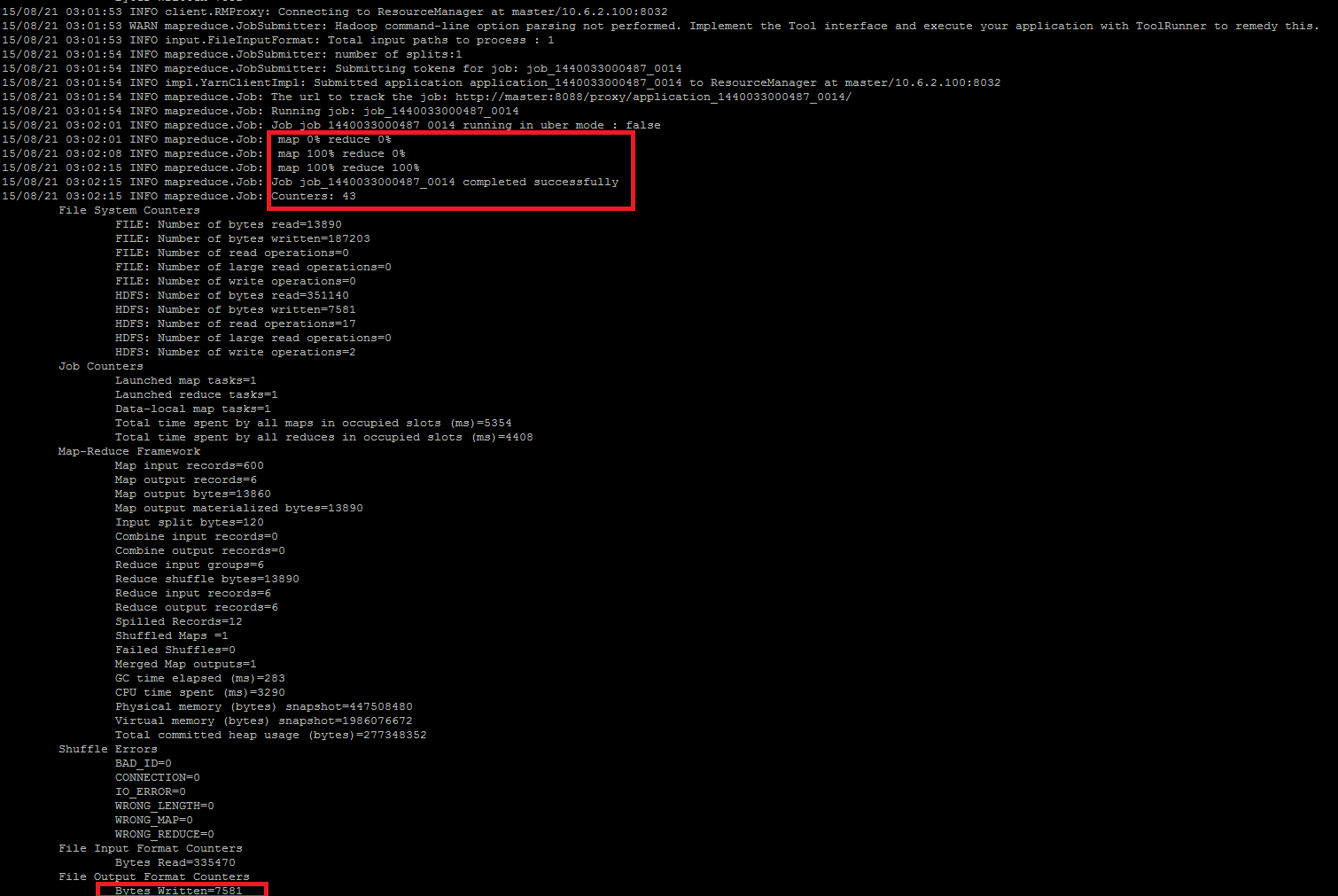
需要运行几分钟
$ bin/hadoop jar mahout-examples-0.11.0-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
注意是hadoop不是mahout花费9分钟左右完成聚类 。
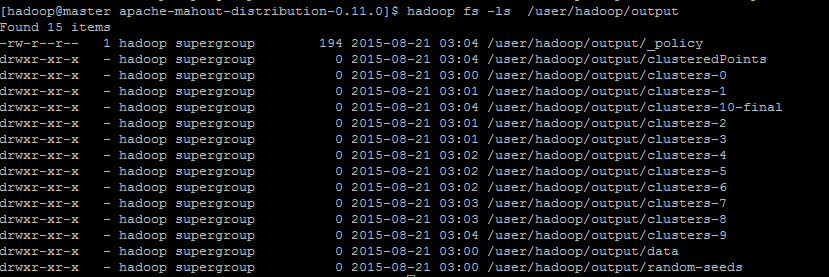
3.4 查看聚类结果
$ hadoop fs -ls /output
查看聚类结果
0x04 参考文献
http://blog.csdn.net/u011414200/article/details/47857655
2017年1月26日, 星期四
update: 2017-10-19 20:59:59 星期四
修改部分内容,重新排版。
Mahout安装部署的更多相关文章
- Oracle安装部署,版本升级,应用补丁快速参考
一.Oracle安装部署 1.1 单机环境 1.2 Oracle RAC环境 1.3 Oracle DataGuard环境 1.4 主机双机 1.5 客户端部署 二.Oracle版本升级 2.1 单机 ...
- KVM安装部署
KVM安装部署 公司开始部署KVM,KVM的全称是kernel base virtual machine,对KVM虚拟化技术研究了一段时间, KVM是基于硬件的完全虚拟化,跟vmware.xen.hy ...
- Linux平台oracle 11g单实例 + ASM存储 安装部署 快速参考
操作环境:Citrix虚拟化环境中申请一个Linux6.4主机(模板)目标:创建单机11g + ASM存储 数据库 1. 主机准备 2. 创建ORACLE 用户和组成员 3. 创建以下目录并赋予对应权 ...
- 分布式文件系统 - FastDFS 在 CentOS 下配置安装部署
少啰嗦,直接装 看过上一篇分布式文件系统 - FastDFS 简单了解一下的朋友应该知道,本次安装是使用目前余庆老师开源的最新 V5.05 版本,是余庆老师放在 Github 上的,和目前你能在网络上 ...
- C# winform安装部署(转载)
c# winform 程序打包部署 核心总结: 1.建议在完成的要打包的项目外,另建解决方案建立安装部署项目(而不是在同一个解决方案内新建),在解决方案上右击-〉添加-〉现有项目-〉选择你要打包的项目 ...
- Ubuntu14.04 Django Mysql安装部署全过程
Ubuntu14.04 Django Mysql安装部署全过程 一.简要步骤.(阿里云Ubuntu14.04) Python安装 Django Mysql的安装与配置 记录一下我的部署过程,也方便 ...
- 比Ansible更吊的自动化运维工具,自动化统一安装部署_自动化部署udeploy 1.0
新增功能: 2015-03-11 除pass(备份与更新)与start(启动服务)外,实现一切自动化. 注:pass与start设为业务类,由于各类业务不同,所以无法实现自动化.同类业务除外,如更新的 ...
- 比Ansible更吊的自动化运维工具,自动化统一安装部署自动化部署udeploy 1.0 版本发布
新增功能: 逻辑与业务分离,完美实现逻辑与业务分离,业务实现统一shell脚本开发,由框架统一调用. 并发多线程部署,不管多少台服务器,多少个服务,同时发起线程进行更新.部署.启动. 提高list规则 ...
- SCCM 2012 R2安装部署过程和问题(三)
上篇 SCCM 2012 R2安装部署过程和问题(二) 个人认为对于使用SCCM 2012的最重要的经验是耐心. SCCM采用分布式部署的架构,不同的站点角色可以部署在不同的服务器上,站点角色之间的通 ...
随机推荐
- 巧用五招提升Discuz!X运行速度
Discuz!X使用的是数据库应用程序,所以,当数据库的大小.帖子的数目.会员的数目,这些因素都会影响到程序的检索速度,尤其是当论坛的影响力大了,这个问题就更为突出了,虽然,康盛对Discuz进行了更 ...
- Oracle 11g RAC 自动应用PSU补丁简明版
环境:Oracle RAC(GI 11.2.0.4 + DB 11.2.0.4) 本文应用补丁信息: Patch 23615403 - Combo of OJVM Component 11.2.0.4 ...
- JDBC注册驱动
一.Sql server2008 使用sqljdbc4.jar private static String driver = "com.microsoft.sqlserver.jdbc.SQ ...
- Android服务端的设计
1.创建自己的MyServletContextListener.java: package yybwb; import java.net.ServerSocket; import javax.serv ...
- gulp环境搭建
简介: gulp是前端开发过程中对代码进行构建的工具,是自动化项目的构建利器:它不仅对网站资源进行优化,而且在开发过程中很多重复的任务,他可以通过明确的工具自动完成,使用它我们不仅可以很愉快的编写代码 ...
- 数控G代码编程详解大全
一.G代码功能简述 G00------快速定位 G01------直线插补 G02------顺时针方向圆弧插补 G03------逆时针方向圆弧插补 G04------定时暂停 G05------通 ...
- python全栈阶段测试(一)
1.执行Python脚本的两种方式 如果想要永久保存代码,就要用文件的方式 如果想要调试代码,就要用交互式的方式 2.Pyhton单行注释和多行注释分别用什么? 单行注释:# 多行注释: '' &qu ...
- win10 设置默认输入法为英文,ctrl +shift切换中文
控制面板-更改输入法,这个界面出现的是电脑现在安装的语言,每个语言中可能有多个输入法,比如我的有微软的和qq的,谁在上谁就是系统的默认语言(本人当然是中文在上),英文中有美式键盘. 如果想要电脑启动的 ...
- 决策树(ID3 )原理及实现
1.决策树原理 1.1.定义 分类决策树模型是一种描述对实例进行分类的树形结构.决策树由结点和有向边组成.结点有两种类型:内部节点和叶节点,内部节点表示一个特征或属性,叶节点表示一个类. 举一个通俗的 ...
- MSDTC启用——分布式事务
一.前言 最近在做一个项目的时候使用了.NET中的System.Transactions(分布式事务),当项目开发完成以后,调用的时候遇到了MSDTC的问题,在查阅了相关资料后将这个问题解决了,大致的 ...