timeit模块
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。
算法是独立存在的一种解决问题的方法和思想。
一道题引入如果 a+b+c=1000,且 a^2+b^2=c^2(a,b,c 为自然数),如何求出所有a、b、c可能的组合?
解决思路1:
import time
start_time = time.time()
# 注意是三重循环
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a**2 + b**2 == c**2 and a+b+c == 1000:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")
#############################
运行结果:
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 214.583347
complete!
枚举法
算法的五大特性:
1.输入: 算法具有0个或多个输入;
2.输出: 算法至少有1个或多个输出;
3.有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成;
4.确定性:算法中的每一步都有确定的含义,不会出现二义性;
5.可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成。
根据上面的枚举法可以看出,多层嵌套的for循环是非常消耗时间的,类似于笛卡儿积的增长。我们完全可以把c的循环解除,根据a+ b+c=1000,c=1000- a - b。
我们的代码可以改成:
import time
start_time = time.time()
# 注意是两重循环
for a in range(0, 1001):
for b in range(0, 1001-a):
c = 1000 - a - b
if a**2 + b**2 == c**2:
print("a, b, c: %d, %d, %d" % (a, b, c))
end_time = time.time()
print("elapsed: %f" % (end_time - start_time))
print("complete!")
###########################
运行结果:
a, b, c: 0, 500, 500
a, b, c: 200, 375, 425
a, b, c: 375, 200, 425
a, b, c: 500, 0, 500
elapsed: 0.182897
complete!
修改代码
从运行时间上来看,第二种方法显然效率要高很多。我们使用大o法来确定算法的效率。
我们假定计算机执行算法每一个基本操作的时间是固定的一个时间单位,那么有多少个基本操作就代表会花费多少时间单位。算然对于不同的机器环境而言,确切的单位时间是不同的,但是对于算法进行多少个基本操作(即花费多少时间单位)在规模数量级上却是相同的,由此可以忽略机器环境的影响而客观的反应算法的时间效率。
怎么解释大O法:“大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。
时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)。
简单来说就是大O法就是忽略常数c,它认为3*n**2和100*n**2属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为它们的效率“差不多”,都为n**2级。
时间复杂度的几条基本计算规则,
基本操作,即只有常数项,认为其时间复杂度为O(1),
顺序结构,时间复杂度按加法进行计算,
循环结构,时间复杂度按乘法进行计算,
分支结构,时间复杂度取最大值,
判断一个算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略,
在没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度。
再回到我们最初的问题,我们第一次使用的枚举法时间复杂度:
T(n) = O(n*n*n) = O(n**3)
第二次的算法时间复杂度:
T(n) = O(n*n*(1+1)) = O(n*n) = O(n**2)
我们之前写过的算法图解里也对大O法进行了解释:
大O法的消耗时间由小到大的顺序为:O(1) < O(logn) < O(n) < O(nlogn) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)。
timeit模块
timeit模块可以用来测试一小段Python代码的执行速度。
class timeit.Timer(stmt='pass', setup='pass', timer=<timer function>)
Timer是测量小段代码执行速度的类。
stmt参数是要测试的代码语句(statment); setup参数是运行代码时需要的设置;相当于我们要使用time需要导入time模块。
timer参数是一个定时器函数,与平台有关。
timeit.Timer.timeit(number=1000000) Timer类中测试语句执行速度的对象方法。number参数是测试代码时的测试次数,默认为1000000次。方法返回执行代码的平均耗时,一个float类型的秒数。
timeit模块
def test1():
l = []
for i in range(1000):
l = l + [i]
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = [i for i in range(1000)]
def test4():
l = list(range(1000)) from timeit import Timer t1 = Timer("test1()", "from __main__ import test1")
print("concat ",t1.timeit(number=1000), "seconds")
t2 = Timer("test2()", "from __main__ import test2")
print("append ",t2.timeit(number=1000), "seconds")
t3 = Timer("test3()", "from __main__ import test3")
print("comprehension ",t3.timeit(number=1000), "seconds")
t4 = Timer("test4()", "from __main__ import test4")
print("list range ",t4.timeit(number=1000), "seconds") # ('concat ', 1.7890608310699463, 'seconds')
# ('append ', 0.13796091079711914, 'seconds')
# ('comprehension ', 0.05671119689941406, 'seconds')
# ('list range ', 0.014147043228149414, 'seconds')
生成列表的效率
所以以后千万别写什么l = l + [i]增加列表了(每次都生成新列表而+=则不会生成新列表+=与extend效果一样),因为列表本身的结构类型所以在列表的头部或者尾部增加或删除也是有区别的。
x = range(2000000)
pop_zero = Timer("x.pop(0)","from __main__ import x")
print("pop_zero ",pop_zero.timeit(number=1000), "seconds")
x = range(2000000)
pop_end = Timer("x.pop()","from __main__ import x")
print("pop_end ",pop_end.timeit(number=1000), "seconds") # ('pop_zero ', 1.9101738929748535, 'seconds')
# ('pop_end ', 0.00023603439331054688, 'seconds')
列表前后插入与删除的区别

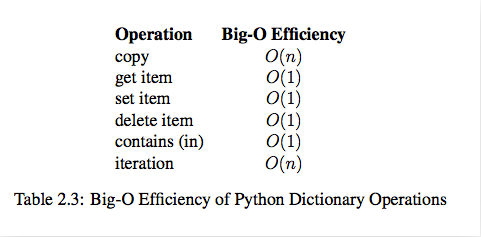
我们希望算法解决问题的效率越快越好,于是我们就需要考虑数据究竟如何保存的问题,这就是数据结构。列表和字典就是Python内建帮我们封装好的两种数据结构。
数据是一个抽象的概念,将其进行分类后得到程序设计语言中的基本类型。如:int,float,char等。数据元素之间不是独立的,存在特定的关系,这些关系便是结构。数据结构指数据对象中数据元素之间的关系。
抽象数据类型(ADT)是把数据类型和数据类型上的运算捆在一起,进行封装。引入抽象数据类型的目的是把数据类型的表示和数据类型上运算的实现与这些数据类型和运算在程序中的引用隔开,使它们相互独立。类似于面向对象提供api操作。
timeit模块的更多相关文章
- timeit模块 与 time模块,计时的区别
time 模块,理解容易 import time time_start = time.time() time_end = time.time() time_use = time_end - time ...
- 如何使用python timeit模块使用实践
其实平时使用测试应用运行时间的情况 细算一下还真的很少.很久没有做性能优化的工作,不管是cProfile还是timeit模块都已经生疏了很久没有使用,我在以前的文章里面有提到过cPfile的性能测试使 ...
- python timeit模块用法
想测试一行代码的运行时间,在python中比较方便,可以直接使用timeit: >>> import timeit #执行命令 >>> t2 = timeit.Ti ...
- python timeit模块
timeit模块timeit模块可以用来测试一小段Python代码的执行速度. class timeit.Timer(stmt='pass', setup='pass', timer=<time ...
- python timeit模块简单用法
timeit模块提供了一种简便的方法来为Python中的小块代码进行计时. 模块调用函数,stmp为要测试的函数,setup为测试环境,number为运行次数 timeit.timeit(stmt=) ...
- 2 timeit模块,python中数据结构
1.timeit模块:代码事件测量模块 timeit模块可以用来测试一小段Python代码的执行速度. class timeit.Timer(stmt='pass', setup='pass', ti ...
- python中的计时器:timeit模块
python中的计时器:timeit模块 (1) timeit - 通常在一段程序的前后都用上time.time()然后进行相减就可以得到一段程序的运行时间,不过python提供了更强大的计时库:ti ...
- python:timeit模块
(鱼c)timeit模块详解——准确测量小段代码的执行时间 http://bbs.fishc.com/forum.php?mod=viewthread&tid=55593&extra= ...
- python之timeit模块
timeit模块: timeit 模块定义了接受两个参数的 Timer 类.两个参数都是字符串. 第一个参数是你要计时的语句或者函数. 传递给 Timer 的第二个参数是为第一个参数语句构建环境的导入 ...
随机推荐
- Golang 中的坑 一
Golang 中的坑 短变量声明 Short variable declarations 考虑如下代码: package main import ( "errors" " ...
- FPGA浮点数定点化
因为在普通的fpga芯片里面,寄存器只可以表示无符号型,不可以表示小数,所以在计算比较精确的数值时,就需要做一些处理,不过在altera在Arria 10 中增加了硬核浮点DSP模块,这样更加适合硬件 ...
- Webpack 2 视频教程 014 - 深入理解 Webpack 2 中的 loader
原文发表于我的技术博客 这是我免费发布的高质量超清「Webpack 2 视频教程」. Webpack 作为目前前端开发必备的框架,Webpack 发布了 2.0 版本,此视频就是基于 2.0 的版本讲 ...
- ubuntu 安装 pythonenv
This will get you going with the latest version of pyenv and make it easy to fork and contribute any ...
- thinkinginjava学习笔记07_多态
在上一节的学习中,强调继承一般在需要向上转型时才有必要上场,否则都应该谨慎使用: 向上转型和绑定 向上转型是指子类向基类转型,由于子类拥有基类中的所有接口,所以向上转型的过程是安全无损的,所有对基类进 ...
- 转:java.lang.OutOfMemoryError: Java heap space错误及处理办法(收集整理、转)
以下是从网上找到的关于堆空间溢出的错误解决办法: Java.lang.OutOfMemoryError: Java heap space =============================== ...
- SpringMVC 如何在页面中获取到ModelAndView绑定的值
springMVC中通过ModelAndView进行后台与页面的数据交互,那么如何在页面中获取ModelAndView绑定的值呢? 1.在JSP中通过EL表达式进行获取(比较常用) 后台:ModelA ...
- gitlab勾住rocket chat
出于协作的要求, 需要在把gitlab的push event勾到rocket chat上面, 通知协作的其他人. BUT rocket chat提供的脚本没有具体的文件diff, so, 只好修改一下 ...
- HDFS High Availability Using the Quorum Journal Manager
http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.htm ...
- Dagoin之modelform组件
ModelForm a. class Meta: model, # 对应Model的 fields=None, # 字段 exclude=None, # 排除字段 labels=None, # 提 ...