SgLang代码细读-2.forward过程
SgLang代码细读-2.forward过程
总览
Forward的主要过程围绕着 run_batch->TPModelWorker->ModelRunner->Model->layer->AttentionBackend->process_batch_result 这个链条展开
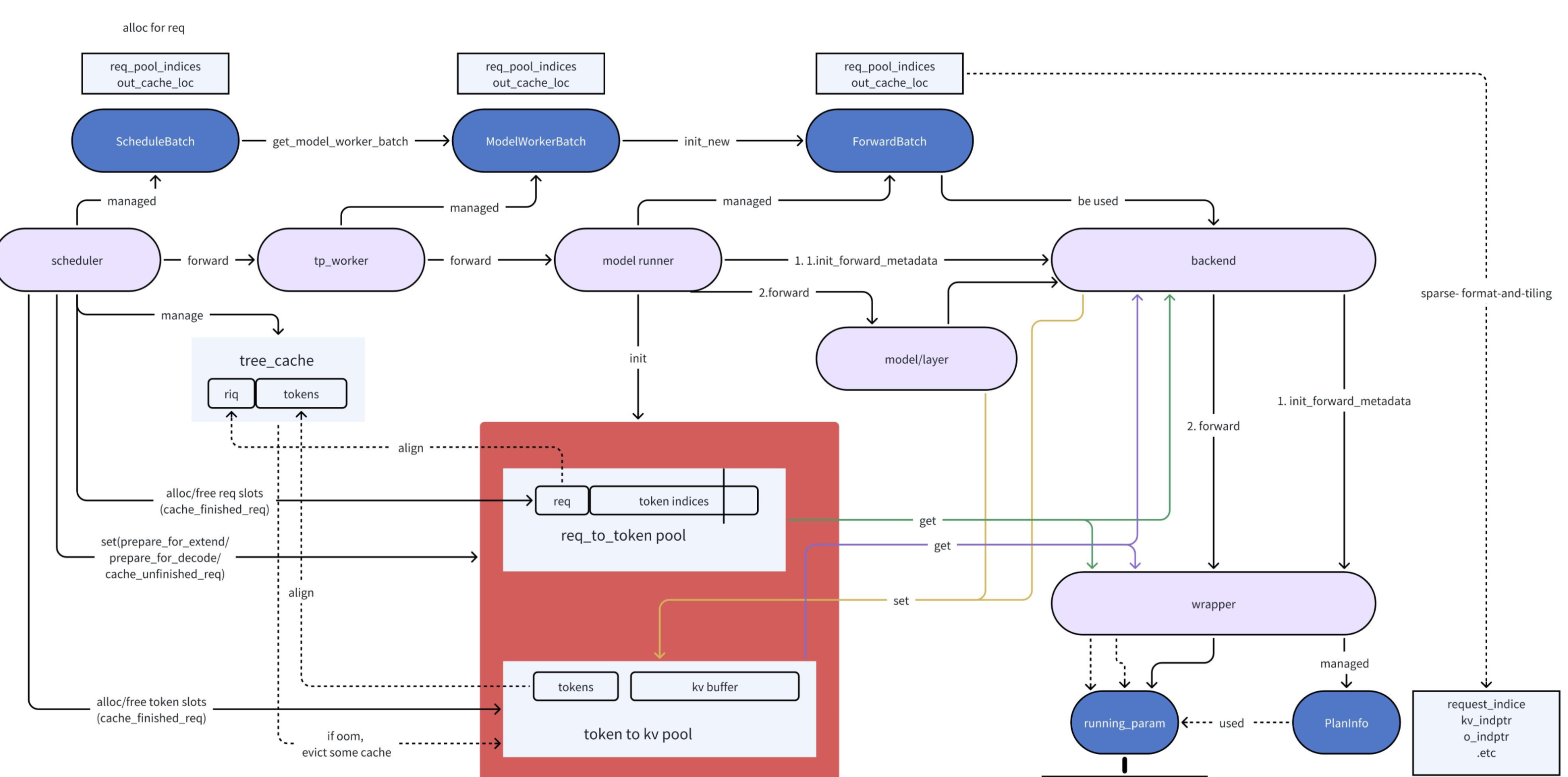
Prefill由于输入不定长, 无法开启cudagraph, 而decode由于输入输出是one-by-one的模式, 且能通过merge_batch的方式组装batch, 因此可以通过cudaGraph来加速. 而且P和D对与kvCache的处理逻辑也不同, 在看的时候重点关注这两部分, 看的时候model以deepseek,MLA,fa3为主.
ScheduleBatch -> ModelWorkerBatch -> ForwardBatch 这三个的关系:
ScheduleBatch: 最上层的batch结构, 和scheduler交互, 大多数在CPU上的数据, 比如: 当前batch的类型,模型参数,sampling参数, 请求级信息, kvcache的索引数据等ModelWorkerBatch:ScheduleBatch的子集, 只包含和forward相关的dataForwardBatch: 最底层结构, 主要包含forward所需的GPU tensor相关data
共同forward逻辑
1.batch.get_model_worker_batch()
seq_lens从GPU->CPU / 维护bid(batch id) / 从ScheduleBatch构建ModelWorkerBatch
2.tp_worker.forward_batch_generation(model_worker_batch)
- 更新sampling_info: decode采样所需的参数和相关惩罚系数, 如temperatures, top_p, top_k等.
- overlap状态下: 把ModelWorkerBatch塞到input_queue里, input_queue是一个独立的线程不断loop
forward_thread_func, 从input_queue里循环pop后进行前向计算, 计算完后同步传入的event.
关闭overlap状态的逻辑:
- ForwardBatch.init_new
- 如果开启了PP, 不是PP第一层的节点需要先经过通信拿到上一层PP的输出, 具体步骤:
pp_group.recv_tensor_dict, 如果TP>1, 那么先要把同TPRank的上一层节点进行P2P通信, 拿到分片结果, 然后再把同一个TPgroup的激活allGather到TP_Rank=0的节点上, 最后以这个作为forward输入 self.model_runner.forward: 根据forwardBatch类型(extend/decode/idle), 判断接下来要走的forward逻辑, 而forward所使用的attn_backend是通过server_args在启动时的入参来指定的
Prefill (forward_extend)
attn_backend.init_forward_metadata: 因为每个layer存在相同的数据, 比如max_seq_len, 如果在forward之前就算好就减少了layer-1次的重复计算. 所以把layer间的共有数据定义为metadata.self.model.forward: 根据modelConfig实例化的model. 通过model-path这个参数进行的模型加载, 组网逻辑在sglang/python/sglang/srt/models下面. 模型部分的优化与cache部分的读写和通信, 在下一篇blog中细说
Decode (self.cuda_graph_runner.replay)
CUDAGraphRunner
initialize
在ModelRunner初始化的时候, 一起初始化的init_cuda_graphs, 主要是几个步骤:
get_batch_sizes_to_capture: 根据req_to_token_pool.size,server_args.cuda_graph_max_bs,server_args.torch_compile_max_bs这几个参数或变量, 确定要捕获的最大batch_size, 确保显存不会超限.attn_backend.init_cuda_graph_state: 根据确定的bs列表拿到最大的bs, 根据maxbs确定attn中使用的中间激活分配的固定长度- 根据max_bs/max_num_token, 分配输入显存空间, 同时打开torch.compile转静态图.
- 进行图capture, 对每个可用的bs跑一次forward(
capture_one_batch_size), 使能够捕获到图.
执行
cuda_graph_runner.replay, 根据当前forward_batch的batch_size来确定跑哪张图, 然后进入cudaGraph的replay
采样与惩罚
model_runner.sample
preprocess_logits
- enable_overlap时, 需要先等待sampling_info_done这个event跑完.
apply_logits_bias:- 如果存在惩罚规则时,
penalizer_orchestrator.apply(logits), 对对应的logits进行惩罚. - 当请求对输出有格式要求时, 比如json. 需要通过grammar->vocab_mask来规范化输出
- 如果存在惩罚规则时,
惩罚规则
目前有3种规则:
- BatchedMinNewTokensPenalizer: 在每个请求生成的 token 数未达到min_new_tokens之前,强制禁止生成,从而保证每个请求至少生成指定数量的新 token
- BatchedPresencePenalizer: 在每个请求的输出序列中,统计每个 token 已经出现的次数,并根据frequency_penalty,对这些 token 的 logits 进行惩罚(减去一定分数),从而降低它们再次被采样的概率。这样可以有效减少重复 token 的生成,提高输出的多样性
- BatchedPresencePenalizer: 在每个请求的输出序列中,如果某个 token 已经出现过一次,就对该 token 的 logits 施加一次惩罚(减去 presence_penalty 分数),从而降低它再次被采样的概率
MTP(Multi-Token Prediction)
单次预测多个词用于加速decode阶段的预测, 主要原理如图, 主要分成3步:
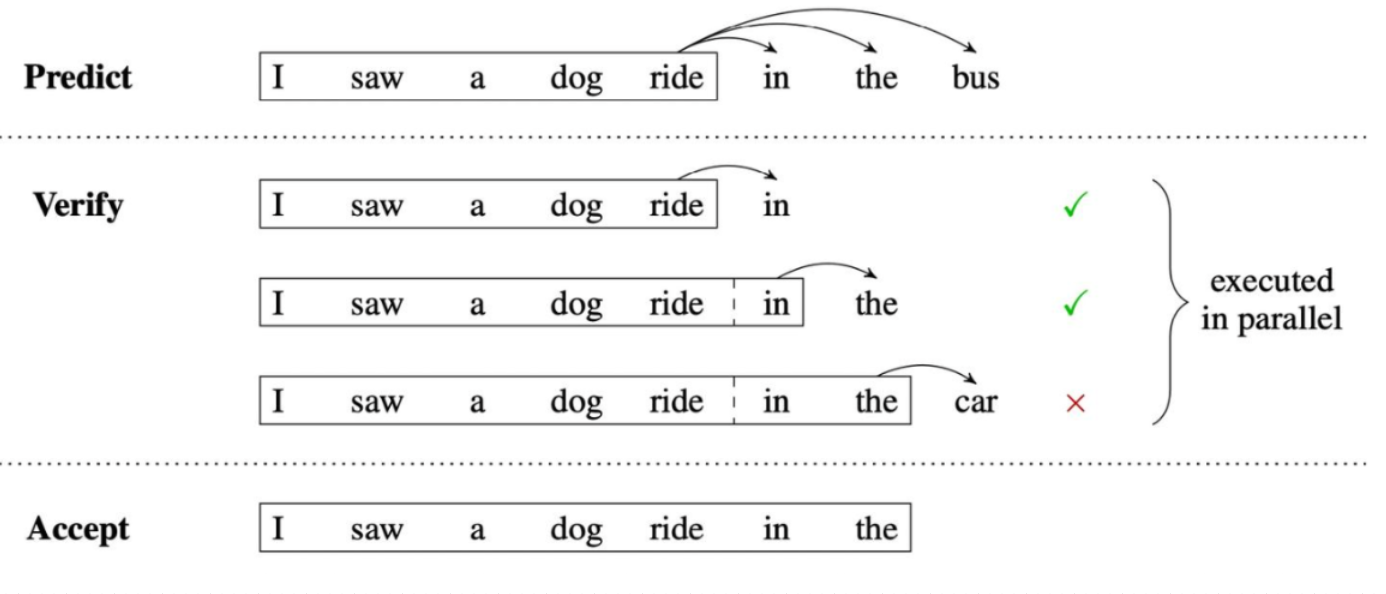
- 使用小模型(draft)用于推理出多个token, in the bus即为结果.
- 把小模型预估出的3个token分别组成batchsize=3的一个batch进行并行推理
- 在batch内与之前的多个token一致的最长前缀记录下来, 在这里in the 一致, 那么就可以直接accept后输出. 这样就能减少对main模型的one-by-one串行调用, 加速推理.
- 如果想进一步加速, 那么在verify的时候, 可以也同步跑小模型进行推理, 把最长前缀的那个batch_index推理出的draft token作为下一次verify的输入. 流程就变成了predict->verify->accept->verify->accept->...
在deepseek中的MTP:
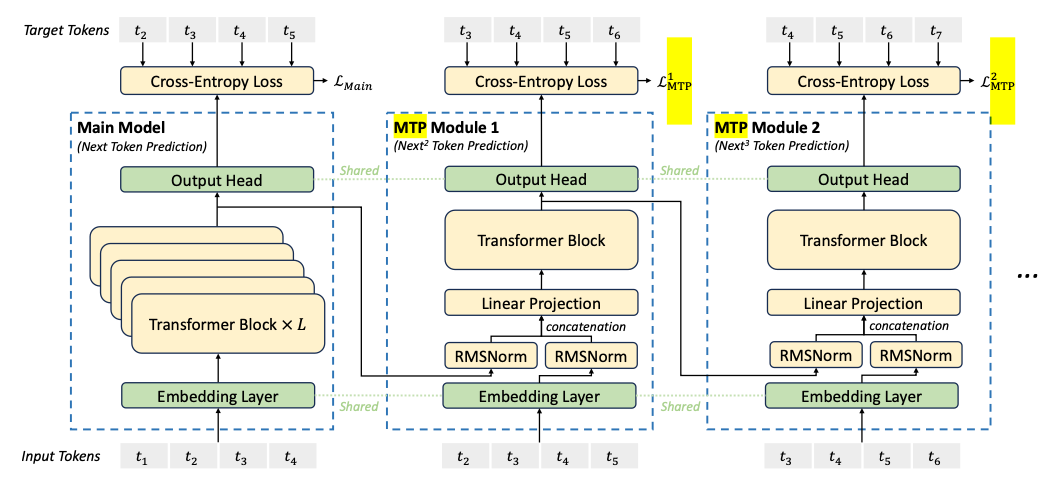
通过样本错位的方式进行训练, 通过N次样本错位就能训出用于nextN预估的N个draft模型.
forward_batch_speculative_generation (python/sglang/srt/speculative/eagle_worker.py)
draft
cumulate_output_tokens: 计算token惩罚项alloc_paged_token_slots_extend: 为next_k token在kv缓存池中申请空间, 如果不够则从tree_cache中驱逐(evict), backup_state的作用是备份当前的allocator状态, 如果后续出现显存不足之类的问题, 可以方便的回滚assign_draft_cache_locs: 把out_cache_locs里的数据copy到kv缓存池里用于后续的forwarddraft_forward: 也可以采用cudaGraph的运行模式, 这里以非cudaGraph模式看逻辑, for循环K次select_top_k_tokens: 把上一步算出的topk候选token中,和当前top路径相乘, 拿到联合概率最高的k条路径.然后更新input_ids, hidden_states, scores(选中路径的分数)等- 构造这次循环draft_model.forward需要用到的forwardBatch, 进入forward拿到
logics_output logics_output经过softmax, 获取到各个输出的token和其对应的概率, 选出topk用于下一次循环.
draft-tree:
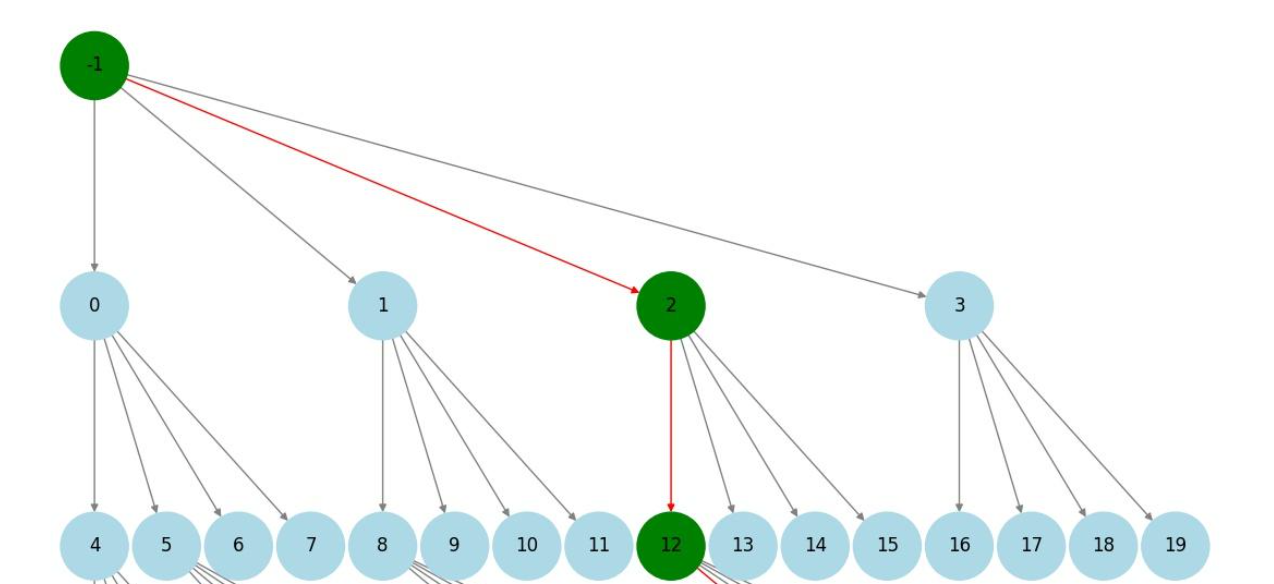
verify
spec_info.prepare_for_verify: 提前分配kv缓存空间target_worker.forward_batch_generation: 在正常模型推理之前, 把spec_info中的position替换到forward_batch里, 另外再draft的时候就通过seq_lens_sum重新组织了batch的排布. 便于并行验证.spec_info.verify->verify_tree_greedy: 当采样策略设置为贪心时, 通过贪心策略在生成的draft树上找到最长能够接受的目标token路径.否则通过正常采样逻辑从树中获取路径
判断batch内有木有直接推理到的输出, 如果有完成的请求进行batch 动态收缩,只保留未完成请求,已完成请求从 batch 中剔除,后续只推理未完成部分, 返回加上接受token长度的verify结果
如果verify之后的verifyied_id不为空, 还需要继续进行验证
forward_draft_extend_after_decode
参考:
sglang blog: https://lmsys.org/blog/2025-05-05-large-scale-ep/
sglang源码学习笔记: https://zhuanlan.zhihu.com/p/18285771025
decode采样策略: https://zhuanlan.zhihu.com/p/29031912458
sharedExpert与普通Expert融合: https://zhuanlan.zhihu.com/p/1890914228480767683
sglang投机推理: https://www.zhihu.com/search?type=content&q=sglang nextn
DeepSeek MTP解析: https://zhuanlan.zhihu.com/p/18056041194
投机算法EAGLE3: https://zhuanlan.zhihu.com/p/29007609465
SgLang代码细读-2.forward过程的更多相关文章
- 从linux内核代码分析操作系统启动过程
朱宇轲 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 在本次的实验中, ...
- Linux | GCC如何实现代码编译&&汇编&&链接过程
正文: 每次我们程序员所写的 代码 是给程序员看的呢?还是给电脑看的?其实我们所写的代码只是我们程序员之间交流的一样特殊语言,电脑是看不懂的.那么我们如何实现人机交流呢?这就不得不请出我们我们今天 ...
- iOS:使用block代码块实现事件处理过程中的回调
block是什么,这里就不多加强调了,它的优点: 第一:执行效率高,速度快 第二:使用起来比代理简单,省却不少代码,增强代码美感 有一些小的知识点要强调一下: 第一点:它类似于一个匿名函数,也跟jav ...
- java基础课程笔记 static 主函数 静态工具类 classpath java文档注释 静态代码块 对象初始化过程 设计模式 继承 子父类中的函数 继承中的构造函数 对象转型 多态 封装 抽象类 final 接口 包 jar包
Static那些事儿 Static关键字 被static修饰的变量成为静态变量(类变量) 作用:是一个修饰符,用于修饰成员(成员变量,成员方法) 1.被static修饰后的成员变量只有一份 2.当成员 ...
- 【Linux】【Jenkins】代码编译和执行过程中的问题汇总
1.问题1:java.io.FileNotFoundException: /root/.jenkins/workspace/Videoyi_AutoTest_Maven/config-log4j\lo ...
- TortoiseGit推送代码到Gerrit的过程
gerrit的安装不在本博客的说明范围中,本博客阐述的是使用TortoiseGit 提交代码到gerrit上的步骤和配置. 一.Git 说明:这个工具只要用来做一个仿真的linux环境,可以执行大部分 ...
- CVE-2019-0708远程桌面服务远程执行代码漏洞exp利用过程
CVE-2019-0708远程桌面服务远程执行代码漏洞 上边这洞是啥我就不多说了,描述类的自行百度. 受影响系统版本范围: Windows Server 2008 R2 Windows Server ...
- java代码的编译执行过程
- S2-057远程代码执行漏洞复现过程
0x01 搭建环境docker https://github.com/vulhub/vulhub/tree/master/struts2/s2-048 docker-compose up -d 0x0 ...
- java代码的初始化过程研究
刚刚在ITeye上看到一篇关于java代码初始化的文章,看到代码我试着推理了下结果,虽然是大学时代学的知识了,没想到还能做对.(看来自己大学时掌握的基础还算不错,(*^__^*) 嘻嘻……)但 ...
随机推荐
- WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战
开源项目名称:leagueoflegends-OpenSilver 作者:Vicky&James leagueoflegends-opensilver:https://github.com/j ...
- SQL SERVER日常运维巡检系列之-性能
前言 做好日常巡检是数据库管理和维护的重要步骤,而且需要对每次巡检日期.结果进行登记,同时可能需要出一份巡检报告. 本系列旨在解决一些常见的困扰: 不知道巡检哪些东西 不知道怎么样便捷体检 机器太多体 ...
- SQL注入之WAF绕过注入
绕过WAF: WAF防御原理: 简单来说waf就是解析http请求,检测http请求中的参数是否存在恶意的攻击行为,如果请求中的参数和waf中的规则库所匹配,那么waf则判断此条请求为攻击行为并进行阻 ...
- docker批量删除容器或镜像
删除容器 停止所有容器 删除所有容器,需要先停止所有运行中的容器 docker stop `docker ps -a -q` docker ps -a -q,意思是列出所有容器(包括未运行的),只显示 ...
- kubelet.service: Failed with result 'exit-code'.
检查kubelet服务状态 systemctl status kubelet 检查journal日志 journalctl 的 -u 参数可以指定服务进行过滤,这样可以屏蔽 ...
- 入口函数与包初始化:Go程序的执行次序
前言 我们可能经常会遇到这样一个问题:一个 Go 项目中有数十个 Go 包,每个包中又有若干常量.变量.各种函数和方法,那 Go 代码究竟是从哪里开始执行的呢?后续的执行顺序又是什么样的呢? 事实上, ...
- 查看Linux防火墙状态
环境:VMware.CentOS8从centos7开始使用systemctl.firewalld来管理服务和程序,包括了service和chkconfig.防火墙状态:systemctl status ...
- 张高兴的大模型开发实战:(三)使用 LangGraph 为对话添加历史记录
目录 基础概念 环境搭建与配置 将对话历史存储至内存 将对话历史存储至 PostgreSQL 在构建聊天机器人时,对话历史记录是提升用户体验的核心功能之一,用户希望机器人能够记住之前的对话内容,从而避 ...
- String常见面试题
第一题:打印的结果是true还是false呢? 在之前我们就说过这题,执行s1时,检查字符串常量池,发现没有"abc",于是创建"abc",执行s2时,接着检查 ...
- datasnap的监督功能【3】-TCP链接监督功能
1.对于使用TCP/IP链接的客户端应用程序,是具有状态的.一直等到客户端完成服务请求后释放配置的资源.如何掉线了,那么服务器就是傻傻地等着,可能导致资源耗尽. 如何在服务端选择一个链接切断关闭之: ...