『Plotly实战指南』--布局进阶篇
在数据可视化领域,Plotly的子图布局是打造专业级仪表盘的核心武器。
当面对多维数据集时,合理的子图布局能显著提升多数据关联分析效率,让数据的呈现更加直观和美观。
本文将深入探讨Plotly中子图布局技巧,并结合代码实现与实际场景案例,介绍多子图组织方法的技巧。
多子图布局
网格布局
网格布局是Plotly中实现多子图排列的一种常见方式,通过make_subplots函数,我们可以轻松创建行列对齐的子图。
例如,设置rows=2, cols=3,就可以生成一个2行3列的子图网格,这种方式的好处是子图的尺寸会自动分配,
而且我们还可以通过horizontal_spacing和vertical_spacing参数来调整子图之间的水平和垂直间距,从而让整个布局更加紧凑和美观。
from plotly.subplots import make_subplots
import plotly.graph_objects as go
fig = make_subplots(rows=2, cols=3, horizontal_spacing=0.2, vertical_spacing=0.2)
fig.add_trace(go.Scatter(x=[1, 2, 3], y=[4, 5, 6]), row=1, col=1)
fig.add_trace(go.Scatter(x=[20, 30, 40], y=[50, 60, 70]), row=1, col=2)
fig.add_trace(go.Scatter(x=[300, 400, 500], y=[600, 700, 800]), row=1, col=3)
fig.add_trace(go.Scatter(x=[4000, 5000, 6000], y=[7000, 8000, 9000]), row=2, col=1)
fig.add_trace(
go.Scatter(x=[50000, 60000, 70000], y=[80000, 90000, 100000]), row=2, col=2
)
fig.add_trace(
go.Scatter(x=[600000, 700000, 800000], y=[900000, 1000000, 1100000]), row=2, col=3
)
fig.show()
自由布局
自由布局则给予了我们更大的灵活性,通过domain参数,我们可以手动设置子图的位置,即指定子图在图表中的x和y坐标范围。
这种方式非常适合实现一些非对齐排列的子图布局,比如主图与缩略图的组合。
我们可以将主图放在较大的区域,而将缩略图放在角落,通过这种方式来辅助展示数据的局部细节。
# 自由布局
import plotly.graph_objects as go
# 自由布局示例
fig_free = go.Figure()
# 添加第一个子图
fig_free.add_trace(go.Scatter(x=[1, 2, 3], y=[4, 5, 6], name="Trace 1"))
# 添加第二个子图
fig_free.add_trace(go.Scatter(x=[20, 30, 40], y=[50, 60, 70], name="Trace 2"))
# 更新布局,定义每个子图的domain
fig_free.update_layout(
xaxis=dict(domain=[0, 0.7]), # 第一个子图占据左侧70%
yaxis=dict(domain=[0, 1]), # 第一个子图占据整个高度
xaxis2=dict(domain=[0.7, 1], anchor="y2"), # 第二个子图占据右侧30%
yaxis2=dict(domain=[0.5, 1], anchor="x2") # 第二个子图在右侧上方
)
# 更新每个trace的坐标轴引用
fig_free.update_traces(xaxis="x1", yaxis="y1", selector={"name": "Trace 1"})
fig_free.update_traces(xaxis="x2", yaxis="y2", selector={"name": "Trace 2"})
fig_free.show()
子图共享坐标轴
在多子图的情况下,共享坐标轴是一个非常实用的功能,通过设置shared_xaxes=True或shared_yaxes=True,可以让多个子图在同一个坐标轴上进行联动。
这样,当我们在一个子图上进行缩放或平移操作时,其他共享相同坐标轴的子图也会同步更新,从而方便我们进行多数据的对比分析。
此外,当遇到不同量纲的数据时,我们还可以通过secondary_y=True来独立控制次坐标轴,避免因量纲冲突而导致图表显示不清晰。
fig = make_subplots(
rows=2,
cols=1,
shared_xaxes=True,
specs=[[{"secondary_y": True}], [{}]],
)
fig.add_trace(go.Scatter(x=[1, 2, 3], y=[4, 5, 6]), row=1, col=1)
fig.add_trace(go.Scatter(x=[1, 2, 3], y=[40, 50, 60]), row=1, col=1, secondary_y=True)
fig.add_trace(go.Scatter(x=[1, 2, 3], y=[7, 8, 9]), row=2, col=1)
fig.show()
实战案例
下面两个案例根据实际情况简化而来,主要演示布局如何在实际项目中使用。
股票多指标分析仪表盘
示例中先构造一些模拟数据,然后采用3行1列的布局模式来显示不同的股票信息。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import pandas as pd
# 模拟股票数据
df = pd.DataFrame(
{
"date": pd.date_range(start="2023-01-01", periods=100),
"price": [100 + i * 0.5 + (i % 10) * 2 for i in range(100)],
"volume": [5000 + i * 10 + abs(i % 20 - 10) * 100 for i in range(100)],
"rsi": [50 + i % 15 - 7.5 for i in range(100)],
}
)
# 1. 创建3行1列的子图布局
fig = make_subplots(
rows=3,
cols=1,
shared_xaxes=True, # 共享x轴
vertical_spacing=0.05, # 子图间距
subplot_titles=("价格趋势", "成交量", "RSI 指标"),
)
# 2. 添加价格走势图
fig.add_trace(
go.Candlestick(
x=df["date"],
open=df["price"] * 0.99,
high=df["price"] * 1.02,
low=df["price"] * 0.98,
close=df["price"],
name="股票价格",
),
row=1,
col=1,
)
# 3. 添加成交量柱状图
fig.add_trace(
go.Bar(x=df["date"], y=df["volume"], name="成交量", marker_color="lightgray"),
row=2,
col=1,
)
# 4. 添加RSI指标图
fig.add_trace(
go.Scatter(x=df["date"], y=df["rsi"], name="RSI", line=dict(color="blue")),
row=3,
col=1,
)
# 5. 更新布局设置
fig.update_layout(
title_text="多指标仪表盘",
height=800,
margin=dict(l=20, r=20, t=80, b=20),
# 主图坐标轴配置
xaxis=dict(domain=[0, 1], rangeslider_visible=False),
# 成交量图坐标轴
xaxis2=dict(domain=[0, 1], matches="x"),
# RSI图坐标轴
xaxis3=dict(domain=[0, 1], matches="x"),
# 公共y轴配置
yaxis=dict(domain=[0.7, 1], showticklabels=False),
yaxis2=dict(domain=[0.35, 0.65], showticklabels=False),
yaxis3=dict(domain=[0, 0.3], tickformat=".0%"),
)
# 6. 添加形状标注
fig.add_shape(
type="line",
x0="2023-01-01",
y0=30,
x1="2023-04-10",
y1=70,
line=dict(color="red", width=2, dash="dash"),
)
fig.show()
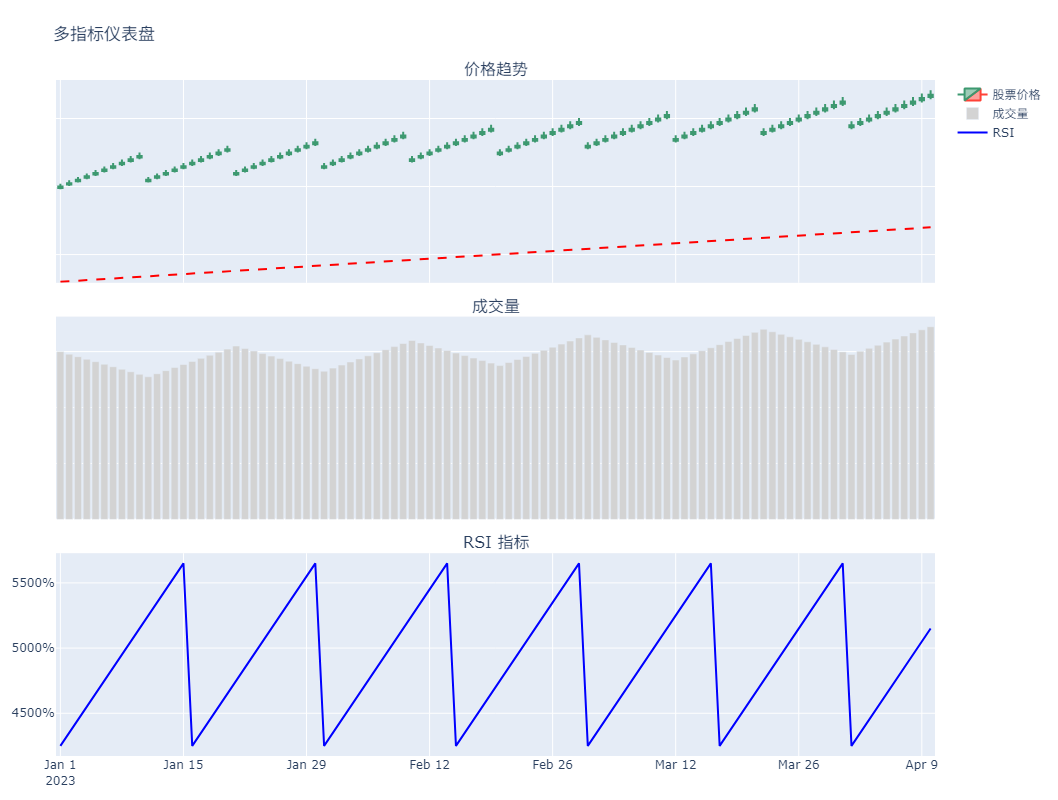
这是单列的布局,如果指标多的话,可以用多列的网格布局方式来布局。
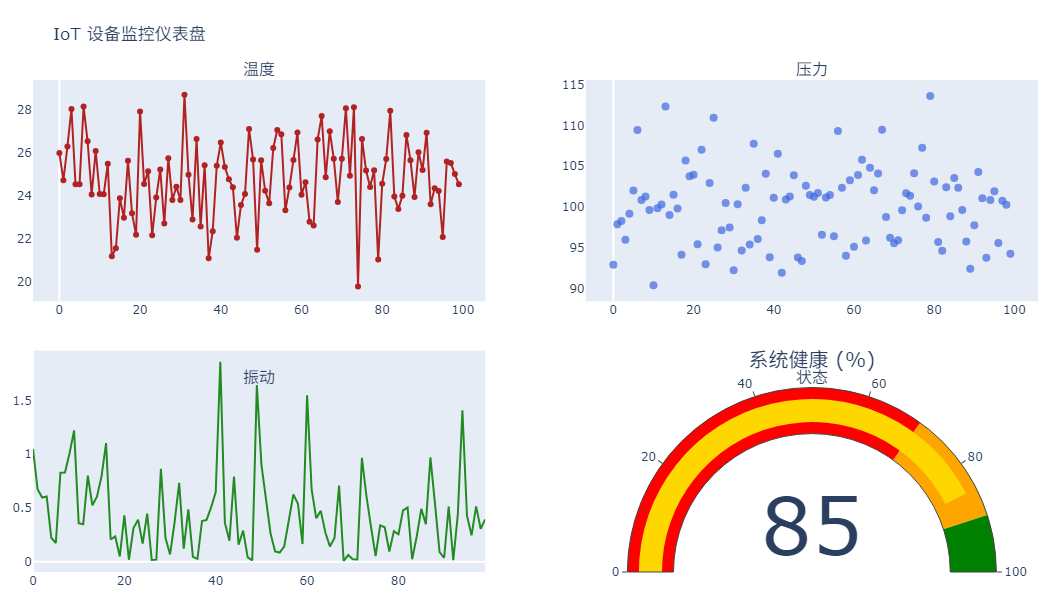
物联网设备状态监控
这个示例采用自由布局实现主监控图+4个状态指标环绕。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import numpy as np
# 模拟设备数据
np.random.seed(42)
device_data = {
"timestamp": np.arange(100),
"temp": 25 + np.random.normal(0, 2, 100),
"pressure": 100 + np.random.normal(0, 5, 100),
"vibration": np.random.exponential(0.5, 100),
}
# 1. 创建2行2列的子图布局
fig = make_subplots(
rows=2,
cols=2,
subplot_titles=("温度", "压力", "振动", "状态"),
specs=[
[{"type": "scatter"}, {"type": "scatter"}],
[{"type": "scatter"}, {"type": "indicator"}],
],
)
# 2. 添加温度折线图
fig.add_trace(
go.Scatter(
x=device_data["timestamp"],
y=device_data["temp"],
mode="lines+markers",
name="温度 (°C)",
line=dict(color="firebrick"),
),
row=1,
col=1,
)
# 3. 添加压力散点图
fig.add_trace(
go.Scatter(
x=device_data["timestamp"],
y=device_data["pressure"],
mode="markers",
name="压力 (kPa)",
marker=dict(size=8, color="royalblue", opacity=0.7),
),
row=1,
col=2,
)
# 4. 添加振动频谱图
fig.add_trace(
go.Scatter(
x=device_data["timestamp"],
y=device_data["vibration"],
mode="lines",
name="振动 (g)",
line=dict(color="forestgreen"),
),
row=2,
col=1,
)
# 5. 添加状态指示器
fig.add_trace(
go.Indicator(
mode="gauge+number",
value=85,
domain={"x": [0, 1], "y": [0, 1]},
title="系统健康 (%)",
gauge={
"axis": {"range": [0, 100]},
"bar": {"color": "gold"},
"steps": [
{"range": [0, 70], "color": "red"},
{"range": [70, 90], "color": "orange"},
{"range": [90, 100], "color": "green"},
],
},
),
row=2,
col=2,
)
# 6. 更新布局设置
fig.update_layout(
title_text="IoT 设备监控仪表盘",
height=600,
margin=dict(l=20, r=20, t=80, b=20),
showlegend=False,
# 温度图坐标轴
xaxis=dict(domain=[0, 0.45], showgrid=False),
yaxis=dict(domain=[0.55, 1], showgrid=False),
# 压力图坐标轴
xaxis2=dict(domain=[0.55, 1], showgrid=False),
yaxis2=dict(domain=[0.55, 1], showgrid=False),
# 振动图坐标轴
xaxis3=dict(domain=[0, 0.45], showgrid=False),
yaxis3=dict(domain=[0, 0.45], showgrid=False),
)
fig.show()
总结
在Plotly中,子图布局对于创建高质量的数据可视化作品至关重要。
在实际应用中,对于复杂的仪表盘项目,优先采用网格布局可以保证子图之间的对齐和一致性;而对于一些创意性的场景,自由布局则能够更好地发挥我们的想象力。
『Plotly实战指南』--布局进阶篇的更多相关文章
- 『Numpy学习指南』Matplotlib绘图
数据生成: import numpy as np import matplotlib.pyplot as plt func = np.poly1d(np.array([,,,])) func1 = f ...
- 『Numpy学习指南』排序&索引&抽取函数介绍
排序: numpy.lexsort(): numpy.lexsort()是个排字典序函数,因为很有意思,感觉也蛮有用的,所以单独列出来讲一下: 强调一点,本函数只接受一个参数! import nump ...
- Apache Beam实战指南 | 手把手教你玩转KafkaIO与Flink
https://mp.weixin.qq.com/s?__biz=MzU1NDA4NjU2MA==&mid=2247492538&idx=2&sn=9a2bd9fe2d7fd6 ...
- 【阿里云产品公测】以开发者角度看ACE服务『ACE应用构建指南』
作者:阿里云用户mr_wid ,z)NKt# @I6A9do 如果感觉该评测对您有所帮助, 欢迎投票给本文: UO<claV RsfTUb)< 投票标题: 28.[阿里云 ...
- Spring+SpringMVC+MyBatis整合进阶篇(四)RESTful实战(前端代码修改)
前言 前文<RESTful API实战笔记(接口设计及Java后端实现)>中介绍了RESTful中后端开发的实现,主要是接口地址修改和返回数据的格式及规范的修改,本文则简单介绍一下,RES ...
- Java多线程编程实战指南(核心篇)读书笔记(五)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76730459冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(四)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76690961冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(三)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76686044冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(二)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76651408冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
- Java多线程编程实战指南(核心篇)读书笔记(一)
(尊重劳动成果,转载请注明出处:http://blog.csdn.net/qq_25827845/article/details/76422930冷血之心的博客) 博主准备恶补一番Java高并发编程相 ...
随机推荐
- 近期最值得关注的AI技术报告与Agent综述!
写在前面 如题,近期优秀的大模型层出不穷.作为技术人,需要阅读高质量的AI技术报告或论文,并且掌握未来应用趋势.本文将推荐一些高质量的AI技术报告,以及Agent智能体综述. 大模型技术报告 Deep ...
- 部署Palworld幻兽帕鲁服务器最佳实践(Ubuntu)
本文为您介绍Ubuntu系统部署Palworld幻兽帕鲁服务器的最/佳实践. 1.登录云主机控制台,选择创建云主机的资源池,点击"创建云主机"按钮. 2.基础配置. CPU架构选择 ...
- acwing329 围栏障碍训练场 题解
考试压轴题,意识到这题是线段树优化 \(dp\) 时追悔莫及. 为了简化题目,我将从起点到原点变成了从原点到起点(这样就可以省去两个数组的空间). 想到设 \(dp_{i,j}\) 表示在第 \(i\ ...
- [HEOI2014]大工程 题解
发现可以直接建立虚树. 设 \(dp_{u,0/1/2}\) 表示第 \(u\) 个节点的子树内,所有选中节点到它的距离之和/选中节点中到它的最短距离/选中节点中到它的最长距离,\(as_{u,0/1 ...
- QT5笔记:9. QT的容器类
QList 中存放对象指针,QVector直接存放对象,所以访问性能更高 QMap中key不可以重复,QMultiMap中key可以重复 QMap在内存中顺序存储,QHash不是顺序存储的(hash算 ...
- 使用Go复刻skiplist核心功能
0.引言 正好做LC每日一题要求实现一个跳表,于是学习了redis的扩展skiplist,并使用Go进行复刻学习.学习参考了文章:Redis内部数据结构详解(6)--skiplist - 铁蕾的个人博 ...
- Docker 的基本概念和优势,以及在应用程序开发中的实际应用
Docker是一个开源的容器化平台,它可以将应用程序及其所有依赖关系打包为一个独立的容器,从而实现应用程序的快速部署.可移植性和可扩展性. Docker的基本概念包括以下几个方面: 镜像(Image) ...
- 淘宝 NPM 镜像站
应该有不少开发者已经发现,访问淘宝 NPM 已经会自动 301 跳转到 npmmirror.com 新域名,这是我们独立注册和备案的域名. Web 站点:https://npmmirror.com R ...
- Springboot 全局统一处理异常
import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.bind ...
- 面试题57. 和为s的两个数字
地址:https://leetcode-cn.com/problems/he-wei-sde-liang-ge-shu-zi-lcof/ <?php /** 面试题57. 和为s的两个数字 输入 ...