标签传播算法(llgc 或 lgc)
动手实践标签传播算法
复现论文:Learning with Local and Global Consistency[1]
lgc 算法可以参考:DecodePaper/notebook/lgc
初始化算法
载入一些必备的库:
from IPython.display import set_matplotlib_formats
%matplotlib inline
#set_matplotlib_formats('svg', 'pdf')
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import cdist
from sklearn.datasets import make_moons
save_dir = '../data/images'
创建一个简单的数据集
利用 make_moons 生成一个半月形数据集。
n = 800 # 样本数
n_labeled = 10 # 有标签样本数
X, Y = make_moons(n, shuffle=True, noise=0.1, random_state=1000)
X.shape, Y.shape
((800, 2), (800,))
def one_hot(Y, n_classes):
'''
对标签做 one_hot 编码
参数
=====
Y: 从 0 开始的标签
n_classes: 类别数
'''
out = Y[:, None] == np.arange(n_classes)
return out.astype(float)
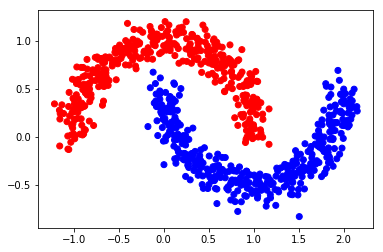
color = ['red' if l == 0 else 'blue' for l in Y]
plt.scatter(X[:, 0], X[:, 1], color=color)
plt.savefig(f"{save_dir}/bi_classification.pdf", format='pdf')
plt.show()
Y_input = np.concatenate((one_hot(Y[:n_labeled], 2), np.zeros((n-n_labeled, 2))))
算法过程:
Step 1: 创建相似度矩阵 W
def rbf(x, sigma):
return np.exp((-x)/(2* sigma**2))
sigma = 0.2
dm = cdist(X, X, 'euclidean')
W = rbf(dm, sigma)
np.fill_diagonal(W, 0) # 对角线全为 0
Step 2: 计算 S
\]
向量化编程:
def calculate_S(W):
d = np.sum(W, axis=1)
D_ = np.sqrt(d*d[:, np.newaxis]) # D_ 是 np.sqrt(np.dot(diag(D),diag(D)^T))
return np.divide(W, D_, where=D_ != 0)
S = calculate_S(W)
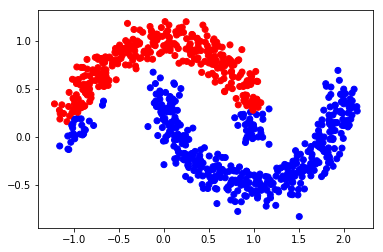
迭代一次的结果
alpha = 0.99
F = np.dot(S, Y_input)*alpha + (1-alpha)*Y_input
Y_result = np.zeros_like(F)
Y_result[np.arange(len(F)), F.argmax(1)] = 1
Y_v = [1 if x == 0 else 0 for x in Y_result[0:,0]]
color = ['red' if l == 0 else 'blue' for l in Y_v]
plt.scatter(X[0:,0], X[0:,1], color=color)
#plt.savefig("iter_1.pdf", format='pdf')
plt.show()
Step 3: 迭代 F "n_iter" 次直到收敛
n_iter = 150
F = Y_input
for t in range(n_iter):
F = np.dot(S, F)*alpha + (1-alpha)*Y_input
Step 4: 画出最终结果
Y_result = np.zeros_like(F)
Y_result[np.arange(len(F)), F.argmax(1)] = 1
Y_v = [1 if x == 0 else 0 for x in Y_result[0:,0]]
color = ['red' if l == 0 else 'blue' for l in Y_v]
plt.scatter(X[0:,0], X[0:,1], color=color)
#plt.savefig("iter_n.pdf", format='pdf')
plt.show()

from sklearn import metrics
print(metrics.classification_report(Y, F.argmax(1)))
acc = metrics.accuracy_score(Y, F.argmax(1))
print('准确度为',acc)
precision recall f1-score support
0 1.00 0.86 0.92 400
1 0.88 1.00 0.93 400
micro avg 0.93 0.93 0.93 800
macro avg 0.94 0.93 0.93 800
weighted avg 0.94 0.93 0.93 800
准确度为 0.92875
sklearn 实现 lgc
参考:https://scikit-learn.org/stable/modules/label_propagation.html
在 sklearn 里提供了两个 lgc 模型:LabelPropagation 和 LabelSpreading,其中后者是前者的正则化形式。\(W\) 的计算方式提供了 rbf 与 knn。
rbf核由参数gamma控制(\(\gamma=\frac{1}{2{\sigma}^2}\))knn核 由参数n_neighbors(近邻数)控制
def pred_lgc(X, Y, F, numLabels):
from sklearn import preprocessing
from sklearn.semi_supervised import LabelSpreading
cls = LabelSpreading(max_iter=150, kernel='rbf', gamma=0.003, alpha=.99)
# X.astype(float) 为了防止报错 "Numerical issues were encountered "
cls.fit(preprocessing.scale(X.astype(float)), F)
ind_unlabeled = np.arange(numLabels, len(X))
y_pred = cls.transduction_[ind_unlabeled]
y_true = Y[numLabels:].astype(y_pred.dtype)
return y_true, y_pred
Y_input = np.concatenate((Y[:n_labeled], -np.ones(n-n_labeled)))
y_true, y_pred = pred_lgc(X, Y, Y_input, n_labeled)
print(metrics.classification_report(Y, F.argmax(1)))
precision recall f1-score support
0 1.00 0.86 0.92 400
1 0.88 1.00 0.93 400
micro avg 0.93 0.93 0.93 800
macro avg 0.94 0.93 0.93 800
weighted avg 0.94 0.93 0.93 800
networkx 实现 lgc
参考:networkx.algorithms.node_classification.lgc.local_and_global_consistency 具体的细节,我还没有研究!先放一个简单的例子:
G = nx.path_graph(4)
G.node[0]['label'] = 'A'
G.node[3]['label'] = 'B'
G.nodes(data=True)
G.edges()
predicted = node_classification.local_and_global_consistency(G)
predicted
['A', 'A', 'B', 'B']
更多精彩内容见:DecodePaper 觉得有用,记得给个 star !(@DecodePaper)
Zhou D, Bousquet O, Lal T N, et al. Learning with Local and Global Consistency[C]. neural information processing systems, 2003: 321-328. ↩︎
标签传播算法(llgc 或 lgc)的更多相关文章
- 标签传播算法(Label Propagation)及Python实现
众所周知,机器学习可以大体分为三大类:监督学习.非监督学习和半监督学习.监督学习可以认为是我们有非常多的labeled标注数据来train一个模型,期待这个模型能学习到数据的分布,以期对未来没有见到的 ...
- 标签传播算法(Label Propagation Algorithm, LPA)初探
0. 社区划分简介 0x1:非重叠社区划分方法 在一个网络里面,每一个样本只能是属于一个社区的,那么这样的问题就称为非重叠社区划分. 在非重叠社区划分算法里面,有很多的方法: 1. 基于模块度优化的社 ...
- Label Propagation Algorithm LPA 标签传播算法解析及matlab代码实现
转载请注明出处:http://www.cnblogs.com/bethansy/p/6953625.html LPA算法的思路: 首先每个节点有一个自己特有的标签,节点会选择自己邻居中出现次数最多的标 ...
- lpa标签传播算法解说及代码实现
package lpa; import java.util.Arrays; import java.util.HashMap; import java.util.Map; public class L ...
- 神经网络训练中的Tricks之高效BP(反向传播算法)
神经网络训练中的Tricks之高效BP(反向传播算法) 神经网络训练中的Tricks之高效BP(反向传播算法) zouxy09@qq.com http://blog.csdn.net/zouxy09 ...
- (3)Deep Learning之神经网络和反向传播算法
往期回顾 在上一篇文章中,我们已经掌握了机器学习的基本套路,对模型.目标函数.优化算法这些概念有了一定程度的理解,而且已经会训练单个的感知器或者线性单元了.在这篇文章中,我们将把这些单独的单元按照一定 ...
- [2] TensorFlow 向前传播算法(forward-propagation)与反向传播算法(back-propagation)
TensorFlow Playground http://playground.tensorflow.org 帮助更好的理解,游乐场Playground可以实现可视化训练过程的工具 TensorFlo ...
- 反向传播算法 Backpropagation Algorithm
假设我们有一个固定样本集,它包含 个样例.我们可以用批量梯度下降法来求解神经网络.具体来讲,对于单个样例(x,y),其代价函数为:这是一个(二分之一的)方差代价函数.给定一个包含 个样例的数据集,我们 ...
- 神经网络之反向传播算法(BP)公式推导(超详细)
反向传播算法详细推导 反向传播(英语:Backpropagation,缩写为BP)是"误差反向传播"的简称,是一种与最优化方法(如梯度下降法)结合使用的,用来训练人工神经网络的常见 ...
随机推荐
- 洛谷P1280 尼克的任务
这个DP气死我了.....写的时候脑子比较迟钝于是爆0了好几次,最后还是我旁边的AKIOI巨佬告诉我解法才会做. 我一开始设计的状态是f[i]表示i时刻正在休息,从1到i的最长休息时间. 然后经历了各 ...
- (转)灵活控制 Hibernate 的日志或 SQL 输出,以便于诊断
背景:项目开发需要.之前对于hibernate日志输出,log4j的绑定,之间的关系一直不是很清楚.终于找到一篇介绍的很详细的文章. 文章出处:https://unmi.cc/hibernate-lo ...
- Codeforces 468C/469E 易错点
#include <stdio.h> #include <stdlib.h> typedef long long ll; int main() { ll x=1e17; ll ...
- Linux上防火墙开放对应的端口
在Linux上防火墙开放对应的端口的命令如下: 方式一: [root@localhost sbin]# /sbin/iptables -I INPUT -p tcp --dport 80 -j ACC ...
- NO.3: 尽量使用const
1.尽量使用const修饰不会赋值操作的变量,防止 "无意义行为" 2.const成员函数遵守: bitwise constness 法则(只要函数内部不改变成员变量的,都是允许c ...
- HDFS之append数据到已存在文件中
遇到一个问题,想往已存在的hdfs文件中直接添加数据,默认的话应该是被拒绝的.查看了一些资料,可以这样操作: 在pdfs-site.xml中添加append支持: <property> & ...
- oracle之回滚数据表 笔记
alter table [tableName] enable row movement;flashback table [tableName] to timestamp to_timestamp('2 ...
- webGL和three.js的关系
如今浏览器的功能越来越强大,而且这些功能可能通过JavaScript直接调用.你可以用HTML5标签轻松地添加音频和视频,而且可以在HTML5画布上创建各种交互组件.现在这个功能集合里又有了一个新成员 ...
- Spark记录-Scala数组/List/Map/Set
import Array._ import scala.collection.mutable.Set object DataStructure { def main(args:Array[String ...
- Spark记录-Scala变量/访问修饰符/运算符
变量是保存存储值的内存位置的名称.这意味着当创建变量时,可以在内存中保留一些空间. 根据变量的数据类型,编译器分配内存并决定可以存储在预留内存中的内容.因此,通过为变量分配不同的数据类型,可以在这些变 ...