Elasticsearch Java Rest Client API 整理总结 (二) —— SearchAPI
引言
在上一篇 中主要介绍了 Document API,本节中讲解 search API
Search APIs
Java High Level REST Client 支持下面的 Search API:
Search API
Search Request
searchRequest 用来完成和搜索文档,聚合,建议等相关的任何操作同时也提供了各种方式来完成对查询结果的高亮操作。
最基本的查询操作如下
SearchRequest searchRequest = new SearchRequest();
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchAllQuery()); // 添加 match_all 查询
searchRequest.source(searchSourceBuilder); // 将 SearchSourceBuilder 添加到 SeachRequest 中
可选参数
SearchRequest searchRequest = new SearchRequest("posts"); // 设置搜索的 index
searchRequest.types("doc"); // 设置搜索的 type
除了配置 index 和 type 外,还有一些其他的可选参数
searchRequest.routing("routing"); // 设置 routing 参数
searchRequest.preference("_local"); // 配置搜索时偏爱使用本地分片,默认是使用随机分片
什么是 routing 参数?
当索引一个文档的时候,文档会被存储在一个主分片上。在存储时一般都会有多个主分片。Elasticsearch 如何知道一个文档应该放置在哪个分片呢?这个过程是根据下面的这个公式来决定的:
shard = hash(routing) % number_of_primary_shards
routing是一个可变值,默认是文档的_id,也可以设置成一个自定义的值number_of_primary_shards是主分片数量
所有的文档 API 都接受一个叫做 routing 的路由参数,通过这个参数我们可以自定义文档到分片的映射。一个自定义的路由参数可以用来确保所有相关的文档——例如所有属于同一个用户的文档——都被存储到同一个分片中。
使用 SearchSourceBuilder
对搜索行为的配置可以使用 SearchSourceBuilder 来完成,来看一个实例
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); // 默认配置
sourceBuilder.query(QueryBuilders.termQuery("user", "kimchy")); // 设置搜索,可以是任何类型的 QueryBuilder
sourceBuilder.from(0); // 起始 index
sourceBuilder.size(5); // 大小 size
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // 设置搜索的超时时间
设置完成后,就可以添加到 SearchRequest 中。
SearchRequest searchRequest = new SearchRequest();
searchRequest.source(sourceBuilder);
构建查询条件
查询请求是通过使用 QueryBuilder 对象来完成的,并且支持 Query DSL。
DSL (domain-specific language) 领域特定语言,是指专注于某个应用程序领域的计算机语言。
— 百度百科
可以使用构造函数来创建 QueryBuilder
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("user", "kimchy");
QueryBuilder 创建后,就可以调用方法来配置它的查询选项:
matchQueryBuilder.fuzziness(Fuzziness.AUTO); // 模糊查询
matchQueryBuilder.prefixLength(3); // 前缀查询的长度
matchQueryBuilder.maxExpansions(10); // max expansion 选项,用来控制模糊查询
也可以使用QueryBuilders 工具类来创建 QueryBuilder 对象。这个类提供了函数式编程风格的各种方法用来快速创建 QueryBuilder 对象。
QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy")
.fuzziness(Fuzziness.AUTO)
.prefixLength(3)
.maxExpansions(10);
fuzzy-matching 拼写错误时的匹配:
好的全文检索不应该是完全相同的限定逻辑,相反,可以扩大范围来包括可能的匹配,从而根据相关性得分将更好的匹配放在前面。
例如,搜索
quick brown fox时会匹配一个包含fast brown foxes的文档
不论什么方式创建的 QueryBuilder ,最后都需要添加到 ``SearchSourceBuilder` 中
searchSourceBuilder.query(matchQueryBuilder);
构建查询 文档中提供了一个丰富的查询列表,里面包含各种查询对应的QueryBuilder 对象以及QueryBuilder helper 方法,大家可以去参考。
关于构建查询的内容会在下篇文章中讲解,敬请期待。
指定排序
SearchSourceBuilder 允许添加一个或多个SortBuilder 实例。这里包含 4 种特殊的实现, (Field-, Score-, GeoDistance- 和 ScriptSortBuilder)
sourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC)); // 根据分数 _score 降序排列 (默认行为)
sourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC)); // 根据 id 降序排列
过滤数据源
默认情况下,查询请求会返回文档的内容 _source ,当然我们也可以配置它。例如,禁止对 _source 的获取
sourceBuilder.fetchSource(false);
也可以使用通配符模式以更细的粒度包含或排除特定的字段:
String[] includeFields = new String[] {"title", "user", "innerObject.*"};
String[] excludeFields = new String[] {"_type"};
sourceBuilder.fetchSource(includeFields, excludeFields);
高亮请求
可以通过在 SearchSourceBuilder 上设置 HighlightBuilder 完成对结果的高亮,而且可以配置不同的字段具有不同的高亮行为。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle =
new HighlightBuilder.Field("title"); // title 字段高亮
highlightTitle.highlighterType("unified"); // 配置高亮类型
highlightBuilder.field(highlightTitle); // 添加到 builder
HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");
highlightBuilder.field(highlightUser);
searchSourceBuilder.highlighter(highlightBuilder);
聚合请求
要实现聚合请求分两步
- 创建合适的 ``AggregationBuilder`
- 作为参数配置在 ``SearchSourceBuilder` 上
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermsAggregationBuilder aggregation = AggregationBuilders.terms("by_company")
.field("company.keyword");
aggregation.subAggregation(AggregationBuilders.avg("average_age")
.field("age"));
searchSourceBuilder.aggregation(aggregation);
建议请求 Requesting Suggestions
SuggestionBuilder 实现类是由 SuggestBuilders 工厂类来创建的。
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
SuggestionBuilder termSuggestionBuilder =
SuggestBuilders.termSuggestion("user").text("kmichy");
SuggestBuilder suggestBuilder = new SuggestBuilder();
suggestBuilder.addSuggestion("suggest_user", termSuggestionBuilder);
searchSourceBuilder.suggest(suggestBuilder);
对请求和聚合分析
分析 API 可用来对一个特定的查询操作中的请求和聚合进行分析,此时要将SearchSourceBuilder 的 profile标志位设置为 true
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.profile(true);
只要 SearchRequest 执行完成,对应的 SearchResponse 响应中就会包含 分析结果
同步执行
同步执行是阻塞式的,只有结果返回后才能继续执行。
SearchResponse searchResponse = client.search(searchRequest);
异步执行
异步执行使用的是 listener 对结果进行处理。
ActionListener<SearchResponse> listener = new ActionListener<SearchResponse>() {
@Override
public void onResponse(SearchResponse searchResponse) {
// 查询成功
}
@Override
public void onFailure(Exception e) {
// 查询失败
}
};
查询响应 SearchResponse
查询执行完成后,会返回 SearchResponse 对象,并在对象中包含查询执行的细节和符合条件的文档集合。
归纳一下, SerchResponse 包含的信息如下
- 请求本身的信息,如 HTTP 状态码,执行时间,或者请求是否超时
RestStatus status = searchResponse.status(); // HTTP 状态码
TimeValue took = searchResponse.getTook(); // 查询占用的时间
Boolean terminatedEarly = searchResponse.isTerminatedEarly(); // 是否由于 SearchSourceBuilder 中设置 terminateAfter 而过早终止
boolean timedOut = searchResponse.isTimedOut(); // 是否超时
- 查询影响的分片数量的统计信息,成功和失败的分片
int totalShards = searchResponse.getTotalShards();
int successfulShards = searchResponse.getSuccessfulShards();
int failedShards = searchResponse.getFailedShards();
for (ShardSearchFailure failure : searchResponse.getShardFailures()) {
// failures should be handled here
}
检索 SearchHits
要访问返回的文档,首先要在响应中获取其中的 SearchHits
SearchHits hits = searchResponse.getHits();
SearchHits 中包含了所有命中的全局信息,如查询命中的数量或者最大分值:
long totalHits = hits.getTotalHits();
float maxScore = hits.getMaxScore();
查询的结果嵌套在 SearchHits 中,可以通过遍历循环获取
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
// do something with the SearchHit
}
SearchHit 提供了如 index , type, docId 和每个命中查询的分数
String index = hit.getIndex();
String type = hit.getType();
String id = hit.getId();
float score = hit.getScore();
而且,还可以获取到文档的源数据,以 JSON-String 形式或者 key-value map 对的形式。在 map 中,字段可以是普通类型,或者是列表类型,嵌套对象。
String sourceAsString = hit.getSourceAsString();
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
String documentTitle = (String) sourceAsMap.get("title");
List<Object> users = (List<Object>) sourceAsMap.get("user");
Map<String, Object> innerObject =
(Map<String, Object>) sourceAsMap.get("innerObject");
Search API 查询关系
上面的 QueryBuilder , SearchSourceBuilder 和 SearchRequest 之间都是嵌套关系,为此我专门整理了一个关系图,以便更清楚的确认它们之间的关系。感兴趣的同学可用此图与前面的 API 进行对应,以加深理解。
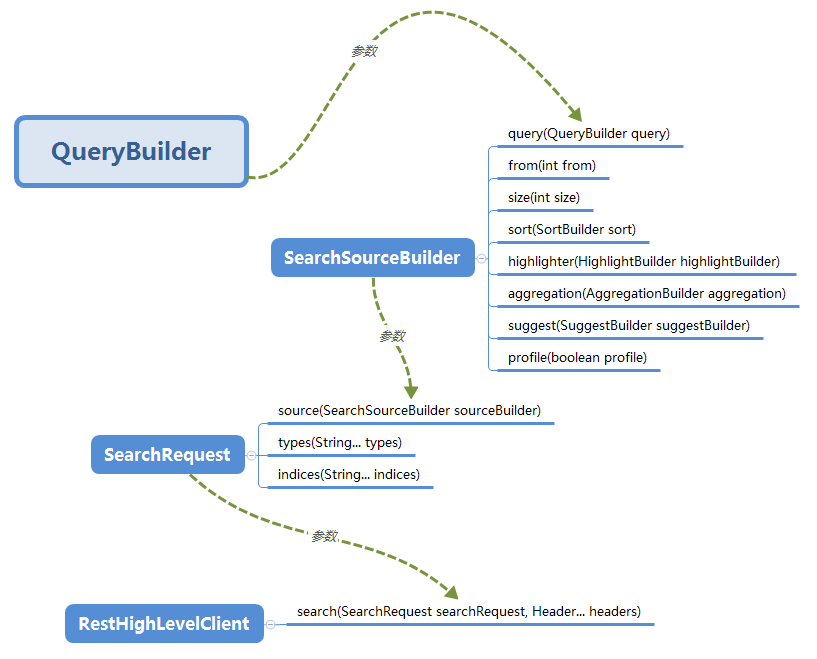
结语
本篇包含了 Java High level Rest Client 的 SearchAPI 部分,获取高亮,聚合,分析的结果并没有在本文涉及,需要的同学可参考官方文档,下篇会包含查询构建,敬请期待~
系列文章列表
- Elasticsearch Java Rest Client API 整理总结 (一)——Document API
- Elasticsearch Java Rest Client API 整理总结 (二) —— SearchAPI
- Elasticsearch Java Rest Client API 整理总结 (三)——Building Queries
Elasticsearch Java Rest Client API 整理总结 (二) —— SearchAPI的更多相关文章
- Elasticsearch Java Rest Client API 整理总结 (三)——Building Queries
目录 上篇回顾 Building Queries 匹配所有的查询 全文查询 Full Text Queries 什么是全文查询? Match 全文查询 API 列表 基于词项的查询 Term Term ...
- Elasticsearch Java Rest Client API 整理总结 (一)——Document API
目录 引言 概述 High REST Client 起步 兼容性 Java Doc 地址 Maven 配置 依赖 初始化 文档 API Index API GET API Exists API Del ...
- Elasticsearch Java Rest Client API 整理总结 (一)
http://www.likecs.com/default/index/show?id=39549
- java微信开发API解析(二)-获取消息和回复消息
java微信开发API解析(二)-获取消息和回复消息 说明 * 本演示样例依据微信开发文档:http://mp.weixin.qq.com/wiki/home/index.html最新版(4/3/20 ...
- Elasticsearch Java Rest Client简述
ESJavaClient的历史 JavaAPI Client 优势:基于transport进行数据访问,能够使用ES集群内部的性能特性,性能相对好 劣势:client版本需要和es集群版本一致,数据序 ...
- HTML5 <Audio/>标签Api整理(二)
1.实例2: 相对较完整 Html代码: <style> #volumeSlider .slider-selection { background:#bababa; } </styl ...
- HBase Client API使用(二)---查询及过滤器
相关知识 创建表插入数据删除等见:http://www.cnblogs.com/wishyouhappy/p/3735077.html HBase API简介见:http://www.cnblogs. ...
- Java REST Client API
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.3/java-rest-high-supported-apis.htm ...
- Java基础知识➣Stream整理(二)
概述 在Java数据流用到的流包括(Stream).文件(File流)和I/O流 ,利用该三个流操作数据的传输. Java控制台输入输出流 读取控制台使用数据流: BufferedReader和Inp ...
随机推荐
- svn目标计算机主动拒绝
这两天上传文件到服务器端,总是提示“ 目标计算机主动拒绝”. 后来排查,是受到360杀毒软件的文件系统实时防护功能影响. 虽然服务器端已经将仓库目录添加进360杀毒的白名单,但随着用户不断更新文件,文 ...
- Vue组件学习
根据Vue官方文档学习的笔记 在学习vue时,组件学习比较吃力,尤其是组件间的通信,所以总结一下,官方文档的组件部分. 注册组件 全局组件 语法如下,组件模板需要使用一个根标签包裹起来.data必须是 ...
- 巧用top percent优化top 1
废话不多说,直接上sql B.CREW_ID, E.CREW_NAME,C.OFFBLK,C.ONBLK,dbo.PEK_OPS_Date(A.STD) as STD FROM dbo.FLIGHTS ...
- [Linux|DBA]运维三十六计
这里是腾讯两位大神梁定安.周小军总记得运维DBA三十六计--
- ensp 路由器无法启动
出现错误代码 40.41等几乎都是虚拟机问题, 卸载干净后重新安装就好.推荐卸载软件:iobit uninstaller 安装注册后无法创建Host-Only,最好更换虚拟机版本, 我用的虚拟机版本是 ...
- 修改TEMPDB所在的路径
USE master go ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = 'Path\tempdb.mdf') go AL ...
- 折射向量计算(Refraction Vector Calculation)
上个月学习Peter Shirley-Ray Tracing in One Weekend的系列三本书,收获真的很多.这个系列的书真的是手把手教你如何从零开始构建一个光线跟踪渲染器,对新手(像我)非常 ...
- 阿里八八Alpha阶段Scrum(4/12)
今日进度 叶文滔: 整合了一下已完成的界面设计,修复了一些BUG. 问题困难:制作多级悬浮按钮阻碍重重,首先是刚更新不久的Andriod Studio 3.0向前兼容性差,一些语句规则的修改无所适从, ...
- PHP生成有背景的二维码图,摘自网络
有一天产品MM高高兴兴的走过来,兴奋的和我分享她想出来的一个新的idea. 产品MM:你看这个(她指了指她的手机),一脸兴奋 那是一张带着二维码的图片,内容如下: 她接着说:如果我们的分销也能做成类似 ...
- Linux备份压缩命令
gzip 命令 把/home/chenjialins目录下的familyA目录下所有文件压缩成.gz文件cd /home/chenjialinstar -cvf /home/chenjialins/f ...