flask 定义数据库关系(多对多)
多对多
我们使用学生和老师来演示多对多关系:每个学生有多个老师,每个老师有多个学生。多对多关系示意图如下:
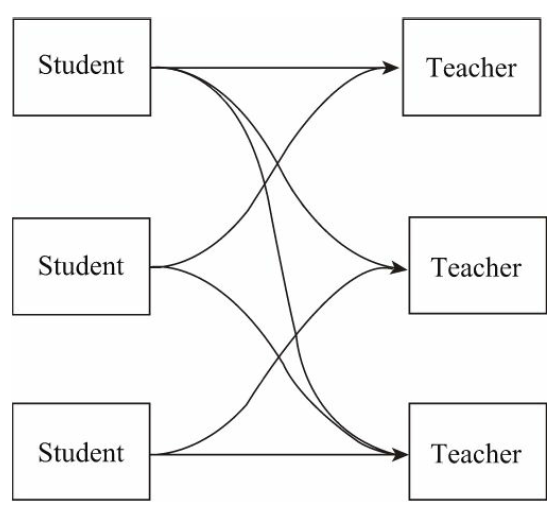
在实例程序中,Student类表示学生,Teacher类表示老师。在这两个模型之间建立多对多关系后,我们需要在Student类中添加一个集合关系属性teachers,调用它可以获取某个学生的多个老师,而不同的学生可以和同一个老师建立关系。
在一对一关系中,我们可以在“多”这一侧添加外键指向“一”这一侧,外键只能存储一个记录,但是在多个关系中,每一个记录都可以与关系另一侧的多个记录建立关系,关系两侧的模型都需要存储一组外键。在SQLAlchemy中,要想表示多对多关系,除了关系两侧的模型外,我们还需要创建一个关联表(association table)。关联表不存储数据,只用来存储关系两侧模型的外键对应关系。
app.py :建立多对多关系
association_table = db.Table('association',
db.Column('student_id', db.Integer, db.ForeignKey('student.id')),
db.Column('teacher_id', db.Integer, db.ForeignKey('teacher.id'))
)
class Student(db.Model):
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(70), unique = True)
grade = db.Column(db.String(20))
teachers = db.relationship('Teacher',
secondary = association_table,
back_populates = 'students') # collection
def __repr__(self):
return '<Student %r>' % self.name
class Teacher(db.Model):
id = db.Column(db.Integer, primary_key = True)
name = db.Column(db.String(70), unique = True)
office = db.Column(db.String(20))
#back_populates, 定义双向关系
# back_populates参数的值需要设为关系另一侧的关系属性名
students = db.relationship('Student',
secondary = association_table,
back_populates = 'teachers') # collection
关联表使用db.Table类定义,传入的第一个参数是关联表的名称。我们在关联表中定义了两个外键字段:teacher_id字段存储Teacher类的主键,student_id存储Student类的主键。借助关联表这个中间人存储的外键对,我们可以把对对多关系分化成两个一对多关系,如下所示:
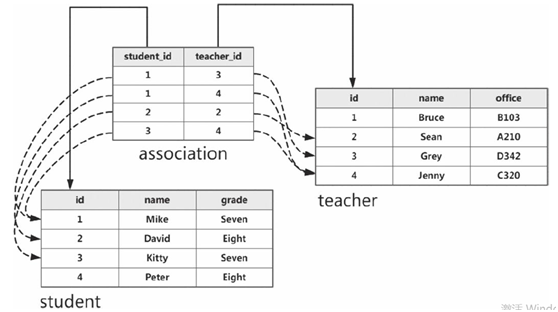
当我们需要查询某个学生记录的多个老师时,我们先通过学生和关联表的一对多关系查找多有包含该学生的关联表记录,然后后就可以从这些记录中再进一步获取每个关联表记录包含的老师记录。以上图的随机数据为例,假设学生记录的id为1,那么通过查找关联表中student_id字段为1的记录,就可以获取到对应的teacher_id值(分别为3和4),通过外键值就可以在teacher表里获取id为3和4的记录,最终,我们就获取到id为1的学生记录相关联的所有老师记录。
我们在Student类中定义一个teachers关系属性用来获取老师集合。在多对多关系中定义关系函数,除了第一个参数是关系另一侧的模型名称外,我们还需要添加一个secondary参数,把这个值设为关联的名称。
为了便于实现真正的多对多关系,我们需要建立双向关系。建立双向关系后,多对多关系会变得更加直观。在Student类上的teachers集合属性会返回所有关联的老师记录,而在Teacher类上的students集合属性会返回所有相关的学生记录
除了在声明关系时有所不同个,多对多关系模式在操作关系时和其他关系模式基本相同。调用关系属性student.teachers时,SQLAlchemy会直接返回关系另一侧的Teacher对象,而不是关联表记录,反之亦同。和其他关系模式中的结合关系属性一样,我们可以将关系属性teachers和students像列表一样操作。比如,当你需要为某一个学生添加老师时,对关系属性使用append()方法即可。如果你想要接触关系,那么可以使用remove()方法。
关联表有SQLAlchemy接管,它会帮我们管理这个表:我们只需要像往常一样通过操作关系属性来建立或解除关系,SQLAlchemy会自动在关联表中创建或删除对应的关联表记录,而不用手动操作关联表。
同样的,在多对多关系中我们也只需要在关系的一侧操作关系。当为学生A的teachers添加老师B后,调用老师B的students属性时返回的学生记录也会包含学生A,反之亦同。
>>> s1 = Student(name = 'xiaxiaoxu')
>>> t1 = Teacher(name = 'xufengchai')
>>> s2 = Student(name = 'xiayuze')
>>> t2 = Teacher(naem = 'xulei')
>>> t2 = Teacher(name = 'xulei')
>>> s1
<Student 'xiaxiaoxu'>
>>> s2
<Student 'xiayuze'>
>>> t1
<Teacher 'xufengchai'>
>>> t2
<Teacher 'xulei'>
>>> db.session.add(s1)
>>> db.session.add(s2)
>>> db.session.add(t1)
>>> db.session.add(t2)
>>> db.session.commit()
>>> s1.teachers
[]
>>> s1.teacher_id =1
>>> s2.teacher_id =2
>>> t1.student_id = 1
>>> t2.student_id = 2
>>> s1.teachers
[]
>>> db.session.commit()
>>> s1.teachers.append(t1)
>>> s1.teachers.append(t2)
>>> s1.teachers
[<Teacher u'xufengchai'>, <Teacher u'xulei'>]
>>> t1.students.append(s1)
>>> t1.students.append(s2)
>>> t1.students
[<Student u'xiaxiaoxu'>, <Student u'xiaxiaoxu'>, <Student u'xiayuze'>]
flask 定义数据库关系(多对多)的更多相关文章
- flask 定义数据库关系(一对多)
定义关系 在关系型数据库中,我们可以通过关系让不同表之间的字段建立联系.一般来说,定义关系需要两步,分别是创建外键和定义关系属性.在更复杂的多对多关系中,我们还需要定义关联表来管理关系.下面我们学习用 ...
- flask 定义数据库关系(一对一)
一对一 我们将使用国家和首都来演示一对一关系:每个国家只有一个首都.反过来,一个城市也只能作为一个国家的首都.一对一关系如下: 在示例程序中,Country类表示国家,Capital类表示首都.建立一 ...
- flask 定义数据关系(多对一)
多对一 一对多关系反过来就是多对一关系,这两种关系模式分别从不同的视角出发.一个作者拥有多篇文章,反过来就是多篇文章属于同一个作者.为了便于区分,我们使用居民和城市来演示多对一关系:多个居民住在同一个 ...
- day 69 orm操作之表关系,多对多,多对一(wusir总结官网的API)
对象 关系 模型 wusir博客地址orm官网API总结 django官网orm-API orm概要: ORM 跨表查询 class Book(models.Model): title = mod ...
- Flask之数据库设置
4 数据库 知识点 Flask-SQLALchemy安装 连接数据库 使用数据库 数据库迁移 邮件扩展 4.1 数据库的设置 Web应用中普遍使用的是关系模型的数据库,关系型数据库把所有的数据都存储在 ...
- 开始VS 2012 中LightSwitch系列的第2部分:感受关爱——定义数据关系
[原文发表地址] Beginning LightSwitch in VS 2012 Part 2: Feel the Love - Defining Data Relationships [原文发表 ...
- 库增删该查,表增删该查,记录增删该查,表与表关系(多对多,多对一,一对一),mysql用户管理
库增删该查 增加库 create database db1 create database db1 charset="gbk 查看库 show databases 查看所有库 show cr ...
- C++中重定义的问题——问题的实质是声明和定义的关系以及分离式编译的原理
这里的问题实质是我们在头文件中直接定义全局变量或者函数,却分别在主函数和对应的cpp文件中包含了两次,于是在编译的时候这个变量或者函数被定义了两次,问题就出现了,因此,我们应该形成一种编码风格,即: ...
- BI之SSAS完整实战教程6 -- 设计维度、细化维度上:创建维度定义特性关系
前面我们使用过数据源向导.数据源视图向导.Cube向导来创建相应的对象. 本篇我们将学习使用维度向导来创建维度. 通过前面几个向导的学习,我们归纳一下共同点,主要分成两步 1. 使用某种对象类型的向导 ...
随机推荐
- spark StructType的应用,用在处理mongoDB keyvalue
近期在处理mongoDB 数据的时候,遇到了非常奇怪的格式,账号密码的日志都追加在一条记录里面,要取一个密码的时长和所有密码的平均时长就非常繁琐. 用了各种迭代计算,非常困难,而且printschem ...
- ansible运维工具(一)
运维工具介绍 OS Provisioning: PXE, Cobbler(repository, distritution,profile) PXE: dhcp, tftp, (http, ftp) ...
- Java并发面试题
一.什么是线程? 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位.程序员可以通过它进行多处理器编程,你可以使用多线程对运算密集型任务提速.比如,如果一个线程完成一 ...
- MySQL 分页数据错乱重复
select xx from table_name wheere xxx order by 字段A limit offset;, 表数据总共 48 条,分页数量正常,但出现了结果混杂的情况,第一页的数 ...
- 管理菜单 结贴回复 来自 202.112.36.253 的回复: TTL 传输中过期
发表于 2010-08-26 18:29:14 楼主 其实标题是我执行如下命令时的输出:C:\Users\ChenWeiguang>ping 218.198.81.190 正在 Ping 218 ...
- 【CF434E】Furukawa Nagisa's Tree 点分治
[CF434E]Furukawa Nagisa's Tree 题意:一棵n个点的树,点有点权.定义$G(a,b)$表示:我们将树上从a走到b经过的点都拿出来,设这些点的点权分别为$z_0,z_1... ...
- WKWebView实现网页静态资源优先从本地加载
前言:最近微信的小游戏跳一跳特别的火,顺便也让h5小游戏更加的火热.另外微信小程序,以及支付宝的小程序都是用H5写的.无论是小游戏还是小程序,这些都需要加载更多的资源文件,处理更多的业务.这些都对网页 ...
- Spring MVC 知识点整理
extend:http://www.jianshu.com/p/bef0e52067d2 1. Redis 存储方式 Redis存储机制分成两种Snapshot 和 AOF.无论是那种机制,Redis ...
- python换行语法错误
a ={ ('住宅', 'https://auction.jd.com/getJudicatureList.html?callback=jQuery4392669&page=1&lim ...
- ExecuteExcel4Macro (宏函数)使用说明
用ExecuteExcel4Macro从未打开的Excel工作簿中读取数据(转载) 从另外一个未打开的Excel文件中读取数据的函数 下面这个函数调用XLM宏从未打开的工作簿中读取数据. *注意: ...