MySQL 8.0 新增SQL语法对窗口函数和CTE的支持
尝试了一下MySQL 8.0的部分新特性。
如果用过MSSQL或者是Oracle中的窗口函数(Oracle中叫分析函数),
然后再使用MySQL 8.0之前的时候,就知道需要在使用窗口函数处理逻辑的痛苦了,虽然纯SQL也能实现类似于窗口函数的功能,但是这种SQL在可读性和以及使用方式上大打折扣,看起来写起了都比较难受。
在MSSQL和Oracle以及PostgreSQL都已经完整支持窗口函数的情况下,MySQL 8.0中也加入了窗口函数的功能,这一点实实在在方便了sql的编码,可以说是MySQL8.0的亮点之一。
对于窗口函数,比如row_number(),rank(),dense_rank(),NTILE(),PERCENT_RANK()等等,在MSSQL和Oracle以及PostgreSQL,使用的语法和表达的逻辑,基本上完全一致。
这一点,几个数据库厂商做的还是比较统一的,如果熟悉任何一种关系数据中的窗口函数(分析函数),在MySQL 8.0之后就放心的用吧。
通过一个case来体验一下窗口函数的方便性,熟悉MSSQL或者Oracle或者PostgreSQL的老司机就不用看了。
测试case,简单模拟一个订单表,字段分别是订单号,用户编号,金额,创建时间
drop table if exists order_info create table order_info
(
order_id int primary key,
user_no varchar(10),
amount int,
create_date datetime
); insert into order_info values (1,'u0001',100,'2018-1-1');
insert into order_info values (2,'u0001',300,'2018-1-2');
insert into order_info values (3,'u0001',300,'2018-1-2');
insert into order_info values (4,'u0001',800,'2018-1-10');
insert into order_info values (5,'u0001',900,'2018-1-20'); insert into order_info values (6,'u0002',500,'2018-1-5');
insert into order_info values (7,'u0002',600,'2018-1-6');
insert into order_info values (8,'u0002',300,'2018-1-10');
insert into order_info values (9,'u0002',800,'2018-1-16');
insert into order_info values (10,'u0002',800,'2018-1-22');
要求sql查询求每个用户的最新的一个订单。
传统的方式,尽量格式化的好读一点的情况下,说实话,这句sql咋一看有点莫名其妙,不知所以。
SELECT * FROM
(
SELECT
IF(@y=a.user_no, @x:=@x+1, @x:=1) X ,
IF(@y=a.user_no, @y, @y:=a.user_no) Y,
a.*
FROM order_info a, (SELECT @x:=0, @y:=NULL) b
ORDER BY a.user_no, a.create_date desc
) a
WHERE X <= 1;
如下是执行结果,当然执行结果是可以满足需求的。
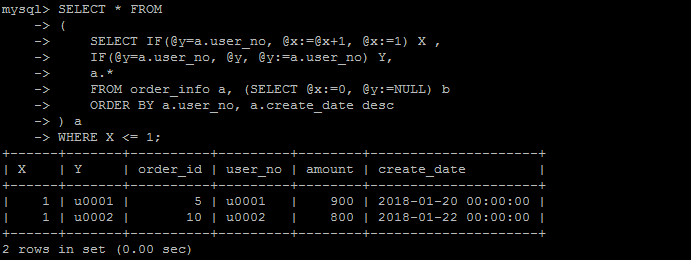
如果采用新的窗口函数的方法,
就是使用row_number()over(partition by user_no order by create_date desc) as row_num 给原始记录编一个号,
然后取第一个编号的数据,自然就是“用户的最新的一条订单”,实现逻辑上清晰了很多,代码也简洁,可读了很多。
select * from
(
select row_number()over(partition by user_no order by create_date desc) as row_num,
order_id,user_no,amount,create_date
from order_info
)t where row_num=1;

需要注意的是,MySQL中的使用窗口函数的时候,是不允许使用*的,必须显式指定每一个字段。
row_number()
(分组)排序编号,正如上面的例子, row_number()over(partition by user_no order by create_date desc) as row_num,按照用户分组,按照create_date排序,对已有数据生成一个编号。
当然也可以不分组,对整体进行排序。任何一个窗口函数,都可以分组统计或者不分组统计(也即可以不要partition by ***都可以,看你的需求了)
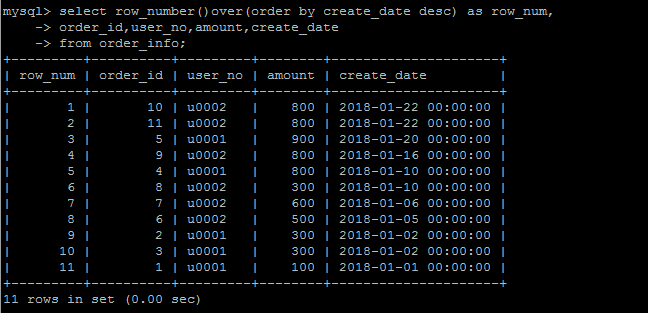
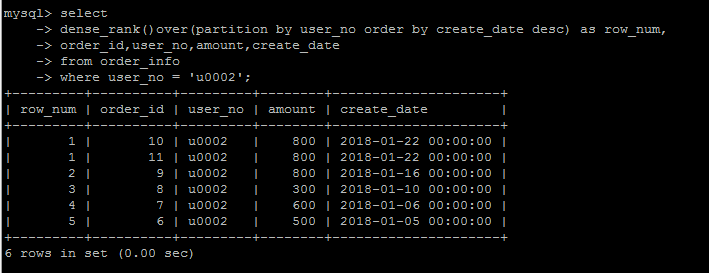
rank()
类似于 row_number(),也是排序功能,但是rank()有什么不一样?新的事物的出现必然是为了解决潜在的问题。
如果再往测试表中写入一条数据:insert into order_info values (11,'u0002',800,'2018-1-22');
对于测试表中的U002用户来说,有两条create_date完全一样的数据(假设有这样的数据),那么在row_number()编号的时候,这两条数据却被编了两个不同的号
理论上讲,这两条的数据的排名是并列最新的。因此rank()就是为了解决这个问题的,也即:排序条件一样的情况下,其编号也一样。
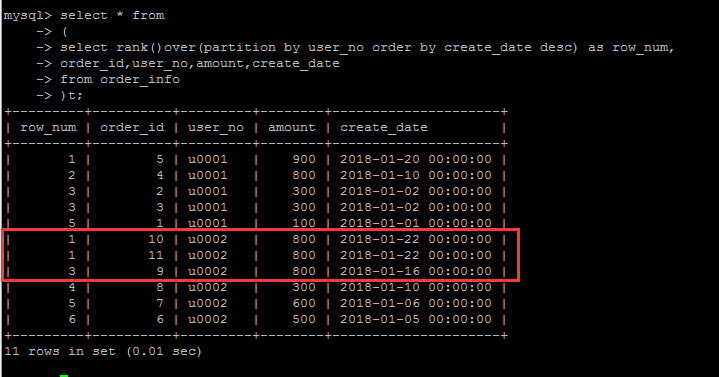
dense_rank()
dense_rank()的出现是为了解决rank()编号存在的问题的,
rank()编号的时候存在跳号的问题,如果有两个并列第1,那么下一个名次的编号就是3,结果就是没有编号为2的数据。
如果不想跳号,可以使用dense_rank()替代。
avg,sum等聚合函数在窗口函数中的的增强
可以在聚合函数中使用窗口功能,比如sum(amount)over(partition by user_no order by create_date) as sum_amont,达到一个累积计算sum的功能
这种需求在没有窗口函数的情况下,用纯sql写起来,也够蛋疼的了,就不举例了。

NTILE(N) 将数据按照某些排序分成N组
举个简单的例子,按照分数线的倒序排列,将学生成绩分成上中下3组,可以得到哪个程序数据上中下三个组中哪一部分,就可以使用NTILE(3) 来实现。这种需求倒是用的不是非常多。
如下还是使用上面的表,按照时间将user_no = 'u0002'的订单按照时间的纬度,划分为3组,看每一行数据数据哪一组。
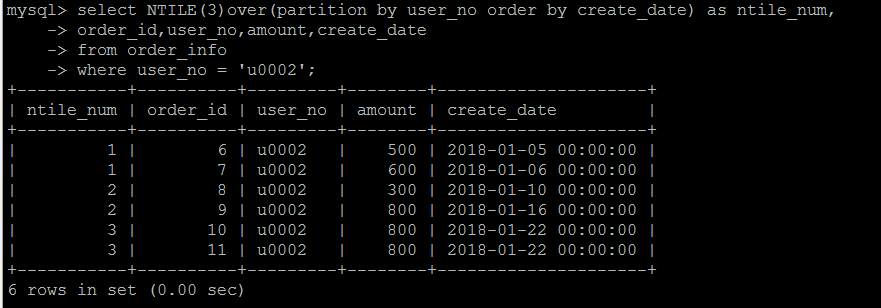
first_value(column_name) and last_value(column_name)
first_value和last_value基本上见名知意了,就是取某一组数据,按照某种方式排序的,最早的和最新的某一个字段的值。
看结果体会一下。
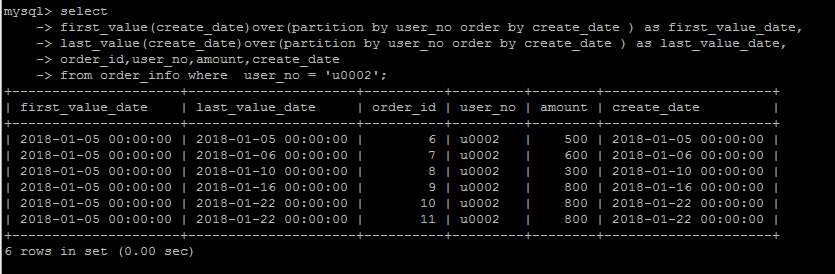
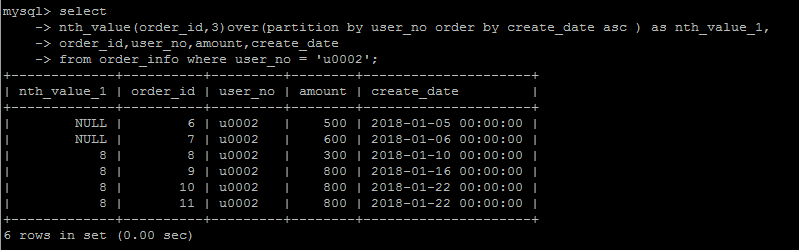
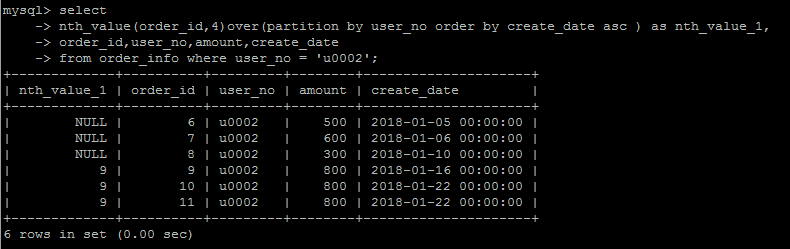
nth_value(column_name,n)
从排序的第n行还是返回nth_value字段中的值,这个函数用的不多,要表达的这种逻辑,说实话,很难用语言表达出来,看个例子体会一下就行。
n = 3
n = 4
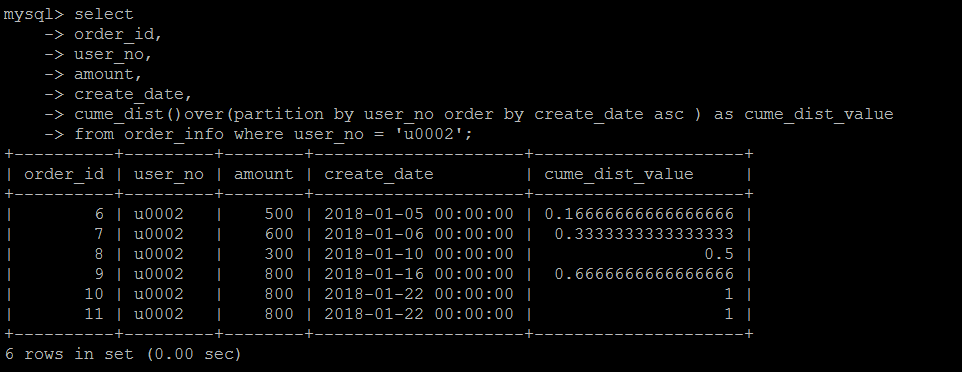
cume_dist
在某种排序条件下,小于等于当前行值的行数/总行数,得到的是数据在某一个纬度的分布百分比情况。
比如如下示例
第1行数据的日期(create_date)是2018-01-05 00:00:00,小于等于2018-01-05 00:00:00的数据是1行,计算方式是:1/6 = 0.166666666
第2行数据的日期(create_date)是2018-01-06 00:00:00,小于等于2018-01-06 00:00:00的数据是2行,计算方式是:2/6 = 0.333333333
依次类推
第4行数据的日期(create_date)是2018-01-16 00:00:00,小于等于2018-01-16 00:00:00的数据是4行,计算方式是:4/6 = 0.6666666666
第一行数据的0.6666666666 意味着,小于第四行日期(create_date)的数据占了符合条件数据的66.66666666666%
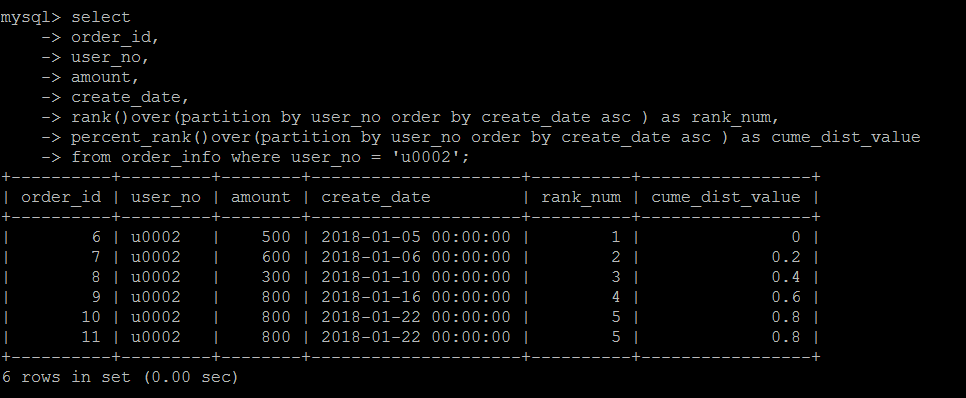
percent_rank()
同样是数据分布的计算方式,只不过算法变成了:当前RANK值-1/总行数-1 。
具体算法不细说,这个实际中用的也不多。
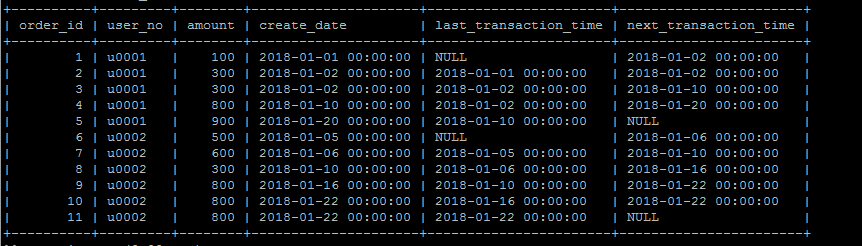
lag以及lead
lag(column,n)获取当前数据行按照某种排序规则的上n行数据的某个字段,lead(column,n)获取当前数据行按照某种排序规则的下n行数据的某个字段,
确实很拗口。
举个实际例子,按照时间排序,获取当前订单的上一笔订单发生时间和下一笔订单发生时间,(可以计算订单的时间上的间隔度或者说买买买的频繁程度)
select order_id,
user_no,
amount,
create_date,
lag(create_date,1) over (partition by user_no order by create_date asc) 'last_transaction_time',
lead(create_date,1) over (partition by user_no order by create_date asc) 'next_transaction_time'
from order_info ;
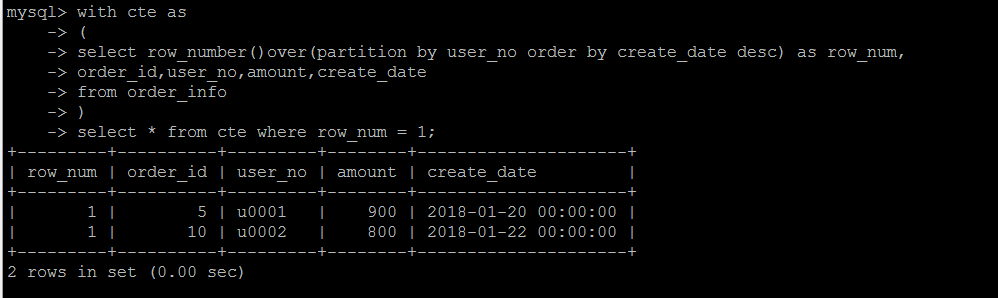
CTE 公用表表达式
CTE有两种用法,非递归的CTE和递归的CTE。
非递归的CTE可以用来增加代码的可读性,增加逻辑的结构化表达。
平时我们比较痛恨一句sql几十行甚至上上百行,根本不知道其要表达什么,难以理解,对于这种SQL,可以使用CTE分段解决,
比如逻辑块A做成一个CTE,逻辑块B做成一个CTE,然后在逻辑块A和逻辑块B的基础上继续进行查询,这样与直接一句代码实现整个查询,逻辑上就变得相对清晰直观。
举个简单的例子,当然这里也不足以说明问题,比如还是第一个需求,查询每个用户的最新一条订单
第一步是对用户的订单按照时间排序编号,做成一个CTE,第二步对上面的CTE查询,取行号等于1的数据。
另外一种是递归的CTE,递归的话,应用的场景也比较多,比如查询大部门下的子部门,每一个子部门下面的子部门等等,就需要使用递归的方式。
这里不做细节演示,仅演示一种递归的用法,用递归的方式生成连续日期。
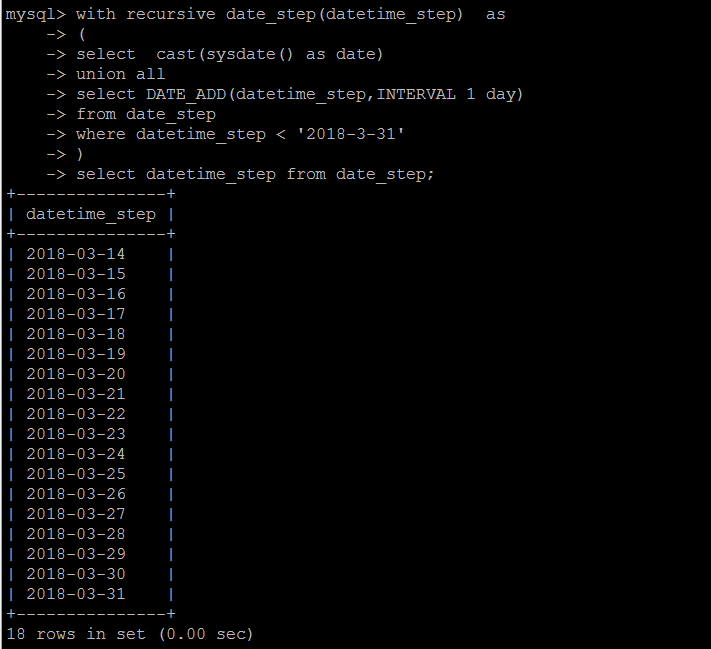
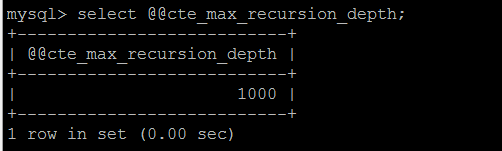
当然递归不会无限下去,不同的数据库有不同的递归限制,MySQL 8.0中默认限制的最大递归次数是1000。
超过最大低估次数会报错:Recursive query aborted after 1001 iterations. Try increasing @@cte_max_recursion_depth to a larger value.
由参数@@cte_max_recursion_depth决定。
关于CTE的限制,跟其他数据库并无太大差异,比如CTE内部的查询结果都要有字段名称,不允许连续对一个CTE多次查询等等,相信熟悉CTE的老司机都很清楚。
窗口函数和CTE的增加,简化了SQL代码的编写和逻辑的实现,并不是说没有这些新的特性,这些功能都无法实现,只是新特性的增加,可以用更优雅和可读性的方式来写SQL。
不过这都是在MySQL 8.0中实现的新功能,在8.0之前,还是老老实实按照较为复杂的方式实现吧。
MySQL 8.0 新增SQL语法对窗口函数和CTE的支持的更多相关文章
- [转]MySQL 最基本的SQL语法/语句
MySQL 最基本的SQL语法/语句,使用mysql的朋友可以参考下. DDL-数据定义语言(Create,Alter,Drop,DECLARE) DML-数据操纵语言(Select,Delete ...
- MySQL 8.0: From SQL Tables to JSON Documents (and back again)
MySQL 8.0: From SQL Tables to JSON Documents (and back again) | MySQL Server Bloghttps://mysqlserver ...
- MySQL的操作数据库SQL语法
MySQL的操作数据库SQL语法 顺序:操作数据库 > 操作数据库中的表 > 操作数据库中的表的数据 MySQL不区分大小写字母 1. 操作数据库 1.创建数据库 2.删除数据库 3.使用 ...
- MySQL prepare语句的SQL语法
MySQL prepare语法: PREPARE statement_name FROM preparable_SQL_statement; /*定义*/ EXECUTE statement_name ...
- 网络安全从入门到精通 (第二章-2) 后端基础SQL—MySQL数据库简介及SQL语法
本文内容: 什么是数据库 常见数据库 数据库的基本知识 基本SQL语法 1,什么是数据库? 数据库就是将大量数据保存起来,通过计算机加工,可以高效访问的数据聚合. 数据库就是长期存储在计算机内,有组织 ...
- MySQL 8.0新增特性详解【华为云技术分享】
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/devcloud/article/detai ...
- MySQL 最基本的SQL语法/语句
DDL—数据定义语言(Create,Alter,Drop,DECLARE) DML—数据操纵语言(Select,Delete,Update,Insert) DCL—数据控制语言(GRANT,REVOK ...
- MySQL与MongoDB之SQL语法对比
- MySQL 8.0 新特性梳理汇总
一 历史版本发布回顾 从上图可以看出,基本遵循 5+3+3 模式 5---GA发布后,5年 就停止通用常规的更新了(功能不再更新了): 3---企业版的,+3年功能不再更新了: 3 ---完全停止更新 ...
随机推荐
- 神州数码静态路由及直连网段引入到RIP协议配置(路由重定向)
实验要求:掌握静态路由及直连网段引入协议当中的配置 拓扑如下 R1 enable 进入特权模式 config 进入全局模式 hostname R1 修改名称 interface g0/6 进入端口 i ...
- PHP涉及的所有英文单词
PHP涉及的所有英文单词拦路虎 PHP再火,也会让一部同学心生畏惧,因为看到编辑器中那一串串英文单词,担心自己英文不好,从而对能学会PHP的决心产生动摇.其实大可不必,英文在学习PHP过程中真的连级别 ...
- Ubuntu下math库函数编译时未定义问题的解决
自己在Ubuntu下练习C程序时,用到了库函数math.h,虽然在源程序中已添加头文件“math.h”,但仍提示所用函数未定义,原本以为是程序出错了,找了好久,这是怎么回事呢? 后来上网查了下,发现是 ...
- document.ready(function(){}),window.onload,$(function(){})的区别
https://blog.csdn.net/qkzhx0516/article/details/79236514
- LeetCode - Maximum Frequency Stack
Implement FreqStack, a class which simulates the operation of a stack-like data structure. FreqStack ...
- MySQL Error--The Table is full
问题描述 在MySQL 错误日志中发下以下错误信息:[ERROR] /export/servers/mysql/bin/mysqld: The table '#sql-xxxx-xxx' is ful ...
- Linux内核分析第二次作业
这周学习了<庖丁解牛Linux内核分析>并且学习了实验楼的相关知识. 在实验楼的虚拟环境下编写代码: 通过gcc编译后,使用查看文件命令:cat -n 20189223.c 在vim中, ...
- 黄聪:什么是XSS攻击
XSS是一种经常出现在web应用中的计算机安全漏洞,它允许恶意web用户将代码植入到提供给其它用户使用的页面中.比如这些代码包括HTML代码和客户端脚本.攻击者利用XSS漏洞旁路掉访问控制——例如同源 ...
- Spring复习
第一天 IOC:控制反转,对象的创建权交给Spring DI:依赖注入,前提必须有IOC的环境,Spring管理这个类的时候将类的依赖的属性注入(设置)进来. 包括集合的注入 ClassPathXml ...
- [转]检测到有潜在危险的 Request.Form 值
<system.web> <httpRuntime targetFramework="4.0" requestValidationMode="2.0&q ...