大数据安全与RANGER学习和使用
概述
再说ranger之前需要明白一下大数据的安全体系的整体介绍,安全体系其实也就是权限可控,先说说权限:权限管理的目标,绝对不是简单的在技术层面建立起用户,密码和权限点的映射关系这么简单的事,更重要的是要从流程合理性,业务隔离,实施代价,可执行性等方面进行考虑。单方面强调安全,结果往往并不理想。重要的通过适度的安全管理手段,降低业务误操作的风险,结合业务流程和系统交互设计,实现业务的合理分隔,提高工作效率,同时将权限管理工作分级授权下放到业务负责人和团队,实现业务自治管理,明晰责任归属,让权限管理充分发挥其促进业务健康安全发展的作用,而不是相反。所以在实现过程中,要争取在可接受的安全范围内,保持相对较低的开发,管理和维护代价,做到真正有效的实施,否则再完美的系统也会因为人的因素而大打折扣。举个例子,比如美国的核弹发射密码箱,一天24小时由将军以上级别的专人随身携带看管,安全措施可谓严格了吧,但据坊间谣言传闻,由于害怕复杂的密码总统记不住,核弹发射安全箱的密码一度是8个0...
大数据的安全管控
权限的管控,历来是大数据平台中最让人头疼的问题之一。管得严了,业务不流畅,用户不开心,放得宽了,安全没有底,你能放心?而且大数据平台组件,服务众多;架构,流程复杂,有时候,就是你想管,也未必能管得起来。
涉及到具体的技术方案层面,Kerberos,LDAP,Sentry,Ranger,Quota,ACL,包括各个组件自己的权限管控方案,这些话题,不是一小节的篇幅能够覆盖的,所以,不打算在这里详细讨论各种技术方案。
权限的管控,做多少,怎么做,花多少代价,取决于你的目标出发点,很多公司集成开发环境的权限管控目标:是对用户常规的业务行为范围进行限定,敏感数据的控制固然是一方面,但更重要的是对业务逻辑和流程的约束,通过减少用户不必要的权限,减小受害面,降低可能的业务风险,同时也便于明确用户的权责归属关系。
所以,还是让我们来谈一下权限管控的目标。我们的权限管控目标,是防君子不防小人。此话怎讲?权限管控,大家都知道,有两个步骤:认证(authentication)和授权(authorization)。前者鉴定身份,后者根据身份赋予权限。
常见开源方案
权限管理相关工作可以分为两部分内容:
一、管理用户身份,也就是用户身份认证(Authentication)
二、用户身份和权限的映射关系管理,也就是授权(Authorization)
前者,用户身份认证这一环节,在Hadoop生态系中常见的开源解决方案是 Kerberos+LDAP,而后者授权环节,常见的解决方案有Ranger,Sentry等,此外还有像knox这种走Gateway代理服务的方案。
下面简单介绍一下这些开源项目,目的不是为了讲解这些方案的实现原理,而是从整体架构流程的角度来看看他们的目标问题和解决思想,以及适用场景等,这样当你在选择或者开发适合自己平台的权限管理方案时,也可以做到知其然,知其所以然。
至于Hadoop生态系的各个组件比如HDFS/Hive/HBase自身的权限管理模型,针对的是单一的具体组件,也是权限管控体系中的重要组成部分,但限于篇幅原因,本文就不加以讨论了。
kerberos
Kerberos是Hadoop生态系中应用最广的集中式统一用户认证管理框架。
工作流程 简单的来说,就是提供一个集中式的身份验证服务器,各种后台服务并不直接认证用户的身份,而是通过Kerberos这个第三方服务来认证。用户的身份和秘码信息在Kerberos服务框架中统一管理。这样各种后台服务就不需要自己管理这些信息并进行认证了,用户也不需要在多个系统上登记自己的身份和密码信息。
原理 用户的身份首先通过密码向Kerberos服务器进行验证,验证后的有效性会在用户本地保留一段时间,这样不要用户每次连接某个后台服务时都需要输入密码。 然后,用户向Kerberos申请具体服务的服务秘钥,Kerberos会把连接服务所需信息和用户自身的信息加密返回给用户,而这里面用户自身信息进一步是用对应的后台服务的秘钥进行加密的,由于这个后台服务的秘钥用户并不知晓,所以用户也就不能伪装或篡改这个信息。 然后,用户将这部分信息转发给具体的后台服务器,后台服务器接收到这个信息后,用自己的秘钥解密得到经过Kerberos服务认证过的用户信息,再和发送给他这个信息的用户进行比较,如果一致,就可以认为用户的身份是真实的,可以为其服务。
核心思想 Kerberos最核心的思想是基于秘钥的共识,有且只有中心服务器知道所有的用户和服务的秘钥信息,如果你信任中心服务器,那么你就可以信任中心服务器给出的认证结果。
很重要的一点 从流程上来说,Kerberos不光验证的用户真实性,实际上也验证了后台服务的真实性, 所以他的身份认证是双向认证,后台服务同样是通过用户,密码的形式登记到系统中的,避免恶意伪装的钓鱼服务骗取用户信息的可能性。
应用Kerberos的难点 Kerberos从原理上来说很健全,但是实现和实施起来是很繁琐的。 1、首先所有的后台服务必须针对性的接入Kerberos的框架,其次所有的客户端也必须进行适配,如果具体的后台服务提供对应的客户端接入封装SDK自然OK,如果没有,客户端还需要自己改造以适配Kerberos的认证流程。 2、其次,用户身份的认证要真正落地,就需要实现业务全链路的完整认证和传递。如果是客户端直连单个服务,问题并不大,但是在大数据平台服务分层代理,集群多节点部署的场景下,需要做用户身份认证的链路串联就没那么简单了。 3、举个例子,如果用户通过开发平台提交一个Hive脚本任务,该任务首先被开发平台提交给调度系统,再由调度系统提交给Hive Server,Hive Server再提交到hadoop集群上执行。那么用户信息就可能要通过开发平台-->调度系统Master节点--->调度系统Worker节点-->Hive Server-->Hadoop 这几个环节进行传递,每个上游组件都需要向下游组件进行用户身份认证工作。 4、就算到了具体的后台服务内部。比如在Hadoop集群上运行的一个MR任务,这个认证关系链还需要继续传递下去。首先客户端向Yarn的RM节点提交任务,客户端需要和RM节点双向验证身份,然后RM将任务分配给NM节点启动运行,RM就需要把用户身份信息传给NM(因为NM节点上启动的任务会需要以用户的身份去读取HDFS数据)在NM节点上的任务以用户的身份连接HDFS NameNode获取元数据以后,下一步还需要从HDFS Datanode节点读取数据,也就再次需要验证用户身份信息。 上述的每个环节如果要支持基于Kerberos的身份验证,要么要正确处理秘钥的传递,要么要实现用户的代理机制。而这两者,实施起来难度都不小,也会带来一些业务流程方面的约束。 5、雪上加霜的是,这个过程中,还要考虑身份验证的超时问题,秘钥信息的保管和保密问题等等,比如MR任务跑到一半秘钥或Token过期了该怎么办,总不能中断任务吧? 所以一套完整的链路实现起来绝非易事,这也是很多开源系统迟迟没有能够支持Kerberos的原因之一,而自己要在上层业务链路上完整的传递用户身份信息,也会遇到同样的问题。 6、最后是性能问题,集中式管理在某种程度上意味着单点,如果每次RPC请求都要完整的走完Kerberos用户认证的流程,响应延迟,并发和吞吐能力都会是个比较大的问题,所以比如Hadoop的实现,内部采用了各种Token和cache机制来减少对Kerberos服务的请求和依赖,并不是每一个环节步骤都通过Kerberos进行验证。
小结 总体来说,Kerberos是当前最有效最完善的统一身份认证框架,但是如果真的要全面实施,代价也很高,而从安全的角度来考虑,如果真的要防止恶意破坏的行为,在整个生产环境流程中,能被突破的环节其实也很多,光上Kerberos并不意味着就解决了问题,所以各大互联网公司用还是不用Kerberos,大家并没有一致的做法,即使All in Kerberos的公司,我敢说,除非完全不做服务化的工作,否则,整体链路方面也一定存在很多并不那么Kerberos的环节 ;)
最后,用户身份认证只是权限管理环节中很小的一部分,虽然技术难度大,但是从实际影响来看,合理的权限模型和规范的管理流程,通常才是数据安全的关键所在。所以,上不上Kerberos需要结合你的实际场景和安全需求加以考量。
Sentry和Ranger
Sentry和Ranger的目标都是统一的授权管理框架/平台,不光目标,这两个项目在思想和架构方面也大同小异,那么为什么会有两套如此类似的系统?当然是因为Cloudera和Hortonworks两家互相不鸟,必须各搞一套呗,目前看起来,Sentry借CDH用户基数大的东风,普通用户比较容易接受,但Ranger在功能完整性方面似乎略微占点上风。
相比用户身份认证,授权这件事情和具体服务的业务逻辑关联性就大多了,如果是纯SQL交互的系统,通过解析脚本等方式,从外部去管理授权行为有时是可行的,其它情况,通常都要侵入到具体服务的内部逻辑中才有可能实现权限的控制逻辑。
所以Sentry和Ranger都是通过Hook具体后台服务的流程框架,深度侵入代码,添加授权验证逻辑的方式来实现权限管控的,只不过具体的权限管理相关数据的存储,查询,管理工作实际是对接到外部独立的系统中承接实现的,进而实现各种存储计算集群权限的统一管理。
要Hook具体后台服务的流程框架,最理想的是原系统本身就提供插件式的权限管理方案可供扩展,否则就需要对原系统进行针对性的改造,另外各个系统自身既有的权限模型也未必能满足或匹配Sentry和Ranger所定义的统一权限管理模型,是否能改造本身就是个问题。
加上权限验证流程通过查询外部服务实现,因此在权限的同步,对原系统的性能影响等方面常常也需要小心处理或者针对性的优化。因此,统一的授权管理平台这一目标也是一个浩大的工程。所以至今无论Sentry还是Ranger都未能全面覆盖Hadoop生态系中常见的计算存储框架。
小结 总体来说,授权这件事,Hadoop生态系中的各个组件往往会有自己独立的解决方案,但是各自方案之间的连通性并不好。而统一的授权管理框架/平台的目标就是解决这个问题,但它们当前也不算很成熟,特别是在开放性和定制性上,往往也有一定局限性。
当然,要用一个框架彻底打通所有组件的权限管理工作,除了插件化,其它其实也没有特别好的方式,而插件化自然需要框架和具体组件的双向合作努力。只能说就当前发展阶段而言,这一整套方案尚未足够成熟,没到完美的程度,也没有事实统一的标准。所以无论是Sentry还是Ranger,当前的实现如果刚好适合你的需求自然最好,如果不适合,那还需要自己再想办法,且看他们将来的发展吧。
但是先对来说好多公司选择了ranger,原因如下:
多组件支持(HDFS,HBASE,HIVE,YARN,KAFKA,STORM),基本覆盖我们现有技术栈的组件
支持审计日志,可以很好的查找到哪个用户在哪台机器上提交的任务明细,方便问题排查反馈
拥有自己的用户体系,可以去除kerberos用户体系,方便和其他系统集成,同时提供各类接口可以调用
综上:我们考虑到和开放平台的集成,以及我们的技术栈和集群操作的审计等几个问题最终选用了apache ranger
Knox
最后来说一下Knox项目,它的思想是通过对Hadoop生态系的组件提供GateWay的形式来加强安全管控,你可以近似的认为他就是一个Rest/HTTP的服务代理/防火墙。
所有用户对集群的Rest/HTTP请求都通过Knox代理转发,既然是代理,那么就可以在转发的过程中做一些身份认证,权限验证管理的工作,因为只针对Rest/HTTP服务,所以他并不是一个完整的权限管理框架
使用Gateway的模式有很大的局限性,比如单点,性能,流程等等,不过对于Rest/HTTP的场景倒也算是匹配。它的优势是通过收拢Hadoop相关服务的入口,可以隐藏Hadoop集群的拓扑逻辑,另外,对于自身不支持权限认证管理的服务,通过Gateway也能自行叠加一层权限管控。
常见的权限模型
开源项目中常见的权限模型概念:RBAC / ACL / POSIX / SQL Standard 首先来看RBAC模型,RBAC从标准规范的角度来看,绝对是一个复杂的标准,但是实际情况下,各种开源系统在讨论RBAC的时候,通常重点指的就是权限和用户之间需要通过角色的概念进行一次二次映射,目的是为了对同类权限或同类用户进行归类,减少需要维护的映射关系的数量。至于RBAC理论层面上各种层级的约束,条件,规范等等,其实谈得很少。
而在其它模型中,也或多或少有组/角色的概念,只是比如:组的涵盖范围,是否允许存在多重归属,能否交叉,能否嵌套,是否允许用户和权限直接挂钩等具体规则上有所区别。不过基本上,如果你要宣称自己是一个RBAC模型的话,那么基本上还是要重点强调角色模型和映射关系的建设。而在其它模型中,组/角色的概念相对来说可能并没有那么突出或者重要。
然后谈POSIX的权限模型,谈这个,当然是因为HDFS的文件权限模型,很长一段时间以来,只支持POSIX标准文件的权限管理模型,即一个文件对应一个OWNER和一个GROUP,对OWNER和GROUP以及其它用户配置RWAC这样的读写通过管理等权限。
POSIX模型很直白,很容易理解,实现也简单,但POSIX模型最大的问题是文件的共享很难处理。因为要将权限赋予一拨人,只能通过单一固定的组的概念,你无法针对不同的人群和不同的文件进行分组授权,所以很难做到精细化的授权管理。
为了解决权限多映射精细管理问题,HDFS又引入了ACL模型,Access Control List,故名思意,就是针对访问对象,有一个授权列表。那么对不同对象给不同用户赋予不同的权限也就不成问题了。当然,HDFS的ACL模型也不是范本,事实上各种系统中所谓的ACL模型,具体设计都不尽相同,唯一可能共通的地方就是:对访问对象赋予一个授权列表这个概念,而不是像POSIX这样固定分类的授权模式。
ACL模型理论上看起来很理想,但在HDFS集群这个具体场景中,麻烦的地方在于如果集群规模比较大,授权列表的数量可能是海量的,性能,空间和效率上都可能成为问题,而事实上,ACL对象精细化的管理也并不那么容易。当然这些也并不能算是ACL模型自身的问题,更多的是具体的实现和上层业务规划方面的问题。
最后所谓的SQL标准的权限模型,从模型的角度来说和ACL模型并没有什么本质的区别,只不过是在类SQL语法的系统中,模仿了Mysql等传统数据库中标准的授权语法来与用户进行交互。具体的实现例子,比如Hive Server2中支持的SQL标准授权模型。
再比较一下底层统一权限管控平台和基于开发平台进行边界权限管控的优缺点 首先,Ranger等方案,主要依托大数据组件自身的方案,Hook进执行流程中,所以管控得比较彻底,而开发平台边界权限管控,前提是需要收拢使用入口,所以论绝对安全性,如果入口收不住,那么不如前者来得彻底。不过通常来说,为用户提供统一的服务入口,不光是安全的需要,也是开发平台提高自身服务化程度和易用性的必要条件。
其次,底层权限统一管控平台,因为依托的是大数据组件自身的方案,并不收拢用户交互入口,所以身份认证环节还是需要依托类似Kerberos这样的系统来完成。而开发平台服务方式,收拢了入口,就可以用比较简单方式自行完成身份认证,如前所述,相比涉及到三方交互的分布式身份认证机制,通常实现代价会更低一些。
再次,大数据组件自身的权限方案,权限验证环节通常发生在任务实际执行的过程中,所以流程上基本都是在没有权限的时候抛出一个异常或返回错误,因此不太可能根据业务场景做更加灵活的处理。
而开发平台服务方式,权限的验证如果可以做到在执行前阶段(比如通过语法分析获得)进行,那么流程上就可以灵活很多,可以结合业务相关信息提供更丰富的调控手段。
例如,业务开发过程中,在代码编辑或保存时就可以进行相关权限验证和提示,避免在半夜任务实际执行时才发现问题。也可以定期批量审计脚本任务,或者根据业务重要程度对缺乏权限的情况进行区别对待:提示,警告,阻断等等。简单的说,就是你想怎么做就怎么做。而Ranger等基于底层组件进行Hook的权限架构方案,一来没有相关业务信息无法做出类似决策,二来考虑通用性,很多平台环境相关业务逻辑不可能也不适合绑定进来。
当然,这两种方案并不是互斥的,如何定义你的产品,如何拆分各种需求,对你选择权限管控方案也有很大的影响。更常见的情况是,你会需要一个混合体,取长补短,弥补各自的不足之处。
ranger简介
Apache Ranger提供集中式的权限管理框架,可以对Hadoop生态中的HDFS、Hive、YARN、Kafka、Storm和Solr等组件进行细粒度的权限访问控制,并且提供了Web UI方便管理员进行操作。

Ranger主要由三个组件组成:
Ranger Admin
用户可以创建、更新安全访问策略,这些策略被存储在数据库中。各个组件的Plugin定期对这些策略进行轮询。
Ranger Plugins
Plugin嵌入在各个集群组件的进程里,是一个轻量级的Java程序。例如,Ranger对Hive的组件,就被嵌入在Hiveserver2里。这些Plugin从Ranger Admin服务端拉取策略,并把它们存储在本地文件中。当接收到来自组件的用户请求时,对应组件的plugin会拦截该请求,并根据安全策略对其进行评估。
Ranger UserSync
Ranger提供了一个用户同步工具,可以从Unix或者LDAP中拉取用户和用户组的信息。这些用户和用户组的信息被存储在Ranger Admin的数据库中,可以在定义策略时使用。
ranger权限模型
访问权限无非是定义了”用户-资源-权限“这三者间的关系,Ranger基于策略来抽象这种关系,进而延伸出自己的权限模型。”用户-资源-权限”的含义详解:
用户
由User或Group来表达,User代表访问资源的用户,Group代表用户所属的用户组。
资源
不同的组件对应的业务资源是不一样的,比如
HDFS的FilePath
HBase的Table,Column-family,Column
Hive的Database,Table,Column
Yarn的对应的是Queue
权限
由(AllowACL, DenyACL)来表达,类似白名单和黑名单机制,AllowACL用来描述允许访问的情况,DenyACL用来描述拒绝访问的情况,不同的组件对应的权限也是不一样的。
ranger权限实现
Ranger-Admin职责:
管理员对于各服务策略进行规划,分配相应的资源给相应的用户或组,存储在db中
Service Plugin职责:
定期从RangerAdmin拉取策略
根据策略执行访问决策树
实时记录访问审计
策略执行过程:
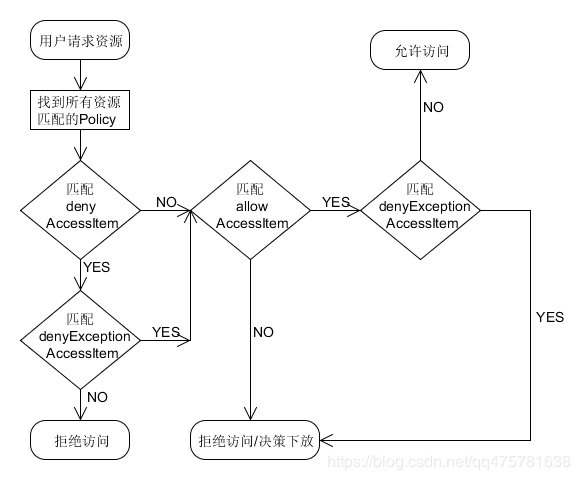
策略优先级:
黑名单优先级高于白名单
黑名单排除优先级高于黑名单
白名单排除优先级高于白名单
决策下放:
如果没有policy能决策访问,一般情况是认为没有权限拒绝访问,然而Ranger还可以选择将决策下放给系统自身的访问控制层
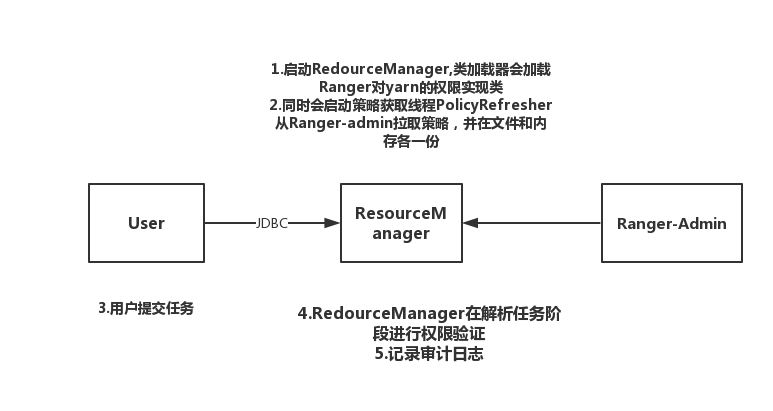
组件集成插件原理:

hdfs实现ranger

Hbase实现ranger

Hive实现ranger

Yarn实现ranger
总结
感谢网络大神的分享:
https://blog.csdn.net/qq475781638/article/details/90247153
https://www.jianshu.com/p/d9941b8687b7
https://www.jianshu.com/p/1efa56aec8e9
https://cloud.tencent.com/developer/article/1368183
大数据安全与RANGER学习和使用的更多相关文章
- 大数据安全利器ranger 编译安装
ranger大数据领域的一个集中式安全管理框架,它可以对诸如hdfs.hive.kafka.storm等组件进行细粒度的权限控制.本文将介绍部署过程 1. 部署准备 ranger: 进入apa ...
- 详解Linux运维工程师高级篇(大数据安全方向).
hadoop安全目录: kerberos(已发布) elasticsearch(已发布)http://blog.51cto.com/chenhao6/2113873 knox oozie ranger ...
- 星环大数据安全组件Guardian与hadoop自带的安全组件区别
在进行讲解之前,先带大家学习下hadoop关于hdfs自己的安全如何实现的--------------------------- 名词: ACL-访问控制列表(Access Control List, ...
- 【转】福利大放送--不止是Android,Github超高影响力开源大放送,学习开发必备教科书
[福利大放送]不止是Android,Github超高影响力开源大放送,学习开发必备教科书 目录 一.写在前面 1.free-programming-books 2.oh-my-zsh 3.awes ...
- Coursera台大机器学习基础课程学习笔记1 -- 机器学习定义及PLA算法
最近在跟台大的这个课程,觉得不错,想把学习笔记发出来跟大家分享下,有错误希望大家指正. 一机器学习是什么? 感觉和 Tom M. Mitchell的定义几乎一致, A computer program ...
- Coursera台大机器学习基础课程学习笔记2 -- 机器学习的分类
总体思路: 各种类型的机器学习分类 按照输出空间类型分Y 按照数据标记类型分yn 按照不同目标函数类型分f 按照不同的输入空间类型分X 按照输出空间类型Y,可以分为二元分类,多元分类,回归分析以及结构 ...
- 【福利大放送】不止是Android,Github超高影响力开源大放送,学习开发必备教科书
一.写在前面 最近项目重构,时间贼多,也没什么时间更新博客,个人的开源项目也是多时没有更新了:github地址,然而没有更新不代表我不在乎,后面一有空还是会继续提交的. 还是来冒个泡,给大家献上一些福 ...
- 【大数据安全】基于Kerberos的大数据安全验证方案
1.背景 互联网从来就不是一个安全的地方.很多时候我们过分依赖防火墙来解决安全的问题,不幸的是,防火墙是假设"坏人"是来自外部的,而真正具有破坏性的攻击事件都是往往都是来自于内部的 ...
- 【福利】送Spark大数据平台视频学习资料
没有套路真的是送!! 大家都知道,大数据行业spark很重要,那话我就不多说了,贴心的大叔给你找了份spark的资料. 多啰嗦两句,一个好的程序猿的基本素养是学习能力和自驱力.视频给了你们,能不能 ...
随机推荐
- 【死磕Java并发】—–深入分析volatile的实现原理
通过前面一章我们了解了synchronized是一个重量级的锁,虽然JVM对它做了很多优化,而下面介绍的volatile则是轻量级的synchronized.如果一个变量使用volatile,则它比使 ...
- 童鞋,[HttpClient发送文件] 的技术实践请查收
1.荒腔走板 前几天有个童鞋在群里面问:怎么使用HttpClient发送文件? 之前我写了一个ABP上传文件,主要体现的是服务端,上传文件的动作是由前端小姐姐完成的, 我还真没有用HttpClient ...
- HDD深圳站:全生命周期赋能开发者,华为引领应用生态升级
12月14日,由华为开发者联盟主办的HDD(HUAWEI Developer Day)于深圳举行.此次HDD主论坛,围绕打造应用全生命周期服务,介绍了华为在创新孵化.开发测试.应用分发和运营增长阶段的 ...
- time_formatter(uaf)
拿到题目先例行检查 然后进入主函数查看程序流程, 进入函数 这些字符串对我们选择1的输入进行了限制 在输入里面,可以看到strdup这个关键性的函数 调用了malloc这个函数 在选择四里面,可以看到 ...
- Google earth engine 中的投影、重采样、尺度
本文主要翻译自下述GEE官方帮助 https://developers.google.com/earth-engine/guides/scale https://developers.google.c ...
- CF1501A Alexey and Train 题解
Content 一列火车从 \(0\) 时刻开始从 \(1\) 号站出发,要经过 \(n\) 个站,第 \(i\) 个站的期望到达时间和离开时间分别为 \(a_i\) 和 \(b_i\),并且还有一个 ...
- windows 2008 server 服务器远程桌面连接会话自动注销,在服务器上开掉的软件全部自动关闭的解决办法
windows 2008 server 服务器远程桌面连接会话自动注销,在服务器上开掉的软件全部自动关闭的解决办法:
- 【九度OJ】题目1206:字符串连接 解题报告
[九度OJ]题目1206:字符串连接 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1206 题目描述: 不借用任何字符串库函数实现无 ...
- 【九度OJ】题目1203:IP地址 解题报告
[九度OJ]题目1203:IP地址 解题报告 标签(空格分隔): 九度OJ http://ac.jobdu.com/problem.php?pid=1203 题目描述: 输入一个ip地址串,判断是否合 ...
- 【LeetCode】863. All Nodes Distance K in Binary Tree 解题报告(Python)
[LeetCode]863. All Nodes Distance K in Binary Tree 解题报告(Python) 作者: 负雪明烛 id: fuxuemingzhu 个人博客: http ...