HBASE-使用问题-split region
问题描述:
HBASE表的管理以REGION分区为核心,通常面临如下几个问题:
1) 数据如何存储到指定的region分区,即rowkey设计,region splitkey设计
2)设计的splitkey是否可以解决热点问题
3)设计的splitkey是否可以解决均匀分布,避免自动分裂的问题
4)region的创建和删除问题
对于1)问题 比如:对于按照时间存储的数据,region splitkey 可以是2019,2020 ; 201901,201902;20190101 等等类似方式,可以把指定时间段的数据存储到响应splitkey的region中,达到按照时间存储的效果。
对于2)问题,同一天的数据,可以通过对rowkey或者数据中的一个或多个字段取hash方式,解决热点问题;如果数据存在重复入库,则需要保证用于hash的字段值在两次入库时不能变更,否则会存在两个rowkey数据 即splitkey中包含hash值部分,同样要求rowkey包含hash值
对于3)问题,需要考虑数据量和region分区的关系,比如一天有150G的数据量,hbase 单个region建议10~20G大小,设计时则需要考虑一天需要划分多少的region,才能避免region在数据入库时发生频繁split,会影响hbase服务(split会涉及数据移动,数据通过网络传输和落盘,影响网络和磁盘IO)
对于4)问题,未来的region是否应该提前创建,如何创建?集群存储是否足够,历史的region是否下线或者删除?
此篇文章是在提前创建region分区时遇到的问题
一般的设计方法是,在hbase 尾部region切分新的多个region,用于新的数据存储,通常使用定时任务,提前创建
切分方式是通过调用HBASE split region方法,region尾部splitkey为 20210600 ~“” 需要切分的splitkey为20210601,20210602,20210603,20210700
采用的方法是: 先20210601切分,得到如下两个region: 20210600 ~20210601, 20210601~“” 然后等待 20210601~“” 此region上线,再使用20210602切分
以此类推
但是在实际项目中发现,只切分了一个region就任务结束了,程序本身在等待新切分region上线时,可以等待1s~60秒中,发现此问题后,可以配置等待时长,
但是实际效果不好,仍会存在上述问题
1) 观察Hbase regionServer端日志,发现如下日志,debug日志显示待切分region对应的存储文件正在被引用使用,导致region split请求切分失败

2)分析Hbase 源码:

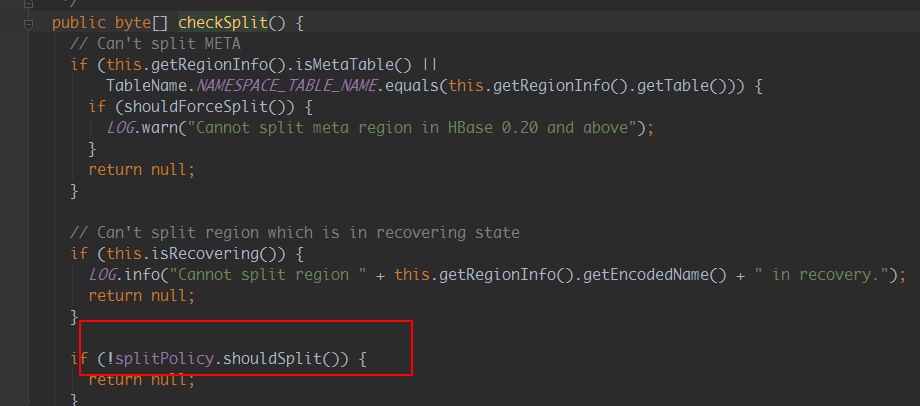
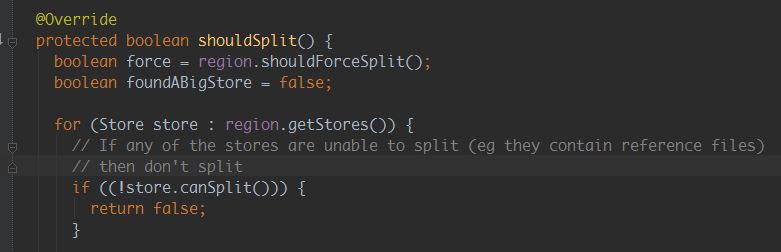
原因分析:hbase split请求调用的为异步请求,通过源码并结合hbase regionserver日志可以看出,hbase接收到split请求后,
如果发现需要被切分的region有引用文件时,就返回失败;因为时异步请求,所以程序等待新切分region上线不可行
即Hbase接收到请求后,由于存储文件被引用使用,导致请求失败,region未切分,索引新切分region不会上线,从而失败
修改后方法逻辑为:切分region,等待一段时间上线,不上线则再次切分region,以此多次,仍不成功,则等待下次定时任务触发切分
额外说明:
实际项目中被切分region如果里面有大量数据,切分速度会很快,但是对切分后的region再次切分时,文件引用有较长时间不会消失,无法再次切分
因此实际项目中考虑切分没有数据的尾部region为佳,此外重试切分的时间间隔建议可配置,以免region未及时切分,导致所有数据存入到尾部一个region中
HBASE-使用问题-split region的更多相关文章
- Spark读Hbase优化 --手动划分region提高并行数
一. Hbase的region 我们先简单介绍下Hbase的架构和Hbase的region: 从物理集群的角度看,Hbase集群中,由一个Hmaster管理多个HRegionServer,其中每个HR ...
- HBase工具之监控Region的可用和读写延时状况
1.介绍HBase集群上region数目由于业务驱动而越来越多,由于服务器本身,网络以及hbase内部的一些不确定性bug等因素使得这些region可能面临着不可用或响应延时情况.通过对region的 ...
- HBase单个RegionServer的region数目上限
前言 RegionServer维护Master分配给它的region,处理对这些region的IO请求,负责切分在运行过程中变得过大的region, 由于集群性能( 分配的内存和磁盘是有限的 )有限的 ...
- hbase总结:如何监控region的性能
转载:http://ju.outofmemory.cn/entry/50064 随着大数据表格应用的驱动,我们的HBase集群越来越大,然而由于机器.网络以及HBase内部的一些不确定性的bug,使得 ...
- HBase如何选取split point
hbase region split操作的一些细节,具体split步骤很多文档都有说明,本文主要关注regionserver如何选取split point 首先推荐web ui查看hbase regi ...
- hbase 各个概念,region,storefile
HBase中有两张特殊的Table,-ROOT-和.META. .META.:记录了用户表的Region信息,它可以有多高region(这的意思是说.META.表可以分 裂成多个region,和用户表 ...
- hbase(一)region
前言 文章不含源码,只是一些官方资料的整理和个人理解 架构总览 这张图在大街小巷里都能看到,感觉是hbase架构中最详细最清晰的一张,稍微再补充几点. 1) Hlog是低版本hbase术语,现在称为W ...
- HBase 分裂(split)
1. 为什么split 最初一个Table 只有一个region(因此只能存放在一个region server上).随着数据的不断写入,HRegion越来越大,当到达一定程度后分裂为两个,通过负载均衡 ...
- HBase Shell手动移动Region
在生产环境中很有可能有那么几个Region比较大,但是都运行在同一个Regionserver中. 这个时候就需要手动将region移动到负载低的Regionserver中. 步骤: 1.找到要移动的r ...
随机推荐
- 死磕Spring之IoC篇 - @Bean 等注解的实现原理
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读 Spring 版本:5.1. ...
- 【python+selenium的web自动化】- 元素的常用操作详解(一)
如果想从头学起selenium,可以去看看这个系列的文章哦! https://www.cnblogs.com/miki-peng/category/1942527.html 本篇主要内容:1.元素 ...
- python基础学习之列表的功能方法
列表:list 格式 li = [1,2,3,4,5,6] 列表内部随意嵌套其他格式:字符串.列表.数字.元组.字典. 列表内部有序,且内容可更改 a = [1,2,3,4] a[0] = 5 ...
- 安全框架Drozer安装和简单使用
安全框架Drozer安装和简单使用 说明: drozer(即以前的Mercury)是一个开源的Android安全测试框架 drozer不是什么新工具,但确实很实用,网上的资料教程都很多了,最近自己项目 ...
- 让JS代码Level提升的忍者秘籍(实用)
本文章共2377字,预计阅读时间5-10分钟. 前言 没有前言. 你准备好成为同事眼中深藏不露.高深莫测.阳光帅气的前端开发了吗? 那就开始吧! 本文秉承宗旨:代码实用与逼格并存. 提升JS代码Lev ...
- 【关系抽取-R-BERT】模型结构
模型的整体结构 相关代码 import torch import torch.nn as nn from transformers import BertModel, BertPreTrainedMo ...
- Tomcat详解系列(1) - 如何设计一个简单的web容器
Tomcat - 如何设计一个简单的web容器 在学习Tomcat前,很多人先入为主的对它的认知是巨复杂的:所以第一步,在学习它之前,要打破这种观念,我们通过学习如何设计一个最基本的web容器来看它需 ...
- 通过 ASM 库生成和修改 class 文件
在 JVM中 Class 文件分析 主要详细讲解了Class文件的格式,并且在上一篇文章中做了总结. 众所周知,JVM 在运行时, 加载并执行class文件, 这个class文件基本上都是由我们所写的 ...
- 14、运行Django时浏览器中遇到Refused to display 'url' in a frame because it set 'X-Frame-Options' to 'deny'
问题:Refused to display 'url' in a frame because it set 'X-Frame-Options' to 'deny' 解决办法: 只需要在 Djagno ...
- 安装Dynamics CRM Report出错处理一
删除下面两个注册表项 HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\RunOnce.HKEY_CURRENT_USER\So ...