RDD的缓存
RDD的缓存/持久化
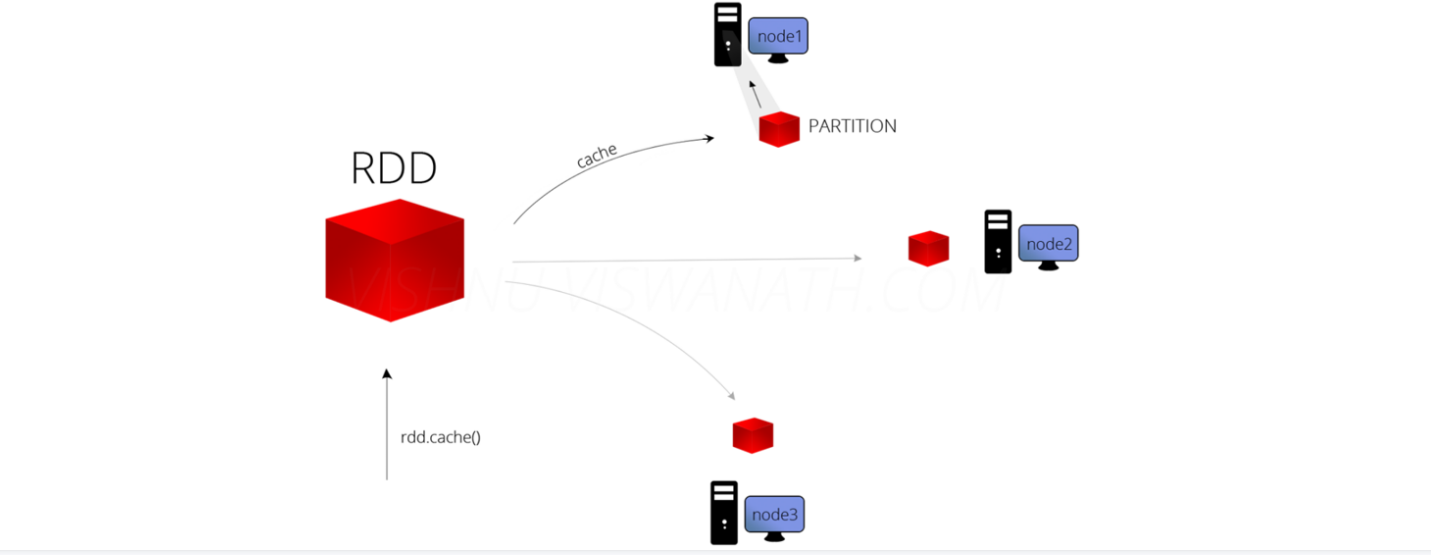
缓存解决的问题
缓存解决什么问题?-解决的是热点数据频繁访问的效率问题
在Spark开发中某些RDD的计算或转换可能会比较耗费时间,
如果这些RDD后续还会频繁的被使用到,那么可以将这些RDD进行持久化/缓存,
这样下次再使用到的时候就不用再重新计算了,提高了程序运行的效率。
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object Demo16Cache {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("****").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
//加入缓存的三种方式
//方式一
linesRDD.cache()//将常用的RDD放入缓存中,增加效率
//StorageLevel.MEMORY_ONLY 默认只放在缓存中
//方式二
//linesRDD.persist()
//def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
//指定缓存存储方式
linesRDD.persist(StorageLevel.MEMORY_AND_DISK)
/**
* 缓存的存储方式:推荐使用MEMORY_AND_DISK
* object StorageLevel {
* val NONE = new StorageLevel(false, false, false, false)
* val DISK_ONLY = new StorageLevel(true, false, false, false)
* val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
* val MEMORY_ONLY = new StorageLevel(false, true, false, true)
* val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
* val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
* val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
* val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
* val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
* val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
* val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
* val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
*/
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
//释放缓存
linesRDD.unpersist()
}
}
RDD中的checkpoint
RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
也可以把数据放在磁盘上,也并不是完全可靠的,
我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
object Demo17CheckPoint {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val linesRDD: RDD[String] = sc.textFile("spark/data/words.txt")
/**
* RDD数据可以持久化到内存中,虽然是快速的,但是不可靠
* 也可以把数据放在磁盘上,也并不是完全可靠的
* 我们可以把缓存数据放到我的HDFS中,借助HDFS的高可靠,高可用以及高容错来保证数据安全
*
*/
//设置HDFS的目录
sc.setCheckpointDir("spark/data/checkPoint")
//对需要缓存的RDD进行checkPoint
linesRDD.checkpoint()
linesRDD.flatMap(word => word)
.groupBy(word => word)
.map(l => {
val word = l._1
val cnt = l._2.size
word + "," + cnt
}).foreach(println)
val wordRDD: Unit = linesRDD.map(word => word)
.foreach(println)
}
}
RDD的缓存的更多相关文章
- Spark RDD概念学习系列之RDD的缓存(八)
RDD的缓存 RDD的缓存和RDD的checkpoint的区别 缓存是在计算结束后,直接将计算结果通过用户定义的存储级别(存储级别定义了缓存存储的介质,现在支持内存.本地文件系统和Tachyon) ...
- sparkRDD:第4节 RDD的依赖关系;第5节 RDD的缓存机制;第6节 DAG的生成
4. RDD的依赖关系 6.1 RDD的依赖 RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency ...
- RDD(八)——缓存与检查点
RDD通过persist方法或cache方法可以将前面的计算结果缓存,默认情况下 persist() 会把数据以序列化的形式缓存在 JVM 的堆空间中. 但是并不是这两个方法被调用时立即缓存,而是触发 ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- RDD缓存
RDD的缓存 Spark速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存数据集.当持久化某个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此RDD或衍生出的RDD进行的其他 ...
- Spark RDD详解 | RDD特性、lineage、缓存、checkpoint、依赖关系
RDD(Resilient Distributed Datasets)弹性的分布式数据集,又称Spark core,它代表一个只读的.不可变.可分区,里面的元素可分布式并行计算的数据集. RDD是一个 ...
- RDD:基于内存的集群计算容错抽象(转)
原文:http://shiyanjun.cn/archives/744.html 该论文来自Berkeley实验室,英文标题为:Resilient Distributed Datasets: A Fa ...
- Spark RDD Operations(2)
处理数据类型为Value型的Transformation算子可以根据RDD变换算子的输入分区与输出分区关系分为以下几种类型. 1)输入分区与输出分区一对一型. 2)输入分区与输出分区多对一型. 3)输 ...
- Spark RDD概念学习系列之RDD的checkpoint(九)
RDD的检查点 首先,要清楚.为什么spark要引入检查点机制?引入RDD的检查点? 答:如果缓存丢失了,则需要重新计算.如果计算特别复杂或者计算耗时特别多,那么缓存丢失对于整个Job的影响是不容 ...
随机推荐
- Python实现Telnet连接
import loggingimport telnetlibimport timeclass TelnetClient(): def __init__(self,): self.tn = telnet ...
- Redis-Cluster分片扩容
redis分片分片场景在业务量相对较小的时候,可以将所有数据都存到一台机器上,只使用redis单机模式,不存在分片问题.如果业务的数据量超过一台物理机器的内存大小时,则会面对扩展问题,需要多台机器去存 ...
- MySQL技术专题(X)该换换你的数据库版本了,让我们一同迎接8.0的到来哦!(初探篇)
前提背景 MySQL关是一种关系数据库管理系统,所使用的 SQL 语言是用于访问数据库的最常用的标准化语言,其特点为体积小.速度快.总体拥有成本低,尤其是开放源码这一特点,在 Web应用方面 MySQ ...
- 题解 HDU 5279 YJC plays Minecraft
题目传送门 题目大意 给出\(n\)以及\(a_{1,2,...,n}\),表示有\(n\)个完全图,第\(i\)个完全图大小为\(a_i\),这些完全图之间第\(i\)个完全图的点\(a_i\)与\ ...
- [kuangbin带你飞]专题一 简单搜索 棋盘问题
题来:链接https://vjudge.net/problem/OpenJ_Bailian-132 J - 棋盘问题 1.题目: 在一个给定形状的棋盘(形状可能是不规则的)上面摆放棋子,棋子没有区别. ...
- 内网渗透DC-3靶场通关
个人博客:点我 DC系列共9个靶场,本次来试玩一下DC-3,只有1个flag,下载地址. 下载下来后是 .ova 格式,建议使用vitualbox进行搭建,vmware可能存在兼容性问题.靶场推荐使用 ...
- 关于 我的博客和Git-hub
欢迎大家到我的GitHub 热烈讨论 https://github.com/ljj-19951010 由于另一个博客忘了怎么登陆了,换用此博客(仅供个人学习使用,请勿传播) 如果想看 特别详细的教程请 ...
- BUAA 软工 个人博客作业(一)
项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) 这个作业的要求在哪里 个人博客作业 我在这个课程的目标是 通过阅读<构建之法>大致了解软件工程 这个作业在哪 ...
- FastAPI 学习之路(五十五)操作Redis
之前我们分享了操作关系型数据库,具体文章, FastAPI 学习之路(三十二)创建数据库 FastAPI 学习之路(三十三)操作数据库 FastAPI 学习之路(三十四)数据库多表操作 这次我们分享的 ...
- PDF转图片部分公式字符丢失问题解决的爬坑记录
现象 PDF教材导出到系统中,由程序将PDF转为图片后合并成一张大图供前端标注,但是在标注数学和化学学科的时候且源文件是PDF的情况下出现公式部分字符丢失的情况,如下图 原件 转换后效果 WTF! 转 ...