A Tutorial on Energy-Based Learning
概
从能量的角度看一些函数, 这里就记录一下这些损失.
主要内容
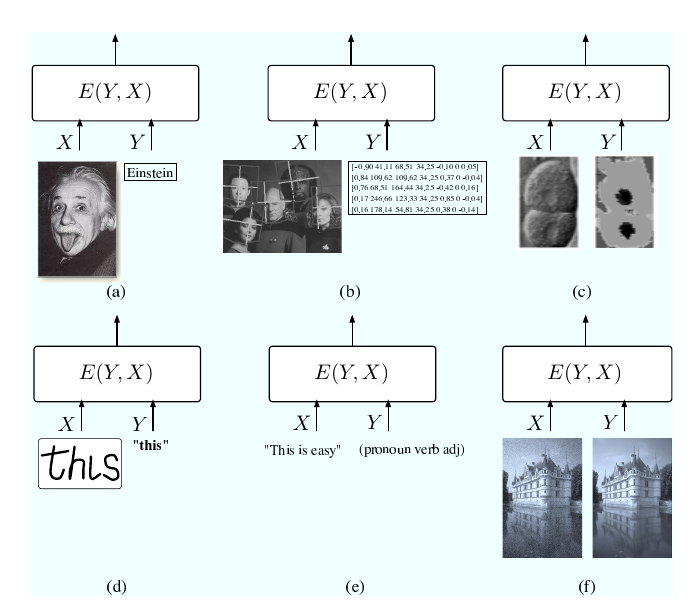
\(E(Y, X)\)反映了\(X, Y\)的关系, 认为能量越低, 而且的关系越紧密, 从下图中可以发现, \(X, Y\)的组合多种多样.
通常情况下, 我们需要训练一个映射, 其参数为\(W\), 一个好的参数可以使得
\]
很小. 不过我们通常会选取一些损失函数, 来间接最小化上面的能量函数
\]
其中\(R(W)\)是正则化项. 自然, 损失函数至少需要满足其最优点是最小化损失函数的, 当然应该还有一些其他的条件.
如果\(\mathcal{Y}\)是离散的, 我们可以令
\]
相应的连续情况下
\]
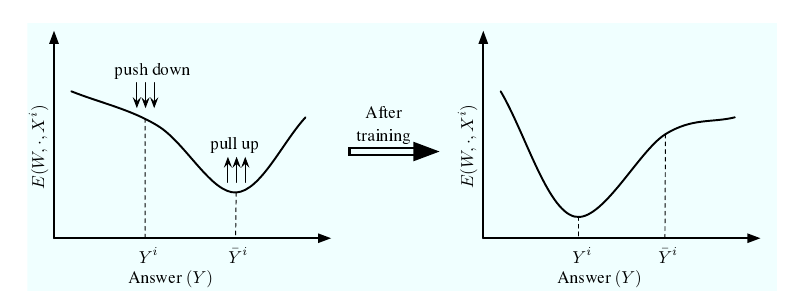
即\(\bar{Y}\)是我们最不爽的点. 很自然, 我们希望损失函数将我们希望的点\(Y^i\)的能量降低, 而拔高我们讨厌的\(\bar{Y}^i\)的能量.
损失函数
Energy Loss
\]
Generalized Perceptron Loss
\]
Generalized Margin Loss
Hinge Loss
\]
Log Loss
\]
LVQ2 Loss
\]
虽然LVQ2 Loss和上面的非margin loss一样, 似乎是没margin的, 但是作者说最后二者有一个饱和的比例\(1+\delta\), 但是不是特别理解.
MCE Loss
\]
其中\(\sigma\)是sigmoid.
Square-Square Loss
\]
Square-Exponential
\]
Negative Log-Likelihood Loss
\]
其中
\]
Empirical Error Loss
\]
好的损失应该满足的一些条件
都是充分条件, 所以不满足也有可能是满足所需要的性质的.
条件1
对于样本\((X^i, Y^i)\), 如果预测满足
\]
则推断结果应当为\(Y^i\).
条件2
对于变量\(Y\)以及样本\((X^i, Y^i)\)和margin \(m\), 若
\]
则推断结果应当为\(Y^i\).
条件3
这个条件就用语言描述吧.
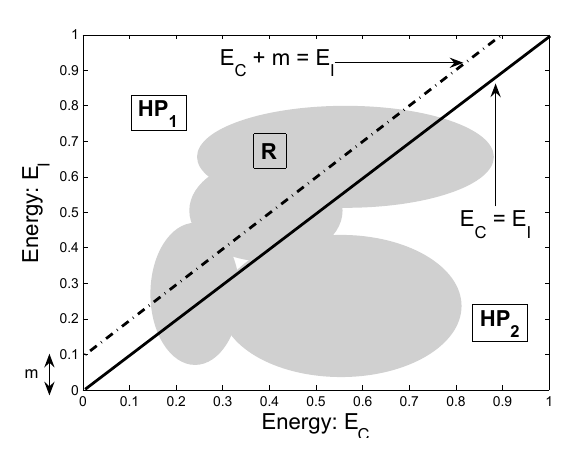
即, 要求\(HP_1\)与可行域\(R\)的交集中存在一解, 是的\((X^i, Y^i)\)在该点处的能量比\(HP_2\)与\(R\)交集的所有解的能量都要小, 其中
HP_2: E_C + m > E_I.
\]
\(E_C=E(W, Y^i, X^i)\), \(E_I=E(W, \bar{Y}^i, X^i)\).
下图给出了满足上述三个条件的损失及其对应的\(m\).

A Tutorial on Energy-Based Learning的更多相关文章
- A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python)
A Complete Tutorial on Tree Based Modeling from Scratch (in R & Python) MACHINE LEARNING PYTHON ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- Tutorial on GoogleNet based image classification --- focus on Inception module and save/load models
Tutorial on GoogleNet based image classification 2018-06-26 15:50:29 本文旨在通过案例来学习 GoogleNet 及其 Incep ...
- Pros and Cons of Game Based Learning
https://www.gamedesigning.org/learn/game-based-learning/ I remember days gone by at elementary schoo ...
- Octave Tutorial(《Machine Learning》)之第一课《数据表示和存储》
Octave Tutorial 第一课 Computation&Operation 数据表示和存储 1.简单的四则运算,布尔运算,赋值运算(a && b,a || b,xor( ...
- Game Based Learning: Why Does it Work?
Forty years of research[i] says yes, games are effective learning tools. People learn from games, an ...
- Octave Tutorial(《Machine Learning》)之第五课《控制语句和方程及向量化》
第五课 控制语句和方程 For,while,if statements and functions (1)For loop v=zeros(10,1) %initial vectors for i=1 ...
- Octave Tutorial(《Machine Learning》)之第四课《绘图数据》
第四课 Plotting Data 绘图数据 t = [0,0.01,0.98]; y1 = sin(2*pi*4*t); y2 = cos(2*pi*4*t); plot(t,y1);(绘制图1) ...
- Octave Tutorial(《Machine Learning》)之第三课《数据计算》
第三课 Culculating Data 数据计算 矩阵计算 1.简单的四则运算 2.相乘除,乘方运算(元素位运算) ".*"为对应元素的相乘计算 "./"为对 ...
- Octave Tutorial(《Machine Learning》)之第二课《数据移动》
第二课 Moving Data 数据移动 常用内置函数 (1)加载文件 load 文件名.dat(或load('文件名.dat')) 接着输入文件名便可查看文件里的数据 (2)显示当前工作空间的所有变 ...
随机推荐
- college-ruled notebook
TBBT.s3.e10: Sheldon: Where's your notebook?Penny: Um, I don't have one.Sheldon: How are you going t ...
- Z可读作zed的出处?
Commercial and international telephone and radiotelephone SPELLING ALPHABETS between World War I and ...
- 三维引擎导入obj模型全黑总结
最近有客户试用我们的三维平台,在导入模型的时候,会出现模型全黑和不可见的情况.本文说下全黑的情况. 经过测试,发现可能有如下几种情况. obj 模型没有法线向量 如果obj模型导出的时候没有导出法线向 ...
- Linux学习 - 文本编辑器Vim
一.Vim工作模式 二.命令 插入 a 光标后插入 A 光标所在行尾插入 i 光标前插入 I 光标所在行首插入 o 光标下插入新行 O 光标上插入新行 删除 x 删除光标处字符 nx 删除光标处后 ...
- Handler与多线程
1.Handler介绍 在Android开发中,我们常会使用单独的线程来完成某些操作,比如用一个线程来完成从网络上下的图片,然后显示在一个ImageView上,在多线程操作时,Android中必须保证 ...
- lucene索引的增、删、改
package com.hope.lucene;import org.apache.lucene.document.Document;import org.apache.lucene.document ...
- 用graphviz可视化决策树
1.安装graphviz. graphviz本身是一个绘图工具软件,下载地址在:http://www.graphviz.org/.如果你是linux,可以用apt-get或者yum的方法安装.如果是w ...
- 基于Web的质量和测试度量指标
直观了解软件质量和测试的完整性 VectorCAST/Analytics可提供便于用户理解的web仪表盘视图来显示软件代码质量和测试完整性指标,让用户能够掌握单个代码库的趋势,或对比多个代码库的度量指 ...
- 【JAVA今法修真】 第一章 今法有万象 百家欲争鸣
大家好,我是南橘,因为这段时间很忙,忙着家里的事情,忙着工作的事情,忙着考试的事情,很多时候没有那么多经历去写新的东西,同时,也是看了网上一些比较新颖的文章输出方式,自己也就在想,我是不是也可以这样写 ...
- 30个类手写Spring核心原理之MVC映射功能(4)
本文节选自<Spring 5核心原理> 接下来我们来完成MVC模块的功能,应该不需要再做说明.Spring MVC的入口就是从DispatcherServlet开始的,而前面的章节中已完成 ...