mysql索引最左匹配的理解(转载于知乎回答)
链接:https://www.zhihu.com/question/36996520/answer/93256153
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
这是你的表结构,有三个字段,分别是id,name,cid
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`cid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `name_cid_INX` (`name`,`cid`),
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8
索引方面:id是主键,(name,cid)是一个多列索引。
-----------------------------------------------------------------------------
下面是你有疑问的两个查询:
EXPLAIN SELECT * FROM student WHERE cid=1;


EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';


你的疑问是:sql查询用到索引的条件是必须要遵守最左前缀原则,为什么上面两个查询还能用到索引?
---------------------------------------------------------------------------------------------------------------------------
讲上面问题之前,我先补充一些知识,因为我觉得你对索引理解是狭隘的:
上述你的两个查询的explain结果中显示用到索引的情况类型是不一样的。,可观察explain结果中的type字段。你的查询中分别是:
1. type: index
2. type: ref
解释:
index:这种类型表示是mysql会对整个该索引进行扫描。要想用到这种类型的索引,对这个索引并无特别要求,只要是索引,或者某个复合索引的一部分,mysql都可能会采用index类型的方式扫描。但是呢,缺点是效率不高,mysql会从索引中的第一个数据一个个的查找到最后一个数据,直到找到符合判断条件的某个索引。
所以:对于你的第一条语句:
EXPLAIN SELECT * FROM student WHERE cid=1;
判断条件是cid=1,而cid是(name,cid)复合索引的一部分,没有问题,可以进行index类型的索引扫描方式。explain显示结果使用到了索引,是index类型的方式。
---------------------------------------------------------------------------------------------------------------------------
ref:这种类型表示mysql会根据特定的算法快速查找到某个符合条件的索引,而不是会对索引中每一个数据都进行一 一的扫描判断,也就是所谓你平常理解的使用索引查询会更快的取出数据。而要想实现这种查找,索引却是有要求的,要实现这种能快速查找的算法,索引就要满足特定的数据结构。简单说,也就是索引字段的数据必须是有序的,才能实现这种类型的查找,才能利用到索引。
有些了解的人可能会问,索引不都是一个有序排列的数据结构么。不过答案说的还不够完善,那只是针对单个索引,而复合索引的情况有些同学可能就不太了解了。
下面就说下复合索引:
以该表的(name,cid)复合索引为例,它内部结构简单说就是下面这样排列的:
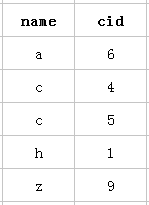
mysql创建复合索引的规则是首先会对复合索引的最左边的,也就是第一个name字段的数据进行排序,在第一个字段的排序基础上,然后再对后面第二个的cid字段进行排序。其实就相当于实现了类似 order by name cid这样一种排序规则。
所以:第一个name字段是绝对有序的,而第二字段就是无序的了。所以通常情况下,直接使用第二个cid字段进行条件判断是用不到索引的,当然,可能会出现上面的使用index类型的索引。这就是所谓的mysql为什么要强调最左前缀原则的原因。
那么什么时候才能用到呢?
当然是cid字段的索引数据也是有序的情况下才能使用咯,什么时候才是有序的呢?观察可知,当然是在name字段是等值匹配的情况下,cid才是有序的。发现没有,观察两个name名字为 c 的cid字段是不是有序的呢。从上往下分别是4 5。
这也就是mysql索引规则中要求复合索引要想使用第二个索引,必须先使用第一个索引的原因。(而且第一个索引必须是等值匹配)。
---------------------------------------------------------------------------------------------------------------------------
所以对于你的这条sql查询:
EXPLAIN SELECT * FROM student WHERE cid=1 AND name='小红';
没有错,而且复合索引中的两个索引字段都能很好的利用到了!因为语句中最左面的name字段进行了等值匹配,所以cid是有序的,也可以利用到索引了。
你可能会问:我建的索引是(name,cid)。而我查询的语句是cid=1 AND name='小红'; 我是先查询cid,再查询name的,不是先从最左面查的呀?
好吧,我再解释一下这个问题:首先可以肯定的是把条件判断反过来变成这样 name='小红' and cid=1; 最后所查询的结果是一样的。
那么问题产生了?既然结果是一样的,到底以何种顺序的查询方式最好呢?
所以,而此时那就是我们的mysql查询优化器该登场了,mysql查询优化器会判断纠正这条sql语句该以什么样的顺序执行效率最高,最后才生成真正的执行计划。所以,当然是我们能尽量的利用到索引时的查询顺序效率最高咯,所以mysql查询优化器会最终以这种顺序进行查询执行。
关于第一条select的补充解释
mysql索引最左匹配的理解(转载于知乎回答)的更多相关文章
- 【转】Mysql索引最左匹配原则理解
作者:沈杰 链接:https://www.zhihu.com/question/36996520/answer/93256153来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明 ...
- Mysql索引最左匹配原则
先来看个例子: 1. 示例1:假设有如下的一张表: DROP TABLE IF EXISTS testTable; CREATE TABLE testTable ( ID BIGINT NOT NUL ...
- 【转】mysql索引最左匹配原则的理解
作者:沈杰 链接:https://www.zhihu.com/question/36996520/answer/93256153 来源:知乎 CREATE TABLE `student` ( `id` ...
- mysql索引最左匹配原则的理解
CREATE TABLE `student` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, `ci ...
- MySQL索引原理及慢查询优化 转载
原文地址: http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型数据库.虽然性能 ...
- mysql索引作用的简单理解
转自:http://blog.csdn.net/pengsidong/article/details/62104703,有添加 索引好比书的目录,好比新华字典的拼音.偏旁部首查字,可以帮助人快速查找到 ...
- 深入浅出分析MySQL索引设计背后的数据结构
在我们公司的DB规范中,明确规定: 1.建表语句必须明确指定主键 2.无特殊情况,主键必须单调递增 对于这项规定,很多研发小伙伴不理解.本文就来深入简出地分析MySQL索引设计背后的数据结构和算法,从 ...
- MySQL 深入理解索引B+树存储 (转载))
出处:http://blog.codinglabs.org/articles/theory-of-mysql-index.html 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一 ...
- 【转载】MySQL索引原理及慢查询优化
原文链接:美团点评技术团队:http://tech.meituan.com/mysql-index.html MySQL凭借着出色的性能.低廉的成本.丰富的资源,已经成为绝大多数互联网公司的首选关系型 ...
随机推荐
- [cf1491I]Ruler Of The Zoo
为了统一描述,下面给出题意-- 有$n$只动物,编号为$i$的动物有属性$a_{i,j}$($0\le i<n,0\le j\le 2$) 初始$n$只动物从左到右编号依次为$0,1,...,n ...
- [bzoj1046]上升序列
以i为开头的最长上升子序列,那么就是反过来以i为结尾的最长下降子序列,预处理出来后,不断向后找到下一个数即可 1 #include<bits/stdc++.h> 2 using names ...
- 力扣 - 剑指 Offer 27. 二叉树的镜像
题目 剑指 Offer 27. 二叉树的镜像 思路1(递归) 我们可以使用深度优先搜索,先递归到链表的末尾,然后从末尾开始两两交换.就相当于后续遍历而已 记得要先保存下来node.right节点,因为 ...
- 【Mysql】三大日志 redo log、bin log、undo log
@ 目录 redo log(物理日志\重做日志) binlog(逻辑日志/归档日志) update语句执行流程 Uodolog(回滚日志/重做日志) undo log+redo log保证持久性 re ...
- poi上传下载
本教程只实现poi简单的上传下载功能,如需高级操作请绕行! <!--poi start--> <dependency> <groupId>org.apache.po ...
- 树形DP详解+题目
关于树形dp 我觉得他和线性dp差不多 总结 最近写了好多树形dp+树形结构的题目,这些题目变化多样能与多种算法结合,但还是有好多规律可以找的. 先说总的规律吧! 一般来说树形dp在设状态转移方程时都 ...
- python之元编程
一.什么是元编程 元编程是一种编写计算机程序的技术,这些程序可以将自己看作数据,因此你可以在运行时对它进行内省.生成和/或修改. Python在语言层面对函数.类等基本类型提供了内省及实时创建和修改的 ...
- Codeforces 1383F - Special Edges(状态压缩+最大流)
Codeforces 题目传送门 & 洛谷题目传送门 首先暴力显然是不行的,如果你暴力最大流过了我请你吃糖 注意到本题的 \(k\) 很小,考虑以此为突破口解题.根据最大流等于最小割定理,点 ...
- Codeforces 587F - Duff is Mad(根号分治+AC 自动机+树状数组)
题面传送门 第一眼看成了 CF547E-- 话说 CF587F 和 CF547E 出题人一样欸--还有另一道 AC 自动机的题 CF696D 也是这位名叫 PrinceOfPersia 的出题人出的- ...
- Codeforces 582D - Number of Binominal Coefficients(Kummer 定理+数位 dp)
Codeforces 题目传送门 & 洛谷题目传送门 一道数论与数位 dp 结合的神题 %%% 首先在做这道题之前你需要知道一个定理:对于质数 \(p\) 及 \(n,k\),最大的满足 \( ...