hdfs的FileSystem实例化
前言
在spark中通过hdfs的java接口并发写文件出现了数据丢失的问题,一顿操作后发现原来是FileSystem的缓存机制。补一课先
FileSystem实例化
FileSystem.get(config)是如何创建一个hadoop的FileSystem。
分为3个步骤。
1. 初始化所有支持的FileSystem(没有实例话,只是缓存类)
2. 通过uri的scheme拿到相应FileSystem
3. 缓存机制(如果不关闭的话,默认是开启)
下面详细分析一下各步骤流程
1. 初始化
通过java提供的ServiceLoader来录入所有可能的FileSystem,就像这样
ServiceLoader<FileSystem> serviceLoader = ServiceLoader.load(FileSystem.class);
for (FileSystem fs : serviceLoader) {
SERVICE_FILE_SYSTEMS.put(fs.getScheme(), fs.getClass());
}
待初始化的类通过配置文件声明,配置可以在hadoop-hdfs.jar里找到
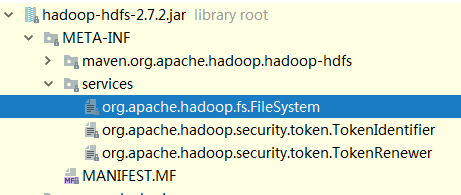
捎带一嘴,java提供的ServiceLoader有点像乞丐版spring的依赖反转。
2.scheme
通过对Uri的解析来判断创建一个什么FileSystem,
例如
hdfs://master:9200/test的scheme就是hdfs。
然后通过scheme和已经缓存好的FileSystem映射,找到需要实例化的类。
例如scheme是hdfs,那么就会创建一个DistributedFileSystem。 3. 缓存
FileSystem类中有一个Cache内部类,用于缓存已经被实例化的FileSystem。注意这个跟连接池还是有区别的,Cache中的缓存只是一个map,可以被多个线程拿到。这就会有一个问题,当你多线程同时get FileSystem的时候,可能返回的是同一个对象。所以切记,在多线程场景中,不要随意调用FileSystem.close,你关的连接可能会影响到其他正在使用的线程。
注意: 当你在其他框架上拿fileSystem对象需要额外注意,例如在spark上进行 FileSystem.get(),如果你想自定义某些配置,设置hdfs的副本数(dfs.replication) 之类,你必须在configuration中关闭FileSystem的缓存机制,也就是设置
configuration.set("fs.hdfs.impl.disable.cache","true")
这很重要,因为你不确定spark是否在你之前创建了一个FileSystem,而你得到的可能不是你想要的。
参考资料
// 遇到的相同问题
hdfs的FileSystem实例化的更多相关文章
- FileSystem实例化过程
HDFS案例代码 Configuration configuration = new Configuration(); FileSystem fileSystem = FileSystem.get(n ...
- 4、记录1----获取hdfs上FileSystem的方法 记录2:正则匹配路径:linux、hdfs
/** * 获取hadoop相关配置信息 * @param hadoopConfPath 目前用户需要提供hadoop的配置文件路径 * @return */ public static Config ...
- HDFS之FileSystem
package cn.hx.test; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; impo ...
- kafka-connect-hdfs连接hadoop hdfs时候,竟然是单点的,太可怕了。。。果断改成HA
2017-08-16 11:57:28,237 WARN [org.apache.hadoop.hdfs.LeaseRenewer][458] - <Failed to renew lease ...
- Hadoop(五):HDFS的JAVA API基本操作
HDFS的JAVA API操作 HDFS在生产应用中主要是客户端的开发,其核心步骤是从HDFS提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件. 主 ...
- HDFS中Java的API使用测试
import java.io.IOException; import java.util.Arrays; import java.util.Date; import java.util.Scanner ...
- Hadoop HDFS编程 API入门系列之从本地上传文件到HDFS(一)
不多说,直接上代码. 代码 package zhouls.bigdata.myWholeHadoop.HDFS.hdfs5; import java.io.IOException; import ja ...
- HDFS文件系统基本文件命令、编程读写HDFS
基本文件命令: 格式为:hadoop fs -cmd <args> cmd的命名通常与unix对应的命令名相同.例如,文件列表命令: hadoop fs -ls 1.添加目录和文件 HDF ...
- HDFS操作--文件上传/创建/删除/查询文件信息
1.上传本地文件到HDFS //上传本地文件到HDFS public class CopyFile { public static void main(String[] args) { try { C ...
随机推荐
- swift tableViewController
tableViewController 控制器 import UIKit class ViewController: UITableViewController { ...
- mysql 字符集研究
一.创建一个测试数据库 及一个测试用的表.均使用默认的编码方式. show variables like 'char%': mysql> show variables like 'char%'; ...
- Genymotion 模拟器的sd卡的位置
今天用genymotion测试一个例子,发现要用sdcard,虽然可以再DDMS的 File Explore 下看到 sdcard目录,也可以看到/mnt/sdcard 目录,但是往他那里传文件,建目 ...
- python基础-第十一篇-11.1JavaScript基础
JavaScript是一门解释型编程语言,主要是增强html页面的动态效果 JavaScript是有三部分组成:ECMAScript.BOM.DOM 单行注释// 多行/* */(必须是scr ...
- MySQL中的表级锁
数据的锁主要用来保证数据的一致性,数据库的锁从锁定的粒度上可以分为表级锁,行级锁和页级锁. MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制,比如MyISAM和MEMORY存 ...
- 如何查看windows某个目录下所有文件/文件夹的大小?
如何查看windows某个目录下所有文件/文件夹的大小? TreeSize Free绿色汉化版是一款硬盘空间管理工具,用树形描述出来,能够显示文件大小和实际占用空间数及浪费的空间等信息,让你做出相应的 ...
- ubuntu安装markdown
# sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys BA300B7755AFCFAE linuxidc@linuxidc:~ ...
- 使用Spring注解获取配置文件信息
需要加载的配置文件内容(resource.properties): #FTP相关配置 #FTP的IP地址 FTP_ADDRESS=192.168.1.121 FTP_PORT=21 FTP_USERN ...
- 深度分析ORACLE热点块问题
1.热点块的定义 数据库的热点块,从简单了讲,就是极短的时间内对 少量数据块进行了过于频繁的访问.定义看起来总是很简单的,但实际在数据库中,我们要去观察或者确定热点块的问题,却不是那么简单了.要深刻地 ...
- std::bind
参考资料 • cplusplus.com:http://www.cplusplus.com/reference/functional/bind/ • cppreference.com:http://e ...