【分库分表】sharding-jdbc实践—分库分表入门
一、准备工作
1、准备三个数据库:db0、db1、db2
2、每个数据库新建两个订单表:t_order_0、t_order_1
DROP TABLE IF EXISTS `t_order_x`;
CREATE TABLE `t_order_x` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` bigint NOT NULL,
`order_id` bigint NOT NULL,
`order_no` varchar(30) NOT NULL,
`isactive` tinyint NOT NULL DEFAULT '',
`inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
二、分库分表配置
数据源的配置可以使用任何链接池,本例用druid为例。
1、引言依赖包:
引用最新的maven包
<sharding-jdbc.version>2.0.1</sharding-jdbc.version><dependency>
<groupId>io.shardingjdbc</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>${sharding-jdbc.version}</version>
</dependency>
2、配置DataSource:
@Bean(name = "shardingDataSource", destroyMethod = "close")
@Qualifier("shardingDataSource")
public DataSource getShardingDataSource() {
// 配置真实数据源
Map<String, DataSource> dataSourceMap = new HashMap<>(3); // 配置第一个数据源
DruidDataSource dataSource1 = createDefaultDruidDataSource();
dataSource1.setDriverClassName("com.mysql.jdbc.Driver");
dataSource1.setUrl("jdbc:mysql://localhost:3306/db0");
dataSource1.setUsername("root");
dataSource1.setPassword("root");
dataSourceMap.put("db0", dataSource1); // 配置第二个数据源
DruidDataSource dataSource2 = createDefaultDruidDataSource();
dataSource2.setDriverClassName("com.mysql.jdbc.Driver");
dataSource2.setUrl("jdbc:mysql://localhost:3306/db1");
dataSource2.setUsername("root");
dataSource2.setPassword("root");
dataSource2.setName("db1-0001");
dataSourceMap.put("db1", dataSource2); // 配置第三个数据源
DruidDataSource dataSource3 = createDefaultDruidDataSource();
dataSource3.setDriverClassName("com.mysql.jdbc.Driver");
dataSource3.setUrl("jdbc:mysql://localhost:3306/db2");
dataSource3.setUsername("root");
dataSource3.setPassword("root");
dataSourceMap.put("db2", dataSource3); // 配置Order表规则
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration();
orderTableRuleConfig.setLogicTable("t_order");
orderTableRuleConfig.setActualDataNodes("db${0..2}.t_order_${0..1}");
//orderTableRuleConfig.setActualDataNodes("db0.t_order_0,db0.t_order_1,db1.t_order_0,db1.t_order_1,db2.t_order_0,db2.t_order_1"); // 配置分库策略(Groovy表达式配置db规则)
orderTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("user_id", "db${user_id % 3}")); // 配置分表策略(Groovy表达式配置表路由规则)
orderTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_${order_id % 2}")); // 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig); // 配置order_items表规则... // 获取数据源对象
DataSource dataSource = null;
try {
dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, new ConcurrentHashMap(), new Properties());
} catch (SQLException e) {
e.printStackTrace();
}
return dataSource;
}
可以使用Druid监控db。
三、示例验证
1、新增数据
@Slf4j
@RestController
@RequestMapping("/order")
public class OrderController {
@Autowired
private OrderMapper orderMapper; @RequestMapping("/add")
public void addOrder() {
OrderEntity entity10 = new OrderEntity();
entity10.setOrderId(10000L);
entity10.setOrderNo("No1000000");
entity10.setUserId(102333001L);
orderMapper.insertSelective(entity10);
OrderEntity entity11 = new OrderEntity();
entity11.setOrderId(10001L);
entity11.setOrderNo("No1000000");
entity11.setUserId(102333000L);
orderMapper.insertSelective(entity11);
}
}
依据配置的分片规则
- DB路由规则:user_id % 3:
102333001 % 3 = 1
102333000 % 3 = 0
- 表路由规则:order_id % 2:
10000 % 2 = 0
10001 % 2 = 1
userid=102333001,orderId=10000的数据落地到db1.t_order_0
userid=102333000,orderId=10001的数据落地到db0.t_order_1
2、未指定分片规则字段的查询
/**广播遍历所有的库和表*/
@RequestMapping("get")
public void getOrder() {
List<Integer> ids = new ArrayList<>();
ids.add(4);
List<OrderEntity> orderEntities = orderMapper.selectByPrimaryIds(ids); log.info(JSON.toJSONString(orderEntities));
}
由druid监控sql得知,查询被广播到db0、db1、db2的各个表里,如下监控所示:
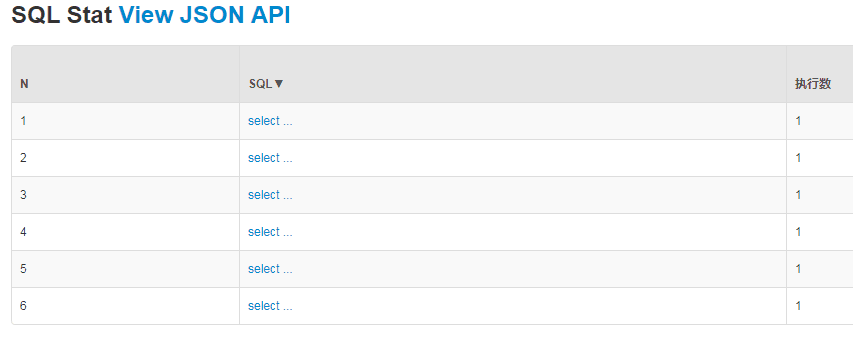
3、不能执行批量插入操作
不支持对不同分片规则的字段值进行批量插入操作,类似sql:insert into t_order values(x,x,x,x),(x,x,x,x),(x,x,x,x)
4、谨慎修改分片规则字段
如果修改了分片规则的字段,比如本例的user_id或order_id,因为路由规则会造成数据存在,却查不到数据的情况。
@RequestMapping("/upd")
public void update() {
OrderEntity orderWhere = new OrderEntity();
orderWhere.setOrderId(10001L);
orderWhere.setUserId(102333001L);
orderWhere.setId(4L);
OrderEntity orderSet = new OrderEntity();
orderSet.setOrderId(10002L);
orderSet.setOrderNo("修改订单号");
orderMapper.updateByPredicate(orderSet, orderWhere);
/**查不到,orderId更改会引起路由查询失败*/
OrderEntity predicate = new OrderEntity();
predicate.setOrderId(10002L);
OrderEntity entity = orderMapper.selectSingleByPredicate(predicate);
log.info("after update orderEntity:"+JSON.toJSONString(entity));
}
四、sharding建表
目前配置并验证了3个库,每库2个order表的场景:
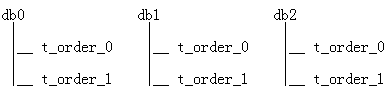
如果分库分表数量比较多,仅仅创建表就是一件很繁琐的事情。sharding查询数据不指定分片规则字段时,会自动路由到各个库的各个表里查询,不知道大家有没有想到:如果配置要创建表的路由规则,用sharding来执行一条创建sql的语句,会不会就自动路由到各个库去执行了,也就代替人工去各个库建表了呢?下面来验证一下这个想法,以创建t_order_items表为例:
1、配置t_order_items的规则
在上面配置t_order规则下面补充t_order_items的规则配置:
// 省略配置order_item表规则...
TableRuleConfiguration orderItemTableRuleConfig = new TableRuleConfiguration();
orderItemTableRuleConfig.setLogicTable("t_order_items");
orderItemTableRuleConfig.setActualDataNodes("db${0..2}.t_order_items_${0..1}");// 配置分库策略
orderItemTableRuleConfig.setDatabaseShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "db${order_id % 3}")); // 配置分表策略
orderItemTableRuleConfig.setTableShardingStrategyConfig(new InlineShardingStrategyConfiguration("order_id", "t_order_items_${order_id % 2}")); shardingRuleConfig.getTableRuleConfigs().add(orderItemTableRuleConfig);
2、t_order_items建表sql语句
<update id="createTItemsIfNotExistsTable">
CREATE TABLE IF NOT EXISTS `t_order_items` (
`id` bigint NOT NULL AUTO_INCREMENT,
`order_id` bigint NOT NULL,
`unique_no` varchar(32) NOT NULL,
`quantity` int NOT NULL DEFAULT '1',
`is_active` tinyint NOT NULL DEFAULT 1,
`inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
</update>
3、OrderItemsMapper方法
Integer createTItemsIfNotExistsTable();
4、执行方法
orderItemsMapper.createTItemsIfNotExistsTable();
查看db0、db1、db2:
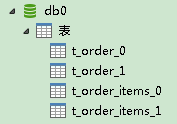
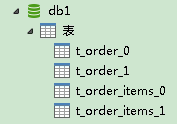

验证了我们上面的想法,建表成功了。
附录
如果没有配置t_order_items规则,执行建表sql会报错:
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error updating database. Cause: io.shardingjdbc.core.exception.ShardingJdbcException: Cannot find table rule and default data source with logic table: 't_order_items'
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: CREATE TABLE IF NOT EXISTS `t_order_items` ( `id` bigint NOT NULL AUTO_INCREMENT, `order_id` bigint NOT NULL, `unique_no` varchar(32) NOT NULL, `quantity` int NOT NULL DEFAULT '1', `is_active` tinyint NOT NULL DEFAULT 1, `inserttime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP, `updatetime` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
### Cause: io.shardingjdbc.core.exception.ShardingJdbcException: Cannot find table rule and default data source with logic table: 't_order_items'
【分库分表】sharding-jdbc实践—分库分表入门的更多相关文章
- sharding jdbc(sphere) 3.1.0 spring boot配置
sharding jdbc 2.x系列详解参见https://www.cnblogs.com/zhjh256/p/9221634.html. 最近将sharding jdbc的配置从xml切换到了sp ...
- Sharding JDBC整合SpringBoot 2.x 和 MyBatis Plus 进行分库分表
Sharding JDBC整合SpringBoot 2.x 和 MyBatis Plus 进行分库分表 交易所流水表的单表数据量已经过亿,选用Sharding-JDBC进行分库分表.MyBatis-P ...
- 转数据库分库分表(sharding)系列(二) 全局主键生成策略
本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请参考该系列的前一篇文章:数据库分库分表( ...
- 数据库分库分表(sharding)系列【转】
原文地址:http://www.uml.org.cn/sjjm/201211212.asp数据库分库分表(sharding)系列 目录; (一) 拆分实施策略和示例演示 (二) 全局主键生成策略 (三 ...
- 数据库分库分表(sharding)系列(二) 全局主键生成策略
本文将主要介绍一些常见的全局主键生成策略,然后重点介绍flickr使用的一种非常优秀的全局主键生成方案.关于分库分表(sharding)的拆分策略和实施细则,请参考该系列的前一篇文章:数据库分库分表( ...
- 数据库分库分表(sharding)系列
数据库分库分表(sharding)系列 目录; (一) 拆分实施策略和示例演示 (二) 全局主键生成策略 (三) 关于使用框架还是自主开发以及sharding实现层面的考量 (四) 多数据源的 ...
- Sharding Sphere的分库分表
什么是 ShardingSphere? 1.一套开源的分布式数据库中间件解决方案 2.有三个产品:Sharding-JDBC 和 Sharding-Proxy 3.定位为关系型数据库中间件,合理在分布 ...
- 数据库分库分表(sharding)系列(一) 拆分规则
第一部分:实施策略 数据库分库分表(sharding)实施策略图解 1. 垂直切分垂直切分的依据原则是:将业务紧密,表间关联密切的表划分在一起,例如同一模块的表.结合已经准备好的数据库ER图或领域模型 ...
- 转数据库分库分表(sharding)系列(一) 拆分实施策略和示例演示
本文原文连接: http://blog.csdn.net/bluishglc/article/details/7696085 ,转载请注明出处!本文着重介绍sharding切分策略,如果你对数据库sh ...
随机推荐
- 更改hadoop native库文件后datanode故障
hadoop是用cloudra的官方yum源安装的,服务器是CentOS6.3 64位操作系统,自己写的mapreduce执行的时候hadoop会提示以下错误: WARN util.NativeCod ...
- tomcat下载与安装..使用和配置环境变量
操作环境: xp, myEclipse6.5 tomcat6.0 正文: 一.下载 tomcat官方网站 http://tomcat.apache.org 在左边Download树形菜单中 点击最新版 ...
- js解析json字符
这是真真遇到的问题,后台给我返回的是json的字符串: {"status":410,"data":"","message" ...
- Objective-C代码学习大纲(5)
2011-05-11 14:06 佚名 otierney 字号:T | T 本文为台湾出版的<Objective-C学习大纲>的翻译文档,系统介绍了Objective-C代码,很多名词为台 ...
- 后端程序员如何玩转AJAX
1.原生的Ajax入门 (感觉很是繁琐,所以一般我们都是用简单的方式) 创建一个核心对象 XMLHttpRequest var xmlhttp; if (window.XMLHttpRequest) ...
- 对 js 高程 Preflighted Reqeusts 的理解
看JS高程遇到 Preflighted Reqeusts不大理解,遂百度下: 转自:http://todoit.me/ajax-preflight/ 最近在做一个 VUE 的项目的时候, 和后端的小伙 ...
- 妙味,结构化模块化 整站开发my100du
********************************************************************* 重要:重新审视的相关知识 /* 妙味官网:www.miaov ...
- Proud Merchants---hdu3466(有01背包)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3466 与顺序有关的01背包. 如果一个物品p = 5,q = 7,一个物品p = 5,q = 9,如果 ...
- Apache mahout 源码阅读笔记--协同过滤, PearsonCorrelationSimilarity
协同过滤源码路径: ~/project/javaproject/mahout-0.9/core/src $tree main/java/org/apache/mahout/cf/taste/ -L 2 ...
- python数据分析基础——numpy和matplotlib
numpy库是python的一个著名的科学计算库,本文是一个quickstart. 引入:计算BMI BMI = 体重(kg)/身高(m)^2假如有如下几组体重和身高数据,让求每组数据的BMI值: w ...