ETL增量处理总结
1 LOG表
1.1 思路
用log表记录业务库某表yw_tableA发生变化数据的主键。数据进入BI库目标表bi_tableA前,先根据log表记录的主键进行delete。
1.2 设计
1.2.1 log表结构
CREATE TABLE LOG
(
key_1 VARCHAR(20), --主键1
key_2 VARCHAR(20), --主键2
tName VARCHAR(20), --来源表
updateDate DATE, --更新日期
loadDate DATE --加载日期
);
1.2.2 etl流程
- yw_tableA中发生变化的数据,主键存入log,所有列存入BI库临时表tmp_bi_tableA(图1);
- 根据log表,删除BI库bi_tableA中已存在数据(图2);
- tmp_bi_tableA数据进入bi_tableA(图2)。
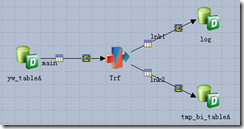
图1 业务数据进入日志和临时表
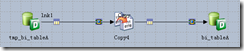
图2 目标表初始化以及临时表数据进入目标
1.2.3 附部分sql
--目标表初始化
delete from bi_tableA tg where exists (select 1 from tmp_bi_tableA tmp where tg.key1 = tmp.key1)
2 左关联(键比对、全表比对)
2.1 思路
业务库某表yw_tableA左关联BI库bi_tableA,可以关联上的舍弃;关联不上的进入目标表bi_tableA,然后对同一个业务主键多条进行处理(打上标记或delete)。比较适合小维表更新。
2.2 设计
2.2.1 目标表结构
create tabel bi_tableA
(
physical_key int identity, --物理键,自增
logical_key varchar(20), --业务键
col1 varchar(20), --其他列
nowstate char(1), --状态
loadDate DATE --加载日期
)
2.2.2 etl流程
- yw_tableA与bi_tableA主键或多列比对,得出需要进入目标表的记录,进入目标表bi_tableA;
- 目标表bi_tableA数据处理,删除或状态位。
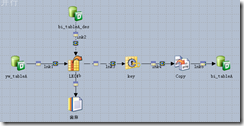
图3 关联设计
2.2.3 附部分sql
--目标表状态更新(同一业务键记录保留最新)
update bi_tableA set nowstate='' where physical_key not in (select max(physical_key) from bi_tableA group by logical_key having count(physical_key) > 1 and nowstate='' )
ETL增量处理总结的更多相关文章
- ETL增量单表同步简述_根据timestamp增量
ETL增量单表同步简述 1. 实现需求 当原数据库的表有新增.更新.删除操作时,将改动数据同步到目标库对应的数据表. 2. 设计思路 设计总体流程图如下: 步骤简单说明: 1.设置job的执行属性,如 ...
- ETL增量单表同步简述_根据dateTime增量
ETL增量单表同步简述 1. 实现需求 当原数据库的表有新增.更新.删除操作时,将改动数据同步到目标库对应的数据表. 2. 设计思路 设计总体流程图如下: 步骤简单说明: 1.设置job的执行属性,如 ...
- 【转】ETL增量抽取——通过时间戳方式实现
这个实验主要思想是在创建数据库表的时候, 通过增加一个额外的字段,也就是时间戳字段, 例如在同步表 tt1 和表 tt2 的时候, 通过检查那个表是最新更新的,那个表就作为新表,而另外的表最为旧表被新 ...
- ETL之增量抽取方式
1.触发器方式 触发器方式是普遍采取的一种增量抽取机制.该方式是根据抽取要求,在要被抽取的源表上建立插入.修改.删除3个触发器,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个增量日志表 ...
- ETL中的数据增量抽取机制
ETL中的数据增量抽取机制 ( 增量抽取是数据仓库ETL(extraction,transformation,loading,数据的抽取.转换和装载)实施过程中需要重点考虑的问 题.在ETL过 ...
- 数据仓库系列之ETL中常见的增量抽取方式
为了实现数据仓库中的更加高效的数据处理,今天和小黎子一起来探讨ETL系统中的增量抽取方式.增量抽取是数据仓库ETL(数据的抽取(extraction).转换(transformation)和装载(lo ...
- ETL数据采集方法
1.触发器方式 触发器方式是普遍采取的一种增量抽取机制.该方式是根据抽取要求,在要被抽取的源表上建立插入.修改.删除3个触发器,每当源表中的数据发生变化,就被相应的触发器将变化的数据写入一个增量日志表 ...
- 数据库开发之ETL概念
原文链接:https://blog.csdn.net/jianzhang11/article/details/104240047/ ETL基础概念 - 背景随着企业的发展,各业务线.产品线.部门都会承 ...
- 《BI项目笔记》增量ETL数据抽取的策略及方法
增量抽取 增量抽取只抽取自上次抽取以来数据库中要抽取的表中新增或修改的数据.在ETL使用过程中.增量抽取较全量抽取应用更广.如何捕获变化的数据是增量抽取的关键.对捕获方法一般有两点要求:准确性,能够将 ...
随机推荐
- Bootstrap CSS组组件架构的设计思想
w AO模式 Append Overwrite 附加重写
- 设计模式之Singleton模式
当程序运行时,有时会希望在程序中,只能存在一个实例,为了达到目的,所以设计了Singleton模式,即单例模式. 单例模式的特征: 想确保任何情况下只存在一个实例 想在程序上表现出只存在一个实例 示例 ...
- Ansible安装过程中常遇到的错误(FAQ)
1.安装完成后允许命令报错 Traceback (most recent call last): File , in <module> (runner, results) = cli.ru ...
- PHP的生命周期
了解PHP生命周期之前,先了解一下apache是怎么和php关联起来的吧~ 1.Apache运行机制剖析 ----------------------------- 总体示意图如下: Apache ...
- javafx 表格某一列设置未复选框
1.表格要设置成可编辑.2.对列进行如下设置.列定义: @FXMLprivate TableColumn<Hole, Boolean> id_colCheck; 列设置id_colChec ...
- 优秀Python学习资源收集汇总--强烈推荐(转)
原文:http://www.cnblogs.com/lanxuezaipiao/p/3543658.html Python是一种面向对象.直译式计算机程序设计语言.它的语法简捷和清晰,尽量使用无异义的 ...
- Linux ls命令
ls:即列表List的意思,用来列出目录下的文件用来列出给定目录下的文件,参数为空默认列出当前目录下的文件. 用法是:ls [选项] [目录] 常用的选项有 -a, –all 列出目录下的所有文件,包 ...
- (0.2.5)Mysql安装——RPM方式安装
rpm安装mysql 卸载与安装服务端 一.安装服务端与客户端 #查看RPM包中所有的文件shell> rpm -qpl mysql-community-server-version-dis ...
- c# 方法传递参数
一.参数的使用方法: 1.值参数(Value Parameter ) 格式:方法名称(参数类型 参数名称[,参数类型 参数名称]) 2.引用参数(Reference Parameter ) 格式:方法 ...
- redis实现自动输入完成(八)
1. 介绍 当我们在京东商城的搜索框,输入想要搜索的内容,比如你想要搜索"热水瓶",刚输入一个"热"字,就会出现一个下拉框,列出了很多以"热" ...