前馈网络求导概论(一)·Softmax篇
Softmax是啥?
Hopfield网络的能量观点
1982年的Hopfiled网络首次将统计物理学的能量观点引入到神经网络中,
将神经网络的全局最小值求解,近似认为是求解热力学系统的能量最低点(最稳定点)。
为此,特地为神经网络定义了神经网络能量函数$E(x|Label)$,其中$x$为输入。
$E(x|Label)=-\frac{1}{2}Wx \Delta Y \quad where \quad \Delta Y=y-label$ (省略Bias项)
值得注意的是,这套山寨牌能量函数只能求出局部最小值,SVM用二次规划函数替换掉之后才能求全局最小值。
唯一的败笔是,Hopfiled网络的输出仍然采用了阶跃函数Sign,走的还是Rosenblatt的老路子。
这个能量函数非常有趣,它在阶跃函数状态下永远是递减的,即便是W永远是正的。(错误的随机初始化也是OK的)。
原因如下:
I、当阶跃函数输出为1时,Wx为正,若产生Loss,$\Delta Y=1-(-1)=2$,显然$\Delta YE(x|y)$为负。
II、当阶跃函数输出为-1时,Wx为负,若产生Loss,$\Delta Y=-1-(1)=-2$,显然$\Delta YE(x|y)$还是为负。
III、若无LOSS,$\Delta Y=1-1$或$(-1)-(-1)$都为0,$\Delta E(x|y)$也为0。
概率与Boltzmann机
祖师爷Hinton在1985年创立了第一个随机神经网络,首次将概率引入神经网络这个大玄学中。
值得一提的是,在当时概率图模型也是被公认为玄学之一,很多研究者认为,信概率还不如信神经网络。(今天倒是反过来了)
Boltzmann机延续了Hopfiled能量函数的传统,但是用一个奇葩的归一化函数来产生概率,以取代相对不精确的阶跃函数。
这个归一化函数描述如下:
$P(y)=\frac{1}{1+e^{\frac{-(Wx+b)}{T}}}$
其中T为温度系数,超参数之一,需要调参。
看起来怎么那么眼熟呢,扔掉T之后,这不就是Sigmoid函数么。
可以看到,Boltzmann机为了表达概率,选用了Sigmoid函数作为神经网络的概率平滑产生器。
多变量概率与限制Boltzmann机
1986年由Smolensky创立的限制Boltzmann机将Hopfiled网络的输出部折回,这样就产生了多变量的输出。
如何去表达此时多变量情况下的概率,能量模型—配分函数(Partition Function)解决了这一点:
$P(x)=\frac{e^{-E(x)}}{Z}=\frac{e^{-E(x)}}{\sum _{i}e^{-E(i)}}$
配分项Z是大家耳熟能详的恶心之物,它的求解让深度学习推迟了20年。
在深度学习被卡的20年间,配分项函数在多变量的判别模型中广泛推广,疑似是Softmax的雏形。
EBM(EnergyBased Model)
在LeCun的EBM教程Slides的介绍了配分判别函数,也就是今天的Softmax函数。
★The partition function ensures that undesired answers are given low probability
★For learning, we need to approximate the partition function (or its gradient with respect to the parameters)
顺便将其批判了一番:
★Max likelihood learning gives high probability to good answers
★Problem: there are too many bad answers!
这部分的观点可以参照PRML的序章关于贝叶斯拟合学习的讨论,采用配分判别的Loss、基于极大似然的频统方法
非常容易产生过拟合和弱泛化,贝叶斯学习和深度学习则引入先验Prior在极大似然的统计基础上做惩罚。
配分判别函数的定义如下:
$P(Y|X)=\frac{e^{-\beta}E(Y,X)}{\int_{y\in Y}e^{-\beta}E(y,X)}$
其中$\beta$为系数,扔掉之后就是Softmax函数。
SoftmaxLoss
$NLL = - \sum _{i}^{examples}\sum _{k}^{classes}l(y(i)=k)\cdot log[Softmax(X_{k}^{i})]$
不做过多介绍,见我的早期博文:Softmax回归
前向传播求Loss的时候只要记住一点区别:
I、在Logistic回归中,对每个样本,Loss-=$\log(1-Sigmoid)$或者Loss-=$\log(Sigmoid)$
II、在Softmax回归中,对每个样本,Loss只减去对应Label的$\log(Softmax)$
比较I、II也可以看出来,Logistic回归的二选一只是Softmax回归的N选一的特例。
泛型Softmax求导
尽管DeepLearning的基石是多样本与并行计算,但是在泛型章节中不考虑多样本情况。
求导描述将尽量与Caffe框架中的命名方式同步,以便于理解代码。
同时假定Softmax Axis上,命中Label的下标为k。
SoftmaxLoss
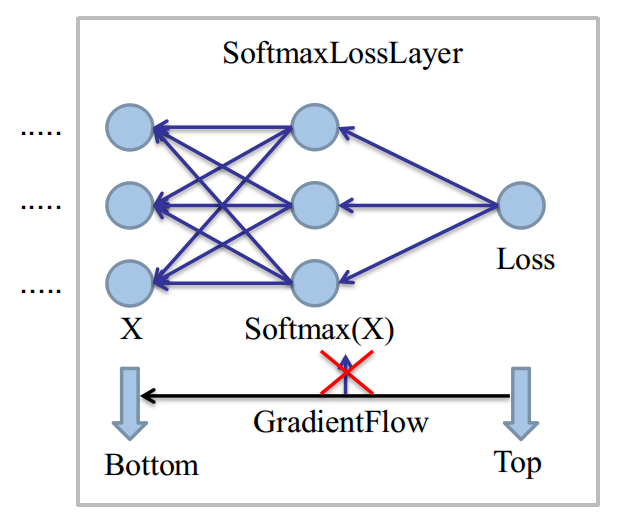
上图是在当单样本情况下,直接取Softmax Axis而画的,现在我们假设这是一个N=3的分类问题。(0,1,2)
同时取Class=2作为当前样本,命中的Label,即k=2。
由于Loss只和命中的分类有关,有:
$Softmax(X_{k})=\frac{e^{X_{k}}}{\sum _{i}e^{X_{i}}}$
则NLL (Negative-Log-Likelihood)为:
$NLL=-\log(Softmax(X_{k}))=-\log(\frac{e^{X_{K}}}{\sum _{i}e^{X_{i}}})\\ \quad \\ \qquad \qquad \qquad \qquad \qquad \qquad \; \; \,=\log(\sum _{i}e^{X_{i}})-log(e^{X_{k}}) \\ \quad \\ \qquad \qquad \qquad \qquad \qquad \qquad \; \; \, =\log(\sum _{i}e^{X_{i}})-X_{k}$
此时对于神经元$X_{k}$,有如下两种求导方案:
I、 $BottomDiff(k)=\frac{\partial NLL}{\partial Softmax(X_{k})}\frac{\partial Softmax(X_{k})}{\partial X_{k}}$
II、 $BottomDiff(k)=\frac{\partial NLL}{\partial X_{k}}$
其中,第一种是没有必要的,一般而言,Softmax的中间导数几乎不会用到。
除非我们让Softmax后面不接Loss,接其它的层,下一节会讲这种特殊情况,求导相当复杂。
现在考虑更一般的神经元$X_{i}$,对NLL求导:
$\frac{\partial \log(\sum _{i}e^{X_{i}})-X_{k}}{\partial X_{i}}=\left\{\begin{matrix}\frac{e^{X_{K}}}{\sum _{i}e^{X_{i}}} - 1 \quad (i\neq k) \\ \\\frac{e^{X_{K}}}{\sum _{i}e^{X_{i}}} \quad (i=k)\\ \\0 \quad (if \;ignore\;i)\end{matrix}\right.$
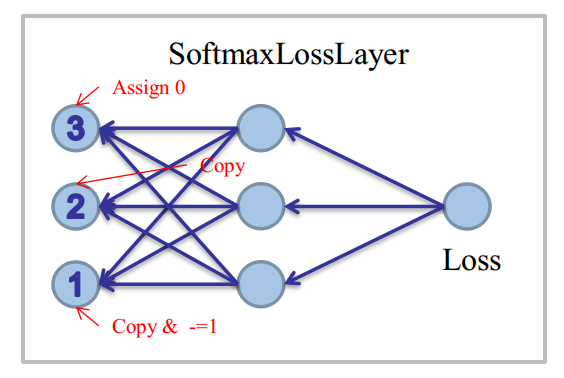
编程时:
对于①条件:先Copy一下Softmax的结果(即prob_data)到bottom_diff,再对k位置的unit减去1
对于②条件:直接Copy一下Softmax的结果(即prob_data)到bottom_diff
对于③条件:找到ignore位置的unit,强行置为0。
图示如下:
Softmax
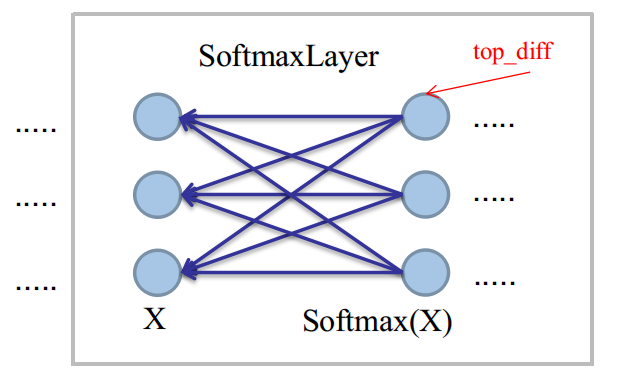
在SoftmaxLayer中,我们将会遇到最普遍的反向传播任务:已知top_diff,求bottom_diff。
为了表述方便,设已知的top_diff的偏导表达式为:$\frac{\partial l}{Softmax(X)}$,则:
$BottomDiff(i)=\sum _{j}\frac{\partial l}{\partial Softmax(X_{j})}\frac{\partial Softmax(X_{j})}{\partial X_{i}}$
这是单独对Softmax求导的最麻烦之处,由于全连接性,输入神经元$X_{i}$将被全部的输出神经元污染。
更一般的,我们将其写成:
$BottomDiff(i)=\frac{\partial l}{\partial Softmax(X)}\frac{\partial Softmax(X)}{\partial X_{i}}$。
考虑$\frac{\partial Softmax(X_{j})}{\partial X_{i}}$,有:
$\frac{\partial Softmax(X_{j})}{\partial X_{i}}=\left\{\begin{matrix}-Softmax(X_{j})*Softmax(X_{i})+Softmax(X_{i}) \quad i=j\\ \\ -Softmax(X_{j})*Softmax(X_{i}) \quad i\neq j\end{matrix}\right.$
联合两部分后,有:
$\sum \left\{\begin{matrix}-Softmax(X_{j})*\frac{\partial l}{\partial Softmax(X_{j})}*Softmax(X_{i})+Softmax(X_{i})*\frac{\partial l}{\partial Softmax(X_{j})} \quad i=j\\ \\ -Softmax(X_{j})*\frac{\partial l}{\partial Softmax(X_{j})}*Softmax(X_{i}) \quad i\neq j\end{matrix}\right.$
提取公共项部分:
$BottomDiff(i)=Softmax(X_{i})\left \langle \sum {j}\left \{-Softmax(X_{j})*\frac{\partial l}{\partial Softmax(X_{j})}\right \}+\frac{\partial l}{\partial Softmax(X_{i}) })\right \rangle\\ \quad \\ \qquad \qquad \qquad \; \; \; =TopData(i)\left \langle - \sum {j}\left \{TopData(j)*TopDiff(j)\right \}+TopDiff(i) \right \rangle\\ \quad \\ \qquad \qquad \qquad \; \; \; =TopData(i)\left \langle - \left \{TopData \bullet TopDiff \right \} +TopDiff(i) \right \rangle$
Caffe中做了以下两点额外的优化:
I、由于对所有$X_{i}$,都要计算相同的点积项$\sum {j}\left \{TopData(j)*TopDiff(j)\right \}$,
一个简单优化是用GEMM做一次矩阵广播,这样,对每个样本的Softmax Axis轴上的多个单元,只需点积一次。
II、由于top_data与bottom_diff的shape相同,最外层top_data可基于全样本来乘,这在CUDA环境中,可以有效提升瞬时并行度。
空间Softmax求导
Fully Convolutional Networks for Semantic Segmentation
Caffe中将二轴Softmax(Batchsize/Softmax)扩展到了nD轴Softmax,用于全卷积网络。
这部分代码由此paper两位作者Jonathan Long&Evan Shelhamer加入,Github的History如下:

空间Soffmax是为了Dense Pixel Prediction(密集点预测)而生的,对于一张300x500的输入图像,
一次Softmax将产生300*500=15W个Loss,这属于神经网络——像素级理解,是目前最难的CV任务。
空间Softmax取消了Softmax前的InnerProduct做的Flatten,因为必须保证空间轴信息。
一个语义分割的图示如下:

GroundTruth、Outer_Num、Inner_Num
传统机器学习中的样本单数值Label,在ComputerVision中扩展为多数值Label后,即变成GroundTruth。
Caffe中采用以下格式来规范存储与读取:
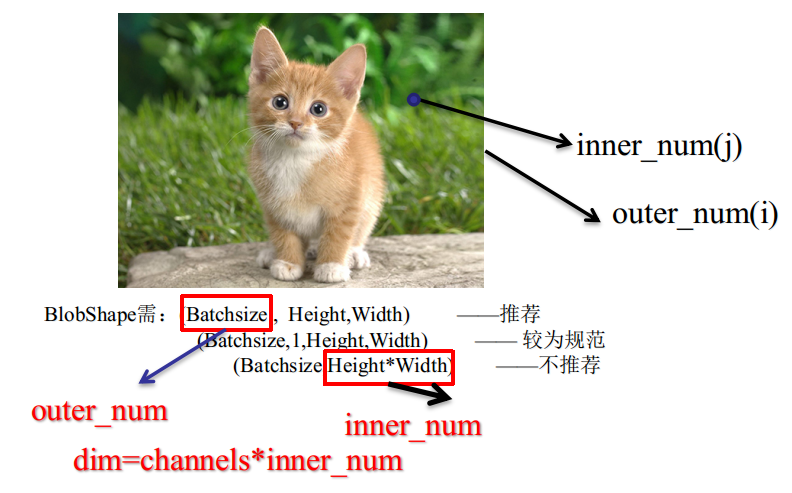
对于GroundTruth的$outer:inner=(i,j)$位置,即第$i$个样本,空间$j$位置的Label,对应的Softmax向量如下:
$PixelExample=\left\{\begin{matrix}BottomData/BottomDiff(i*dim+0*inner+j) \quad class=0 \\
\quad \\ BottomData/BottomDiff(i*dim+1*inner+j) \quad class=1\\ \\ BottomData/BottomDiff(i*dim+2*inner+j) \quad class=2\\ \\...... \\ \\ BottomData/BottomDiff(i*dim+c*inner+j) \quad class=c\end{matrix}\right.$
这样,对于outer_num数量的输入图像,就变成了outer_num*inner_num个像素样本。
值得注意的是,目前最新的研究表明,在像素级的理解中,batch_size大于1是没有意义的,会严重减慢收敛速度。
输入单张图像时,SGD做密集点预测,不会导致偏离最终的局部最值点,因为15W的Loss近似可以看成batch_size=15,0000
空间Softmax(without GroundTruth)
从上节可知,空间轴(e.g. Height/Width)的引入,可看成是倍化了batch_size轴。
故在SoftmaxLayer中,对单样本图像的输入,需要多引入一次循环模拟多样本,循环量即inner_num。
对于泛型Softmax中的点积运算,由计算单点积值,需要变化至求一组$TopData \bullet TopDiff$:
同样设$outer:inner=(i,j)$,那么$j$位置的两组点积向量分别如下:
$\bullet \left\{\begin{matrix}TopData/TopDiff(i*dim+0*inner+j) \quad class=0\\ \\ .........\\ \\ TopData/TopDiff(i*dim+c*inner+j) \quad class=c\\ \end{matrix}\right.$
由于点积的元素每次都要跳跃inner_num个位置,可利用BLAS库做StridedDot运算,点积增量设为inner_num即可。
I、在GEMM矩阵广播优化中,原来只需要将单点积值广播成[classes,1]的矩阵,顺次在Softmax-Axis轴上减去,即:
从$TopDiff(i*dim)$的一段减去,由于无空间轴时,dim=classes,TopDiff的shape为[batch_size,classes],
矩阵的值恰好填充到下一样本的开头。
扩展空间轴时,则需要减去[classes,inner_num]个值,注意由于此时的shape为[batch_size,classes,inner_num],
如果你要线性覆盖,则需要先覆盖class=0的inner_num个值,所以一定要保证广播矩阵的shape为[classes,inner_num]。
然后再做一次向量减法。由于BLAS的GEMM运算支持$C=\beta C+\alpha AB $,可一步完成。
II、在最外围的top_data乘算中,由于top_data与bottom_diff的shape相同,扩展空间轴无需调整代码。
前馈网络求导概论(一)·Softmax篇的更多相关文章
- 【机器学习基础】对 softmax 和 cross-entropy 求导
目录 符号定义 对 softmax 求导 对 cross-entropy 求导 对 softmax 和 cross-entropy 一起求导 References 在论文中看到对 softmax 和 ...
- 【机器学习】BP & softmax求导
目录 一.BP原理及求导 二.softmax及求导 一.BP 1.为什么沿梯度方向是上升最快方向 根据泰勒公式对f(x)在x0处展开,得到f(x) ~ f(x0) + f'(x0)(x-x0) ...
- Deep Learning基础--Softmax求导过程
一.softmax函数 softmax用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类! 假设我们有一个数组,V,Vi表示V中的第i个元素,那么这个 ...
- 【转载】softmax的log似然代价函数(求导过程)
全文转载自:softmax的log似然代价函数(公式求导) 在人工神经网络(ANN)中,Softmax通常被用作输出层的激活函数.这不仅是因为它的效果好,而且因为它使得ANN的输出值更易于理解.同时, ...
- softmax交叉熵损失函数求导
来源:https://www.jianshu.com/p/c02a1fbffad6 简单易懂的softmax交叉熵损失函数求导 来写一个softmax求导的推导过程,不仅可以给自己理清思路,还可以造福 ...
- softmax分类器+cross entropy损失函数的求导
softmax是logisitic regression在多酚类问题上的推广,\(W=[w_1,w_2,...,w_c]\)为各个类的权重因子,\(b\)为各类的门槛值.不要想象成超平面,否则很难理解 ...
- cnn softmax regression bp求导
内容来自ufldl,代码参考自tornadomeet的cnnCost.m 1.Forward Propagation convolvedFeatures = cnnConvolve(filterDim ...
- softmax 损失函数求导过程
前言:softmax中的求导包含矩阵与向量的求导关系,记录的目的是为了回顾. 下图为利用softmax对样本进行k分类的问题,其损失函数的表达式为结构风险,第二项是模型结构的正则化项. 首先,每个qu ...
- softmax求导、cross-entropy求导及label smoothing
softmax求导 softmax层的输出为 其中,表示第L层第j个神经元的输入,表示第L层第j个神经元的输出,e表示自然常数. 现在求对的导数, 如果j=i, 1 如果ji, 2 cross-e ...
随机推荐
- jQuery中10个非常有用的遍历函数
使用jQuery,可以 很容易的选择HTML元素.但有些时候,在HTML结构较为复杂时,提炼我们选择的元素就是一件麻烦的事情.在这篇教程中,我们将探讨十种方 法去精炼和扩展我们将要操作的集合. HTM ...
- less入门
less入门 安装 首先安装node,执行命令 node install -g less安装完成后可以在任意窗口中使用lessc命令,将.less文件编译成css文件. 变量 可以像其他语言一样声明变 ...
- NOI2016滚粗记
首先明确,博主是个渣渣... 7月19日 出发啦,准备去哈尔滨,临走时爸爸迟迟不肯离去站台口,凝望着我,心理很感动..内心的压力瞬间增大2333,附候车室图片.. 在火车上怎么也睡不着2333 7月2 ...
- using namespace std 和 using std::cin
相较using std::cin使用using namespace std不会使得程序的效率变低,或者稳定性降低,只是这样作会将很多的名字引入程序,使得程序员使用的名字集合变小,容易引起命名冲突. 在 ...
- 查看机器上安装的jdk能支持多大内存
命令:java -Xmx1024m -version C:\Users\maite>java -Xmx1024m -version java version "1.8.0_31&quo ...
- check time period
/** * @author etao * @description check last time selected * @param timePeriod * @pa ...
- JS脚本语言是什么意思?
javascript,Javascript是一种浏览器端的脚本语言,用来在网页客户端处理与用户的交互,以及实现页面特效.比如提交表单前先验证数据合法性,减少服务器错误和压力.根据客户操作,给出一些提升 ...
- js实例--飞机大战
<!DOCTYPE html> <html> <head> <meta charset="utf-8"/> <title> ...
- 完全卸载AndroidStudio
一:卸载Android Studio 由于从1.5正式版直接升级到2.1的版本,整个项目构建都变得异常的慢,所以决定卸载重新安装2.0的正式版.但是Mac下使用dmg安装的app很多都是不能使用拖拽的 ...
- Android 敏感 API 的说明
从中国的国情来看,Google 的诸多产品,包括 gmail,Android 官方市场 Google Play 正处于并将长期处于访问不了的状态.国内几亿网民也要生活,于是墙内出现了“百家争鸣”的场面 ...