Requests库请求网站
安装requests库 pip install requests
1.使用GET方式抓取数据:
import requests #导入requests库 url="http://www.cntour.cn/" #需要爬取的网址
strhtml = requests.get(url); #使用GET方式,获取网页数据 print(strhtml.text) #打印html源码

2.使用POST方式抓取数据
网址:有道翻译:http://fanyi.youdao.com/
按F12 进入开发者模式,单击Network,此时内容为空,如图:
输入‘’我爱中国‘’,翻译就会出现:

单击Headers,发现请求数据的方式为POST:

将url指取出来赋值:url=‘http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule’(把_o去掉)
POST请求获取数据的方式不同于GET,POST请求数据必须构建请求头才可以,所以把Form Data中的请求参数复制出来构建新字典:

#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:XXC
import requests
import json #定义获取信息函数
def get_translate_date(word=None):
url='http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
Form_data = {
'i': '我爱中国',
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': '',
'sign': 'f293c39aa50f57d4d35eb6822f162f72',
'doctype': 'json',
'version': '2.1',
'keyfrom':'fanyi.web',
'action': 'FY_BY_REALTIME',
'typoResult': 'false',
}
#请求表单数据
response = requests.post(url,data=Form_data)
#将json格式字符串转字典
content = json.loads(response.text)
#打印翻译后的数据
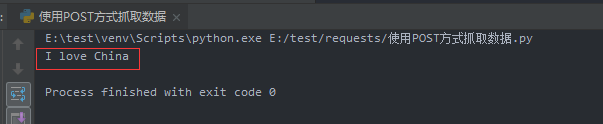
print(content['translateResult'][0][0]['tgt'])
if __name__ == '__main__':
get_translate_date('我爱中国')
Requests库请求网站的更多相关文章
- 利用requests库访问网站
1.关于requests库 函数 Response对象包含服务器返回的所有信息,也包含请求的Request信息. 访问百度二十次 import requests def getHTMLText(url ...
- 异步请求Python库 grequests的应用和与requests库的响应速度的比较
requests库是python一个优秀的HTTP库,使用它可以非常简单地执行HTTP的各种操作,例如GET.POST等.不过,这个库所执行的网络请求都是同步了,即cpu发出请求指令后,IO执行发送和 ...
- 爬虫学习--Requests库详解 Day2
什么是Requests Requests是用python语言编写,基于urllib,采用Apache2 licensed开源协议的HTTP库,它比urllib更加方便,可以节约我们大量的工作,完全满足 ...
- python中用分别用selenium、requests库实现Windows认证登录
最近在搞单位的项目,实现python自动化,结果在第一步就把我给拒之门外,查资料问大佬,问我们开发人员,从周一折腾到周五才搞定了 接下给大家分享一下 项目背景:我们系统是基于Windows平台实现的, ...
- Requests库的几种请求 - 通过API操作Github
本文内容来源:https://www.dataquest.io/mission/117/working-with-apis 本文的数据来源:https://en.wikipedia.org/wiki/ ...
- python爬虫#网络请求requests库
中文文档 http://docs.python-requests.org/zh_CN/latest/user/quickstart.html requests库 虽然Python的标准库中 urlli ...
- 4.爬虫 requests库讲解 GET请求 POST请求 响应
requests库相比于urllib库更好用!!! 0.各种请求方式 import requests requests.post('http://httpbin.org/post') requests ...
- 爬虫请求库之requests库
一.介绍 介绍:使用requests可以模拟浏览器的请求,比之前的urllib库使用更加方便 注意:requests库发送请求将网页内容下载下来之后,并不会执行js代码,这需要我们自己分析目标站点然后 ...
- 【python接口自动化】- 使用requests库发送http请求
前言:什么是Requests ?Requests 是⽤Python语⾔编写,基于urllib,采⽤Apache2 Licensed开源协议的 HTTP 库.它⽐ urllib 更加⽅便,可以节约我们⼤ ...
随机推荐
- windows运行打开服务命令的方法 :
windows运行打开服务命令的方法 : 在开始->运行,输入以下命令 1. gpedit.msc-----组策略 2. sndrec32-------录音机 3. Nslookup------ ...
- 基于maven从头搭建springMVC框架
0.准备工作 首先将eclipse和需要的插件准备好,例如maven插件,spring IDE插件. 1.建立maven下的webapp项目 1.新建一个maven项目,类型为webapp,如下图 2 ...
- 编写高质量代码改善C#程序的157个建议——建议91:可见字段应该重构为属性
建议91:可见字段应该重构为属性 字段和属性的本质区别就是属性是方法. 查看下面这个Person类型: class Person { public string Name { get; set; } ...
- solr&lucene3.6.0源码解析(一)
本文作为系列的第一篇,主要描述的是solr3.6.0开发环境的搭建 首先我们需要从官方网站下载solr的相关文件,下载地址为http://archive.apache.org/dist/luc ...
- 哇,两门学考都是A(〃'▽'〃)
看来只要拼命去搞,两个月也是可以搞出来的啊~
- Maven打包jar项目
默认情况下,使用maven打包的jar项目(执行maven install)不会包含其他包引用,要想打包为带其他项目引用的jar,需要加入插件 要得到一个可以直接在命令行通过java命令运行的JAR文 ...
- php 与java安卓客户端的查询交互
PHP 服务器端: function getids() { $this->output->set_header('Content-Type: application/json; chars ...
- Android-Observer(内容观察者)
内容提供者应用暴露的数据,是被多个其他应用访问(insert,update,delete,query),但如果L应用要查询(内容提供者应用暴露的数据),难道要开启子线程一直循环去查询 ? 答:开启子线 ...
- Transaction And Lock--事务中使用return会回滚事务吗?
事务中使用return会回滚事务吗? 答案:不会,如果在事务中没有显示提交或回滚事务边return,事务不会被提交或回滚,在C#中,如果没有使用连接池,则事务在连接断开和销毁时被强制回滚,如果使用连接 ...
- Centos 固定ip
vim /etc/sysconfig/network-scripts/ifcfg-eth0 BOOTPROTO="static" ONBOOT=yes IPADDR=192.168 ...