05_Flume_timestamp interceptor实践
1、目标场景
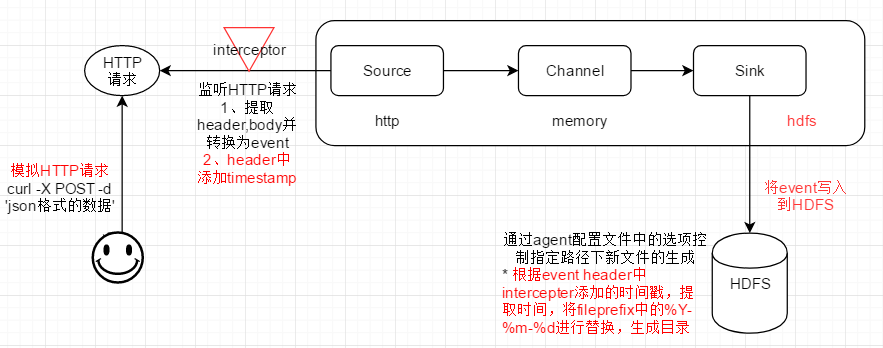
2、Flume Agent配置
# specify agent,source,sink,channel
a1.sources = r1
a1.sinks = k1
a1.channels = c1 # handler将根据JSON规则,提取出header、body,然后生成flume event的header、body
a1.sources.r1.type = http
a1.sources.r1.bind = master
a1.sources.r1.port = 6666
a1.sources.r1.handler = org.apache.flume.source.http.JSONHandler # interceptor将在flume event的header中增加时间戳
# 该interceptor将在flume event的header中增加当前系统时间
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
# 如果flume event的header中已经有timestamp,是否保留;False表示不保留
a1.sources.r1.interceptors.i1.preserveExisting= false # hdfs sink
a1.sinks.k1.type = hdfs
# sink将会基于flume event头部的时间戳来提取年月日信息,在HFDS上创建目录
a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/%Y-%m-%d/ # 如果event的header中没有时间戳,就要打开下面的配置
# a1.sinks.k1.hdfs.useLocalTimeStamp = true a1.sinks.k1.hdfs.filePrefix = interceptor-
a1.sinks.k1.hdfs.fileType=DataStream
a1.sinks.k1.hdfs.wirteFormat = Text
a1.sinks.k1.hdfs.rollSize =
a1.sinks.k1.hdfs.rollCount =
a1.sinks.k1.hdfs.rollInterval = # channel, memory
a1.channels.c1.type = memory
a1.channels.c1.capacity =
a1.channels.c1.transactionCapacity = # bind source,sink to channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
3、curl命令,模拟发送HTTP请求(POST方法)
# curl -X POST -d '[{"headers":{}, "body":"timestamp teset 001"}]' http://master:6666
说明: -X POST 表示使用HTTP POST方法,将 -d 指明的 json格式的数据,发送给master的6666端口

4、检查HDFS上基于event时间戳信息的目录是否成功创建
1)第一个curl命令运行后,flume aget打印日志,提示基于时间戳的HDFS目录正在创建

2)HDFS上的目录

3)flume event body中的数据,被保存到该目录在的HDFS文件中
05_Flume_timestamp interceptor实践的更多相关文章
- 07_Flume_regex interceptor实践
实践一:regex filter interceptor 1.目标场景 regex filter interceptor的作用: 1)将event body的内容和配置中指定的正则表达式进行匹配2)如 ...
- springmvc学习笔记--Interceptor机制和实践
前言: Spring的AOP理念, 以及j2ee中责任链(过滤器链)的设计模式, 确实深入人心, 处处可以看到它的身影. 这次借项目空闲, 来总结一下SpringMVC的Interceptor机制, ...
- 【转】Flume(NG)架构设计要点及配置实践
Flume(NG)架构设计要点及配置实践 Flume NG是一个分布式.可靠.可用的系统,它能够将不同数据源的海量日志数据进行高效收集.聚合.移动,最后存储到一个中心化数据存储系统中.由原来的Fl ...
- Spring 实践 -拾遗
Spring 实践 标签: Java与设计模式 Junit集成 前面多次用到@RunWith与@ContextConfiguration,在测试类添加这两个注解,程序就会自动加载Spring配置并初始 ...
- 【SSH2(理论+实践)】--Hibernate步步(一个)
前几个博客讨论SSH2该框架Struts,它代表层,集成封装.和使用WebWork作为核心处理,依赖映射是它的处理核心.在使用时需要Struts.xml配置相应Action和Interceptor够完 ...
- 【DDD】领域驱动设计实践 —— UI层实现
前面几篇blog主要介绍了DDD落地架构及业务建模战术,后续几篇blog会在此基础上,讲解具体的架构实现,通过完整代码demo的形式,更好地将DDD的落地方案呈现出来.本文是架构实现讲解的第一篇,主要 ...
- Chloe.ORM框架应用实践
Chloe.ORM 是国人开发的一款数据库访问组件,很是简单易用.目前支持四种主流数据库:SqlServer.MySQL.Oracle,以及Sqlite,作者为这四种数据库划分出了各自对应的组件程序集 ...
- mybatis 3.x源码深度解析与最佳实践(最完整原创)
mybatis 3.x源码深度解析与最佳实践 1 环境准备 1.1 mybatis介绍以及框架源码的学习目标 1.2 本系列源码解析的方式 1.3 环境搭建 1.4 从Hello World开始 2 ...
- Spring MVC 实践 - Component
Spring MVC 实践 标签 : Java与Web Converter Spring MVC的数据绑定并非没有任何限制, 有案例表明: Spring在如何正确绑定数据方面是杂乱无章的. 比如: S ...
随机推荐
- 【spring mvc】application context的生命周期
上一次讲application context中bean的生命周期,后面贴了一部分代码,但根本没理解代码意思,有幸在博客园看到一篇关于这部分的代码解析,特别长,特此做了一些整理笔记,并附上链接:htt ...
- jmeter测试手机号码归属地
jmeter测试手机号码归属地接口时,HTTP请求有以下两种书写方法: 1.请求和参数一同写在路径中 2.参数单独写在参数列表中 请求方法既可以使用GET方法又可以使用POST方法. 注意:“服务器名 ...
- 【剑指offer】用两个栈实现队列
一.题目: 用两个栈来实现一个队列,完成队列的Push和Pop操作. 队列中的元素为int类型. 二.思路: 两个栈A,B,A负责进栈,B负责出栈,进栈很容易,A中添加即可,出栈需要从B里出,所以要先 ...
- Chrome插件汇总
Chrome浏览器可以增加很多插件,帮助我们更方便地使用. 1 重新定位新标签页 名字:Infinity.crx 官网:http://www.infinitynewtab.com/ 效果图如下: ...
- OCR学习及tesseract的一些测试
最近接触OCR,先收集一些资料,包括成熟软件.SDK.流行算法. 1. 一个对现有OCR软件及SDK的总结,比较全面,包括支持平台.编程语言.支持字体语言.输出格式.相关链接等 http://en.w ...
- MVC 页面传参到另一个页面
写法一: @{ViewData["partData"]="哇哈哈哈哈";} @{Html.RenderPartial("~/Views/Home ...
- python 使用for循环简单爬取图片(1)
现在的网站大多做了反爬处理,找一个能爬的网站还真不容易. 下面开始一步步实现: 1.简单爬录目图片 import urllib.request import re def gethtml(url): ...
- cf428c 模拟题
这题说的是给了 n个数然后又 k次 的交换任意位置的 数字的机会 计算最长的连续子序列的和 这要撸 模拟整个 过程 并不能就是算最长的递增序列 如果只是 找最长的 和序列的 话 会存在 很多问题 ...
- SQL语句--查询任务
SELECT 目标字段1, 目标字段2 FROM 目标表WHERE ID IN(SELECT 外键 FROM 外键所在表WHERE 提供数据字段 IN(提供数据第一条, 提供数据第二条, ))
- NIO_2
导语 缓冲器的设计的是新IO模型中最基础的一部分.因为新IO模型中要求所有的IO操作都需要进行缓冲.在新的IO模型中,不再向输出流写入数据和从数据流中读取数据了,而是要从缓冲区中读写数据.缓冲区可是是 ...