Spark standalone运行模式

Spark Standalone 部署配置
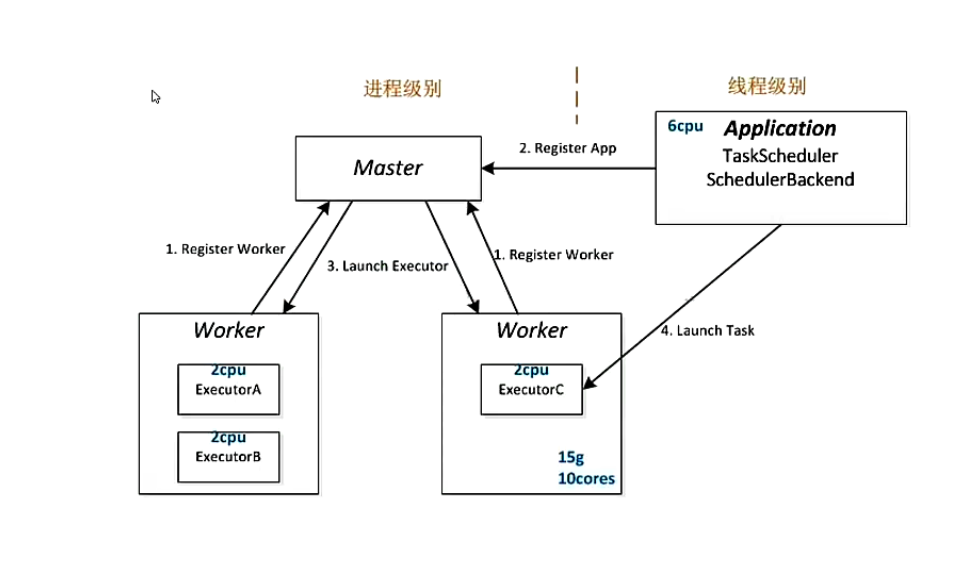
Standalone架构
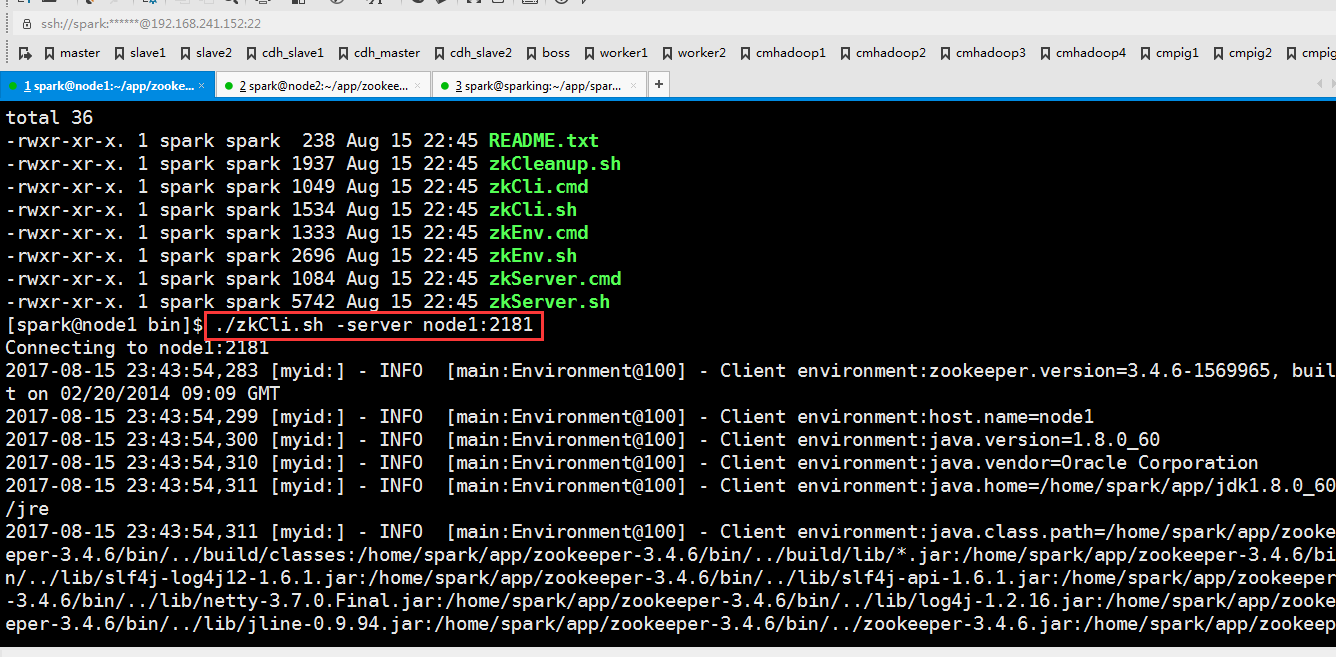
手工启动一个Spark集群
https://spark.apache.org/docs/latest/spark-standalone.html
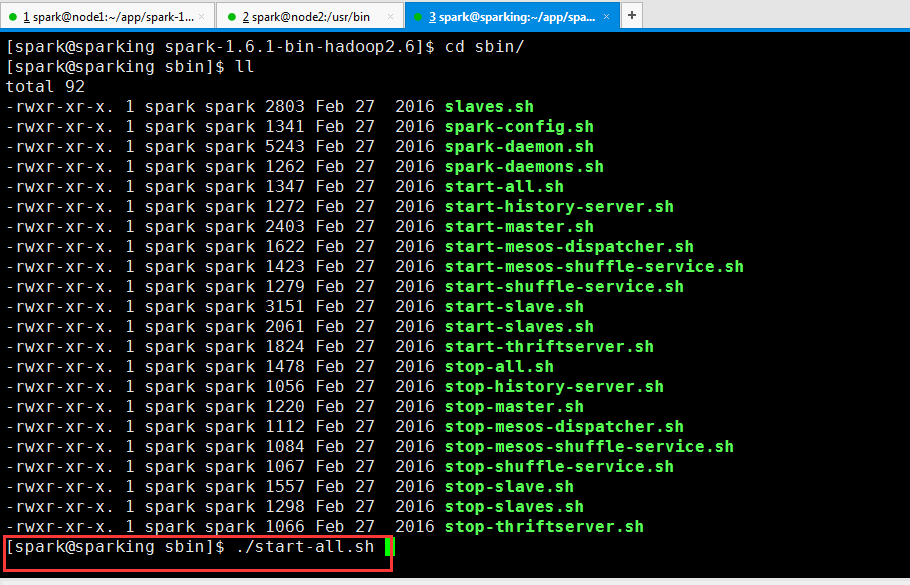
通过脚本启动集群


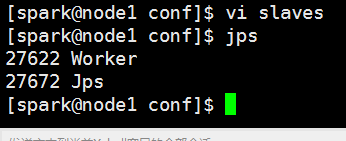
编辑slaves,其实把worker所在节点添加进去

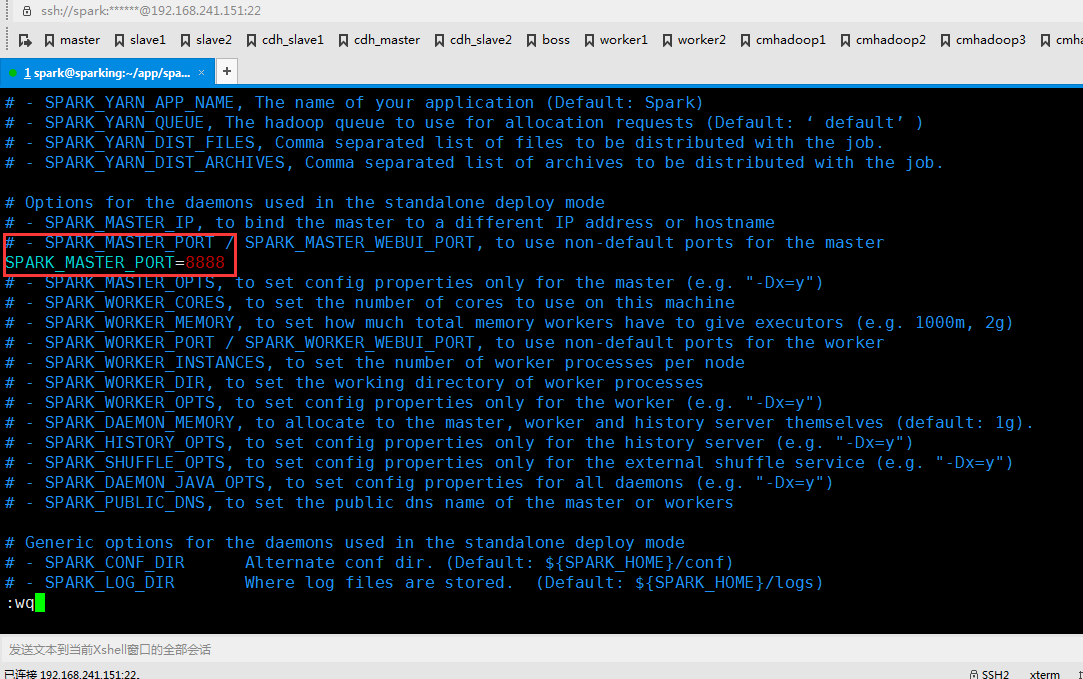
配置spark-defaults.conf


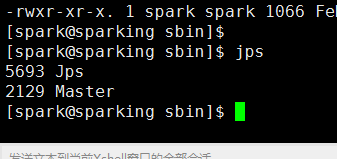
启动集群(我这里是三节点集群)

在浏览器打开页面
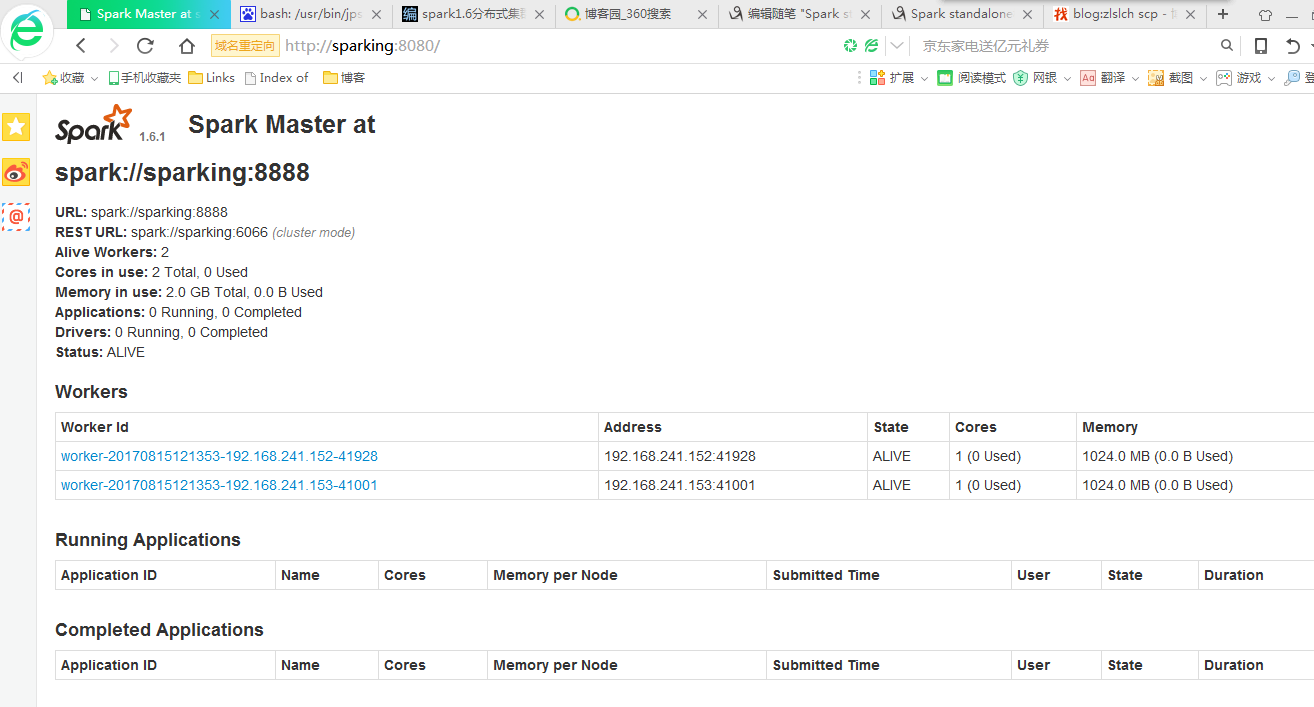
修改 spark-env.sh 文件
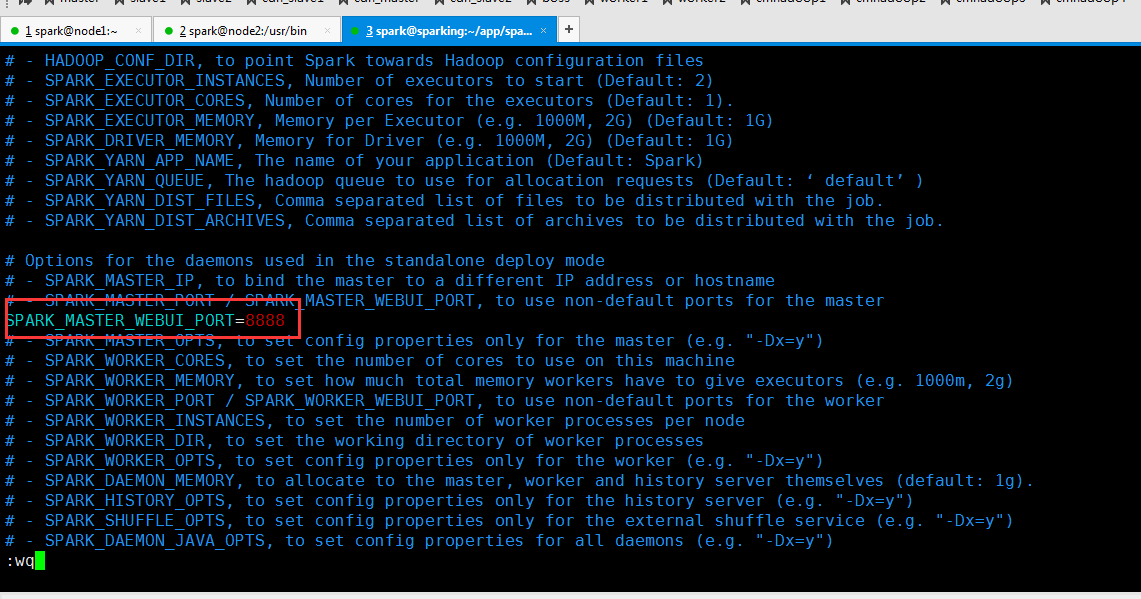
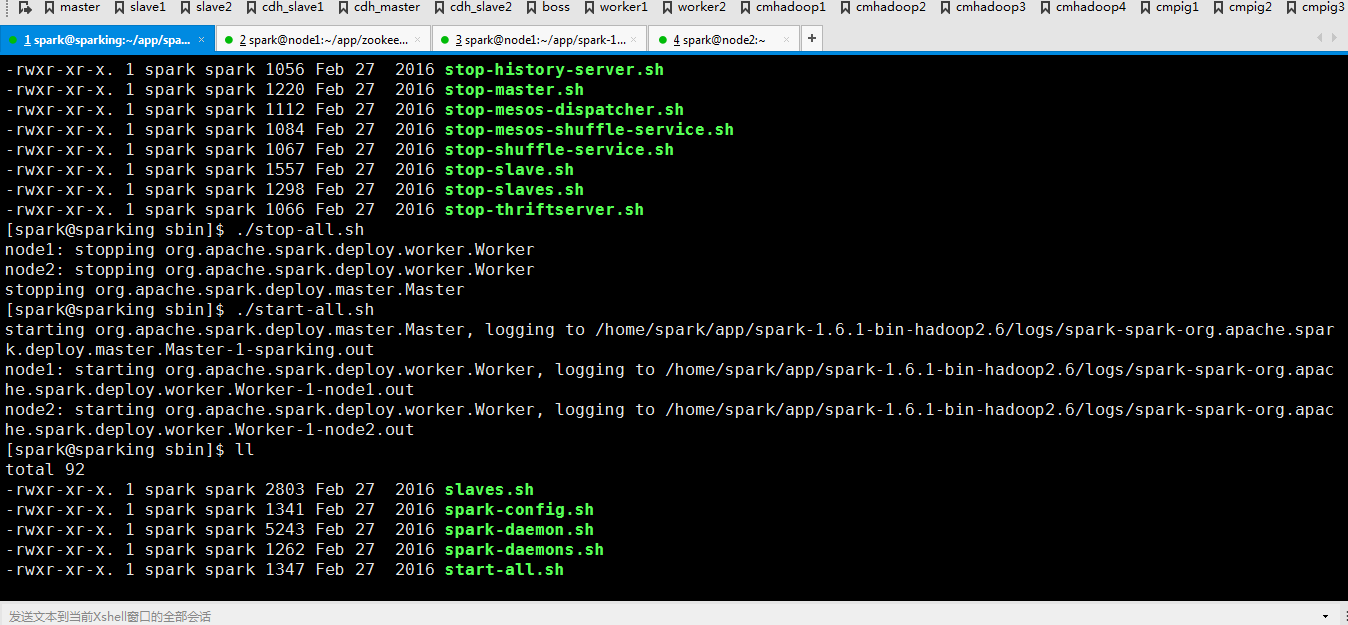
先停止
在重新启动一下
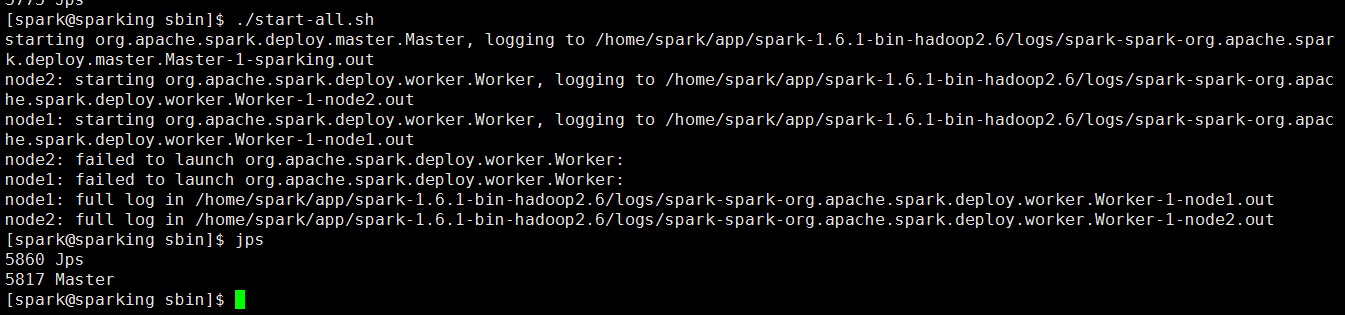
再次访问网页
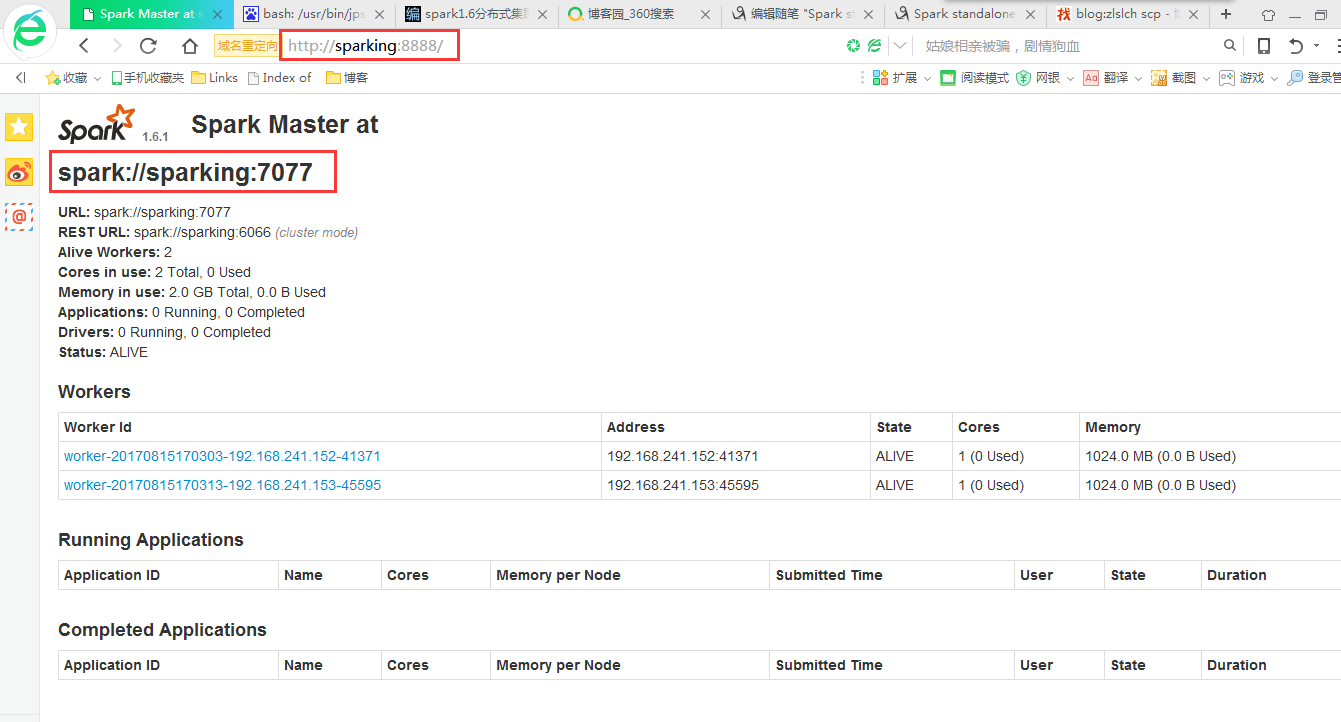
下面跑一个Job实例
./spark-submit --master spark://sparking:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.1-hadoop2.6.0.jar
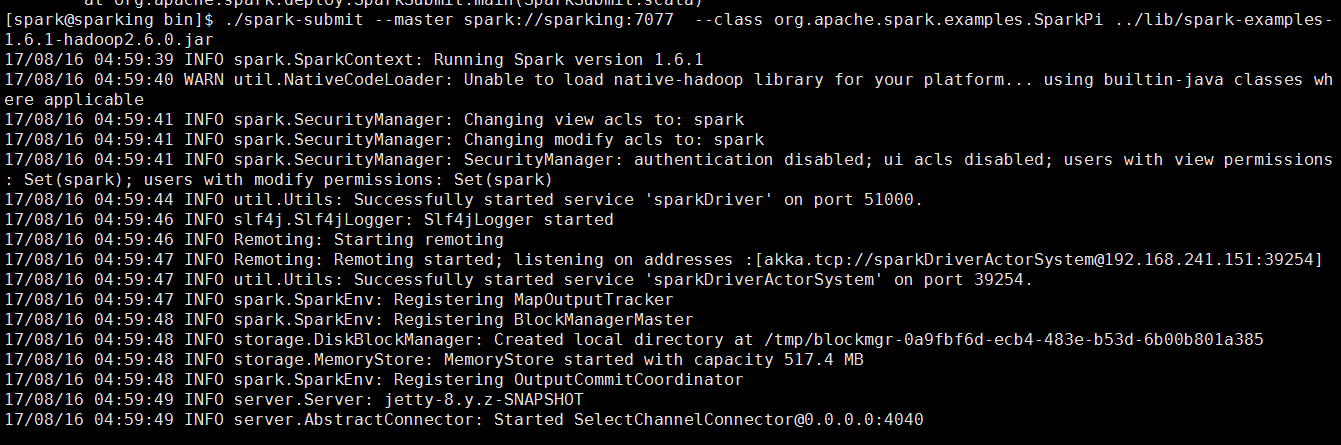
从过程反馈信息可以看出来计算Pi的值
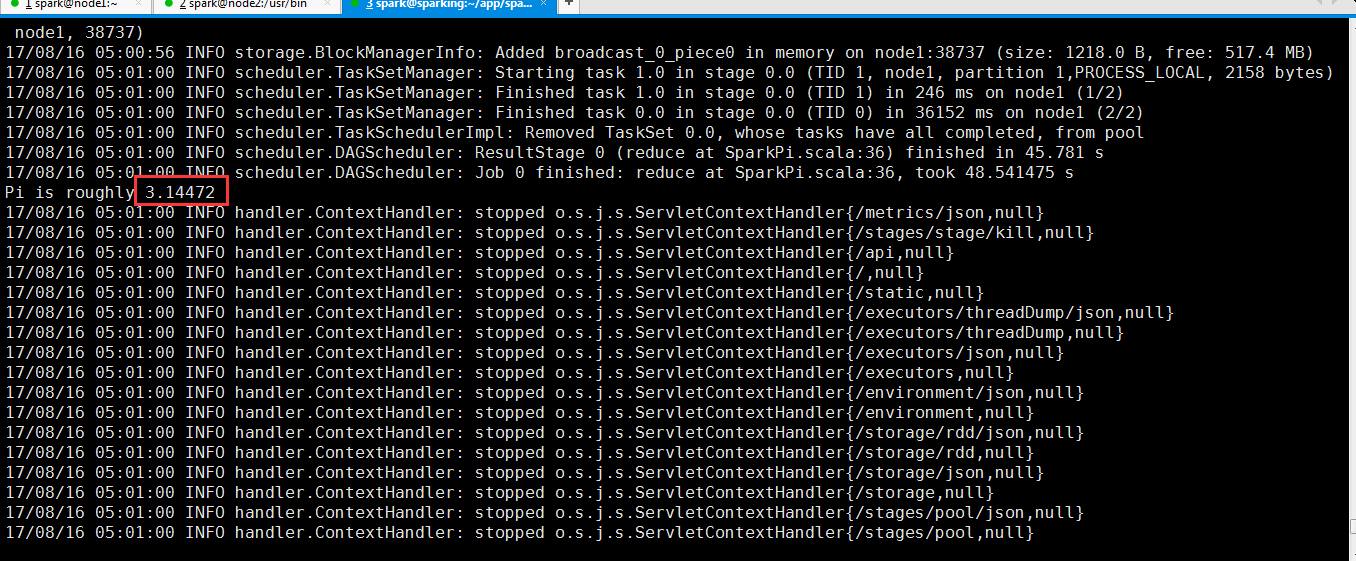
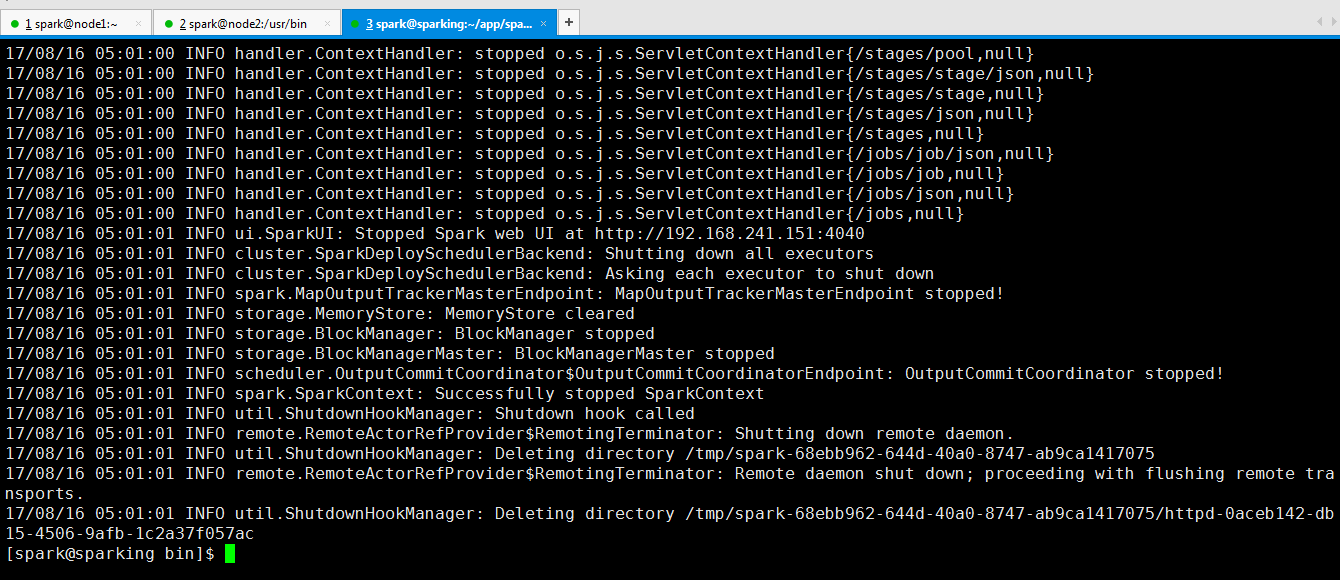
可以看到运行完成了。
从页面也可以看出来
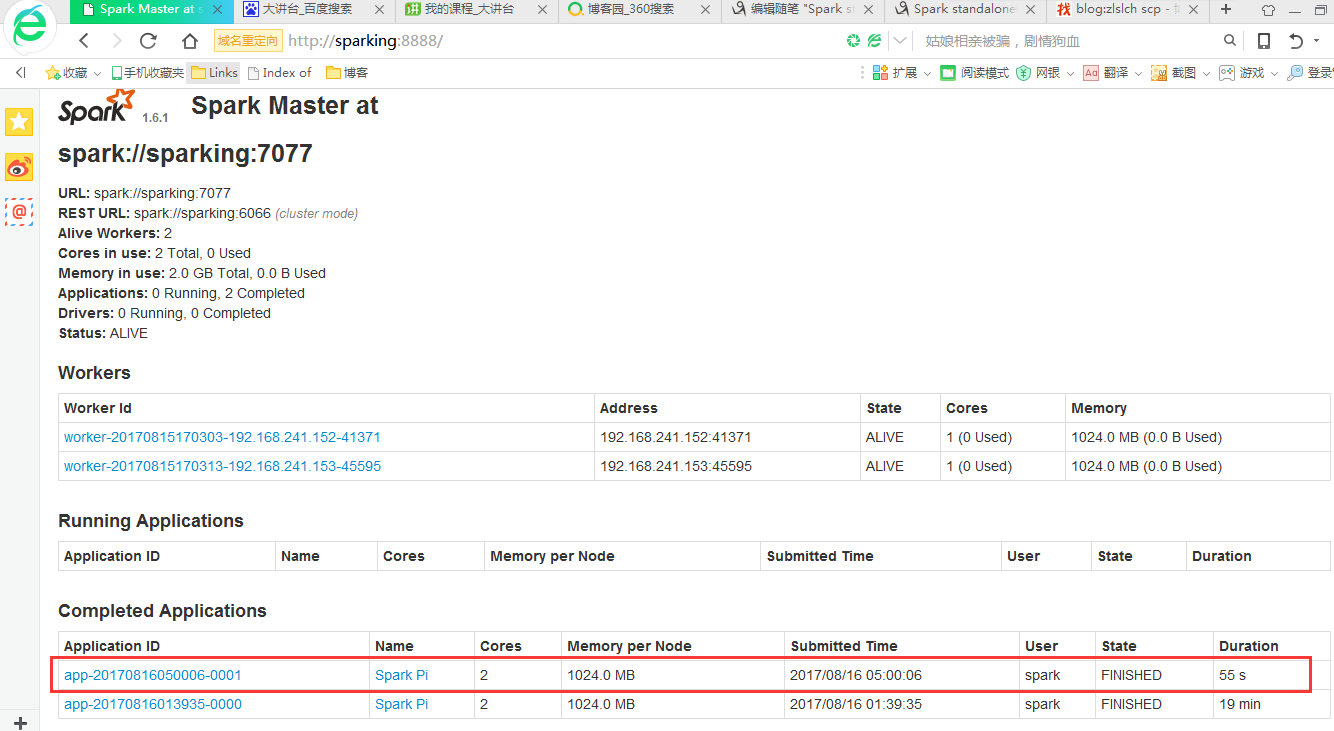
Spark Standalone HA

官方参考地址
https://spark.apache.org/docs/latest/spark-standalone.html#high-availability

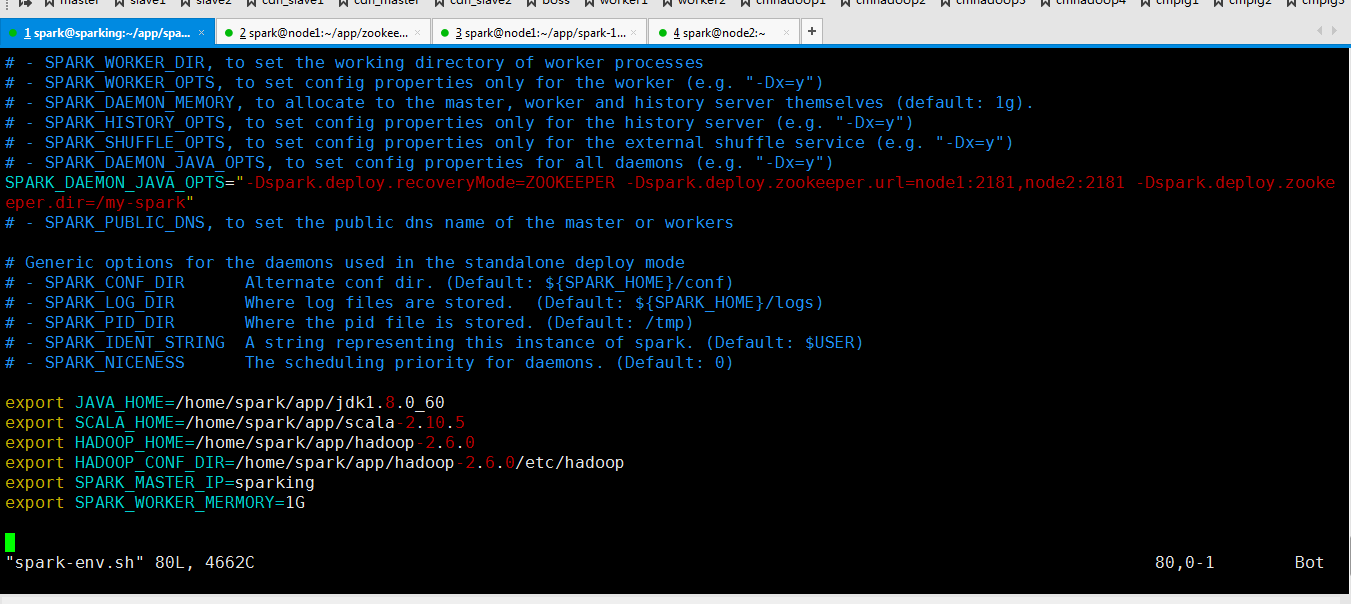
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181 -Dspark.deploy.zookeeper.dir=/my-spark"
默认是这样连接的。
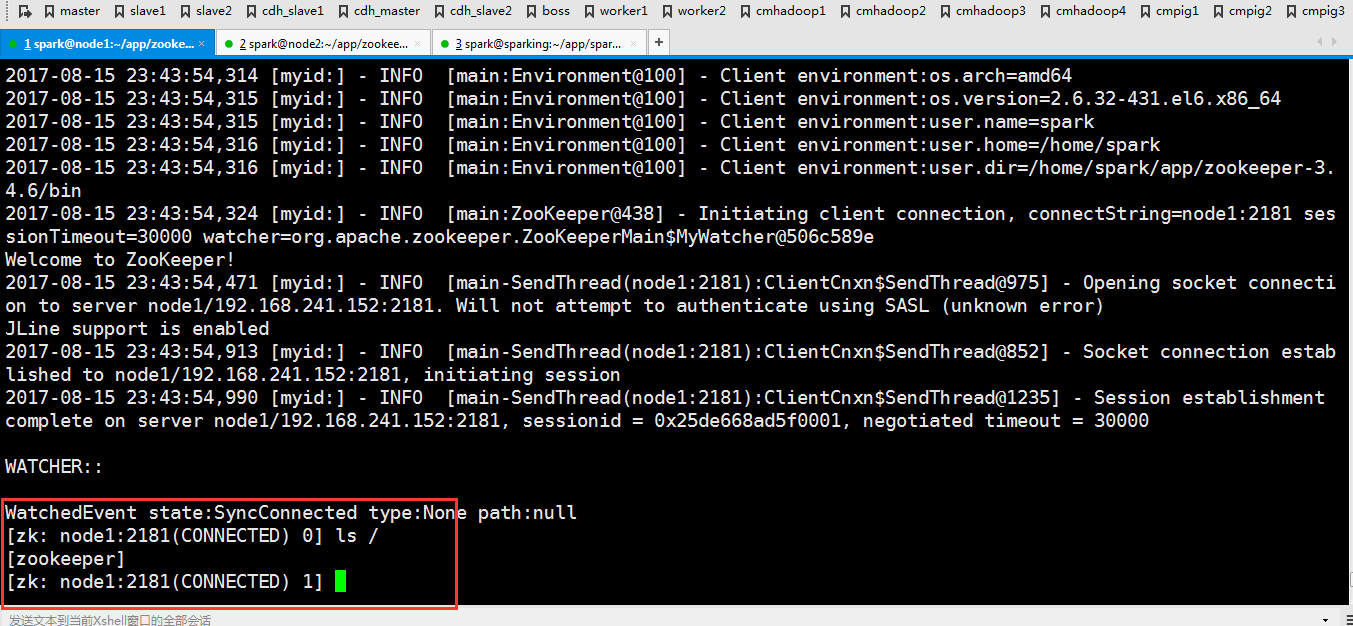
因为刚才修改了文件,现在把修改好的文件分发到另外两个节点去

scp -r spark-env.sh spark@node1:/home/spark/app/spark-1.6.-bin-hadoop2./conf/ scp -r spark-env.sh spark@node2:/home/spark/app/spark-1.6.-bin-hadoop2./conf/
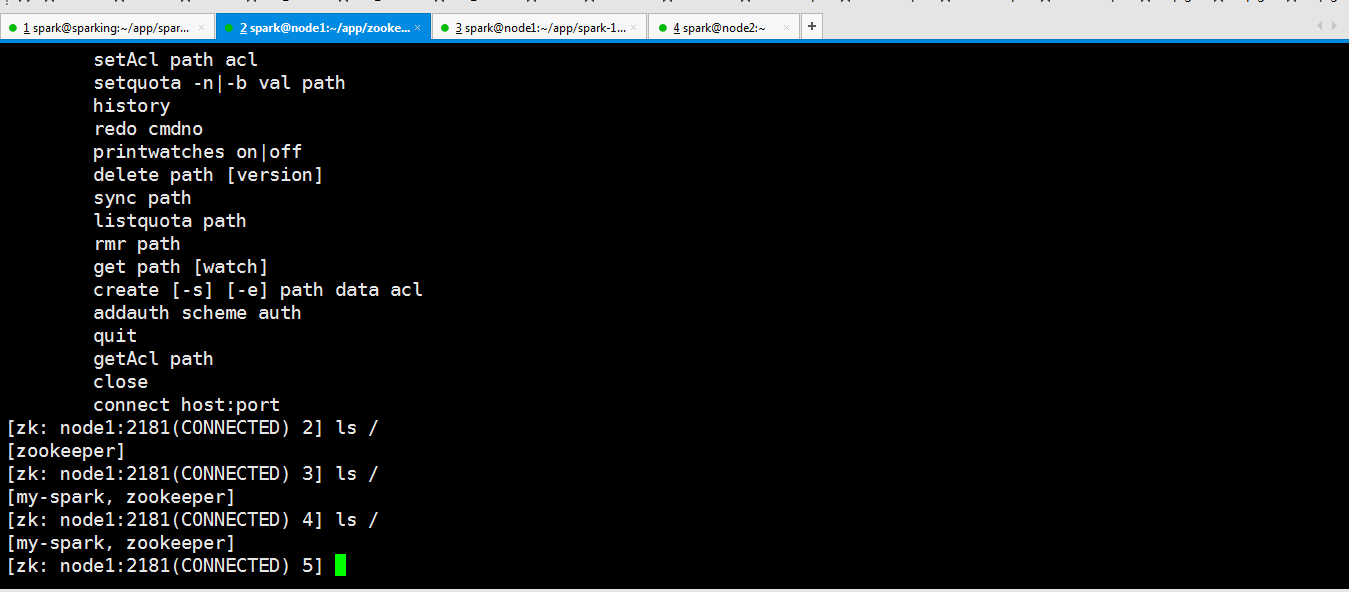
然后重新启动一下
可以看到起来了
Spark Standalone 运行架构解析
Spark基本工作流程
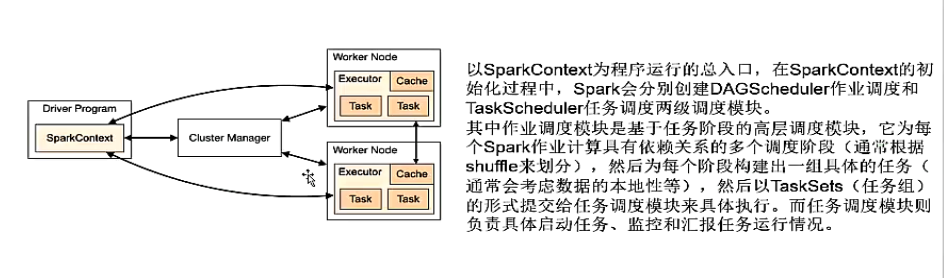
Spark Local模式

Spark Local cluster 模式

Spark standalone 模式

Spark standalone 详细过程解析
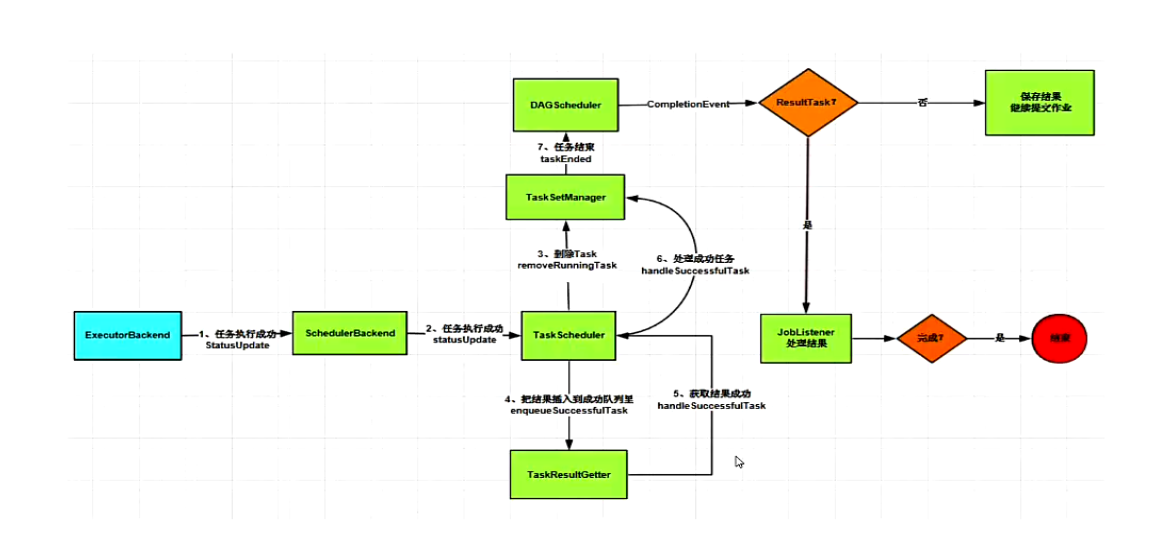
Spark standalone 模式下运行WordCount
在IDEA里把写好的wordcount程序打包(我这里用的是scala版本写的)
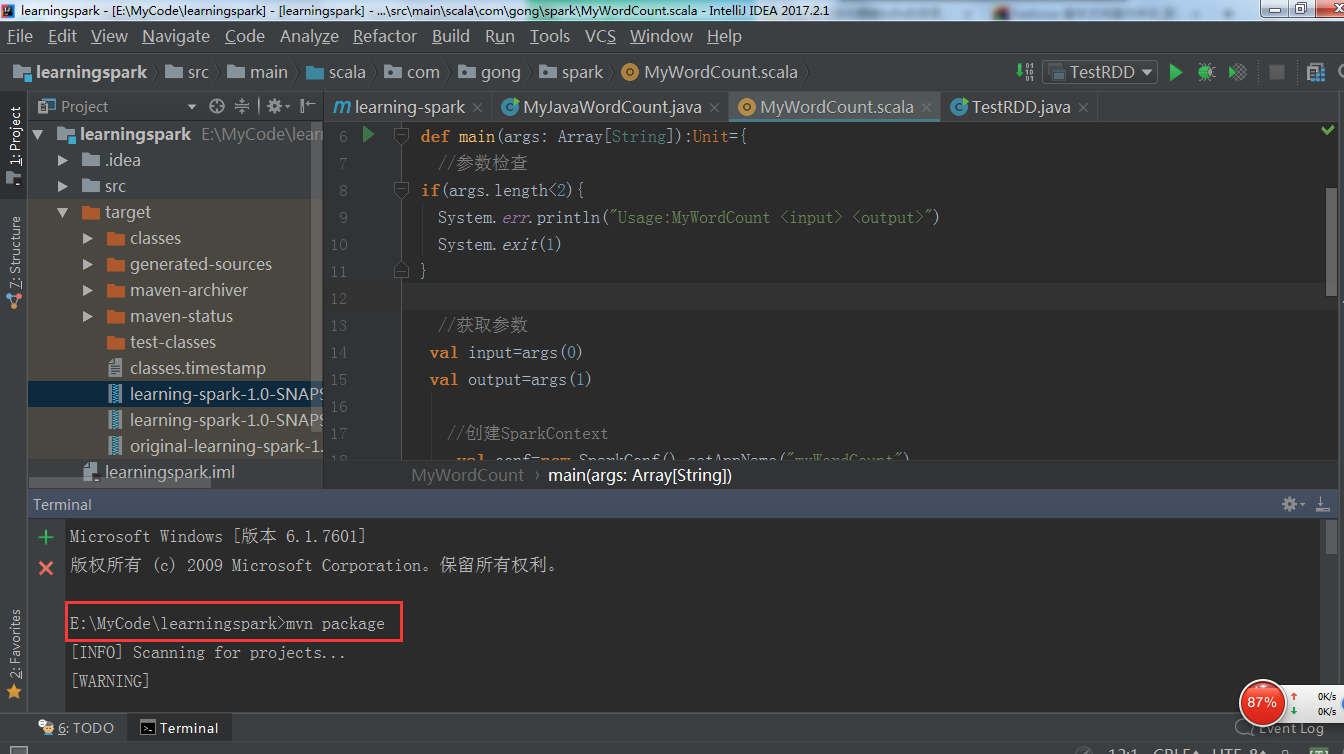
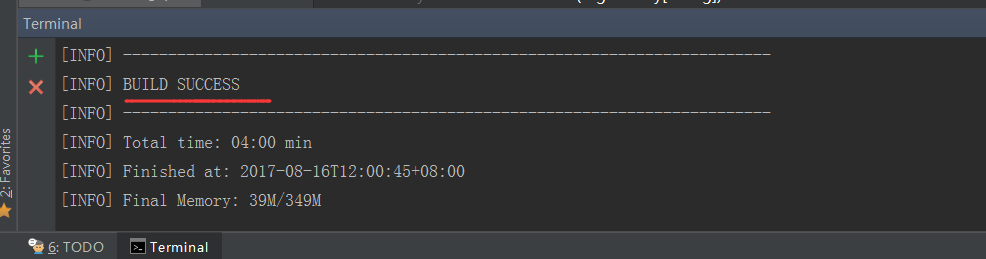
可以看到打包成功!
参考代码
package com.gong.spark
import org.apache.spark.{SparkConf, SparkContext}
object MyWordCount {
def main(args: Array[String]):Unit={
//参数检查
if(args.length<){
System.err.println("Usage:MyWordCount <input> <output>")
System.exit()
}
//获取参数
val input=args()
val output=args()
//创建SparkContext
val conf=new SparkConf().setAppName("myWordCount")
val sc=new SparkContext(conf)
//读取数据
val lines=sc.textFile(input)
//进行相关计算
val resultRdd=lines.flatMap(_.split(" ")).map((_,)).reduceByKey(_+_)
//保存结果
resultRdd.saveAsTextFile(output)
sc.stop()
}
}
把包上传到集群上(用rz命令就可以了)
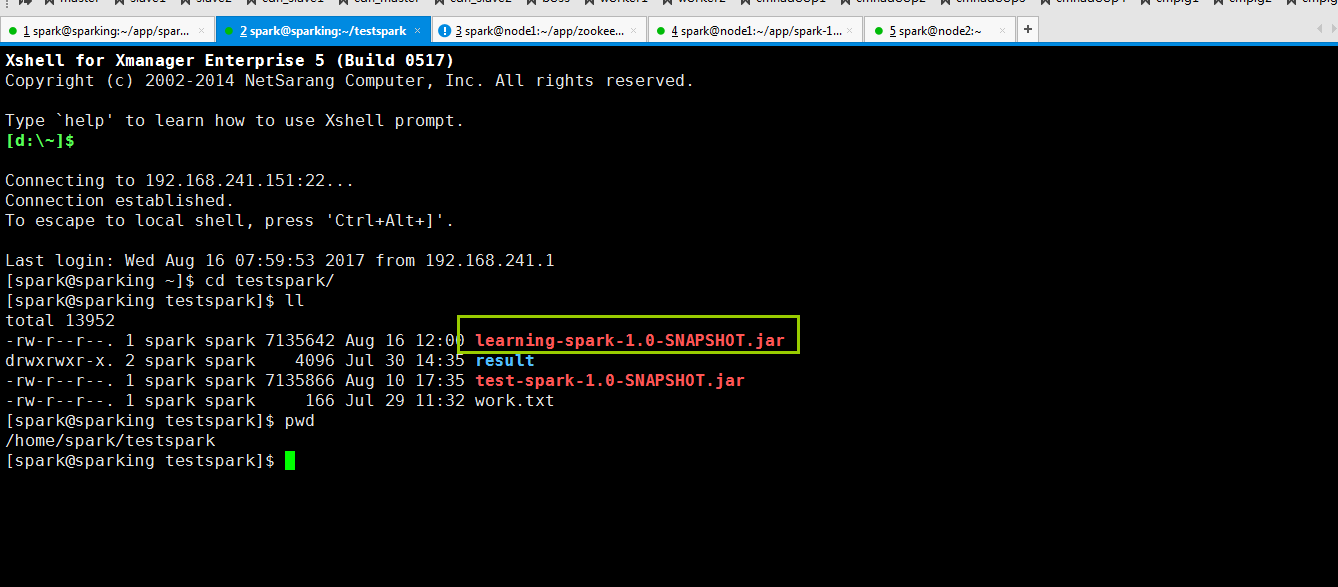
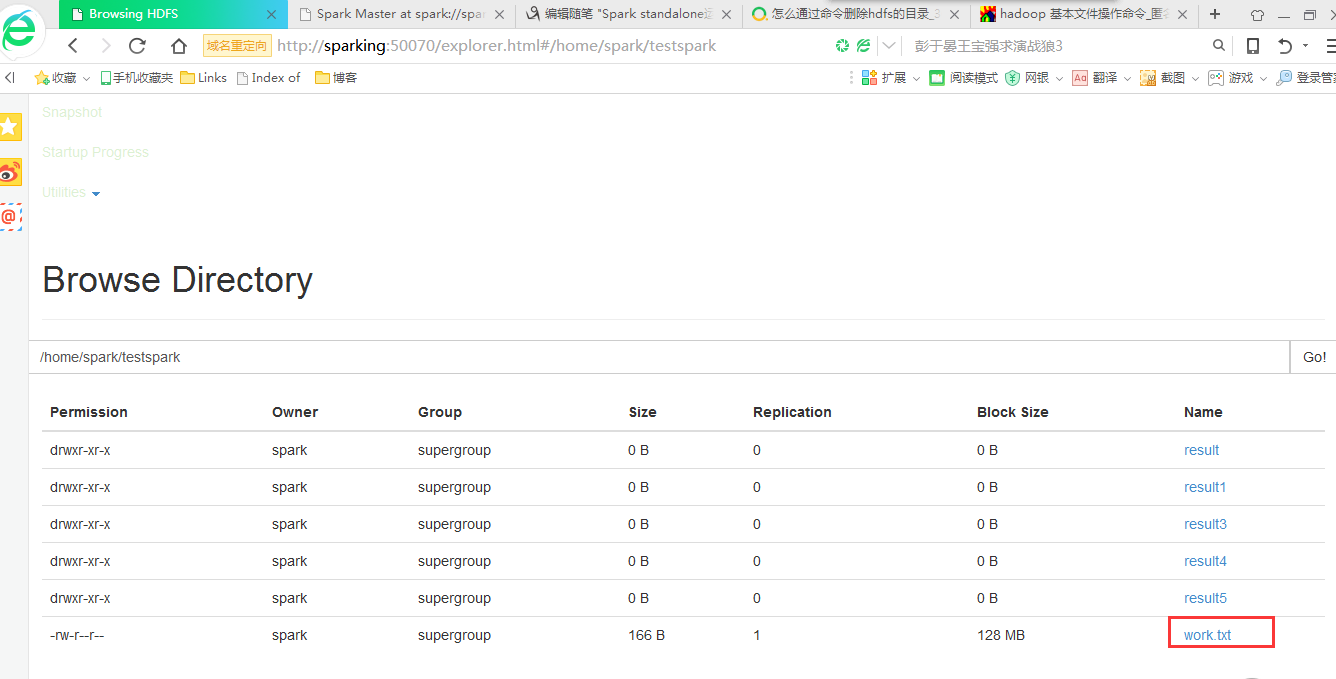
在这之前我已经在我的hdfs上上次了work.txt文件
下面在集群里跑一下程序
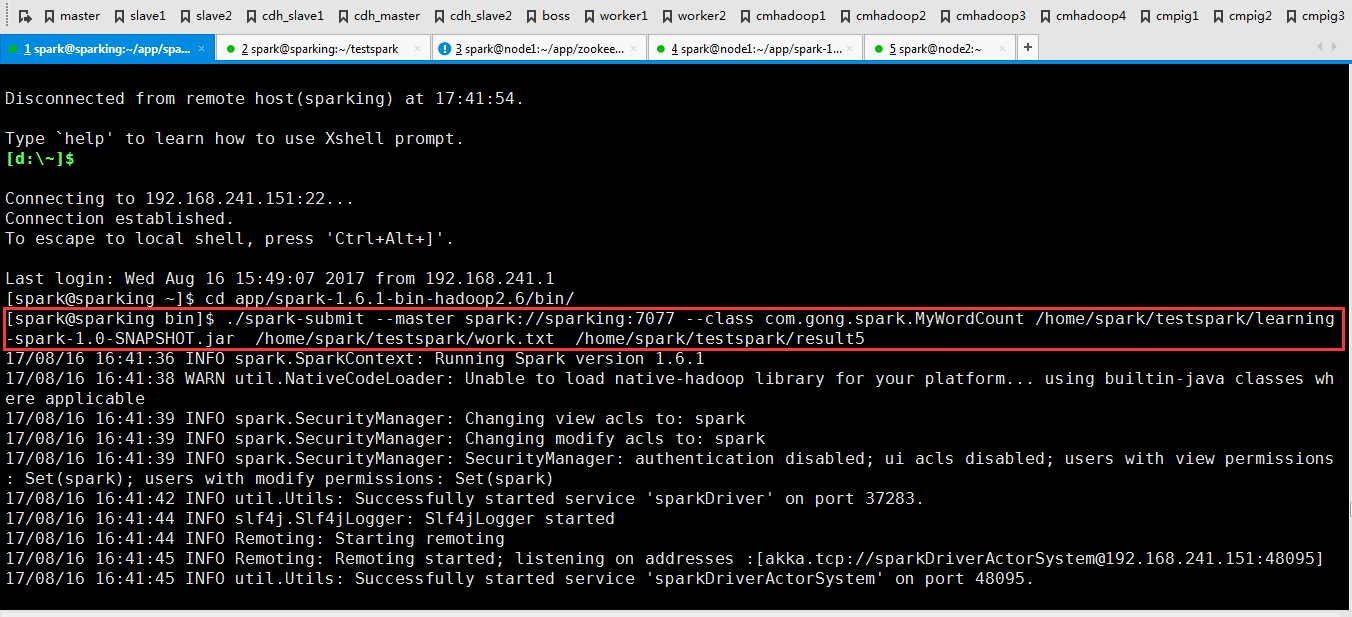
./spark-submit --master spark://sparking:7077 --class com.gong.spark.MyWordCount /home/spark/testspark/learning-spark-1.0-SNAPSHOT.jar /home/spark/testspark/work.txt /home/spark/testspark/result5
可以看到运行完成了(在这里我说下运行这个程序需要网络良好才可以,因为我的实验室的网络非常差,所以我试了好多次)!!!!!
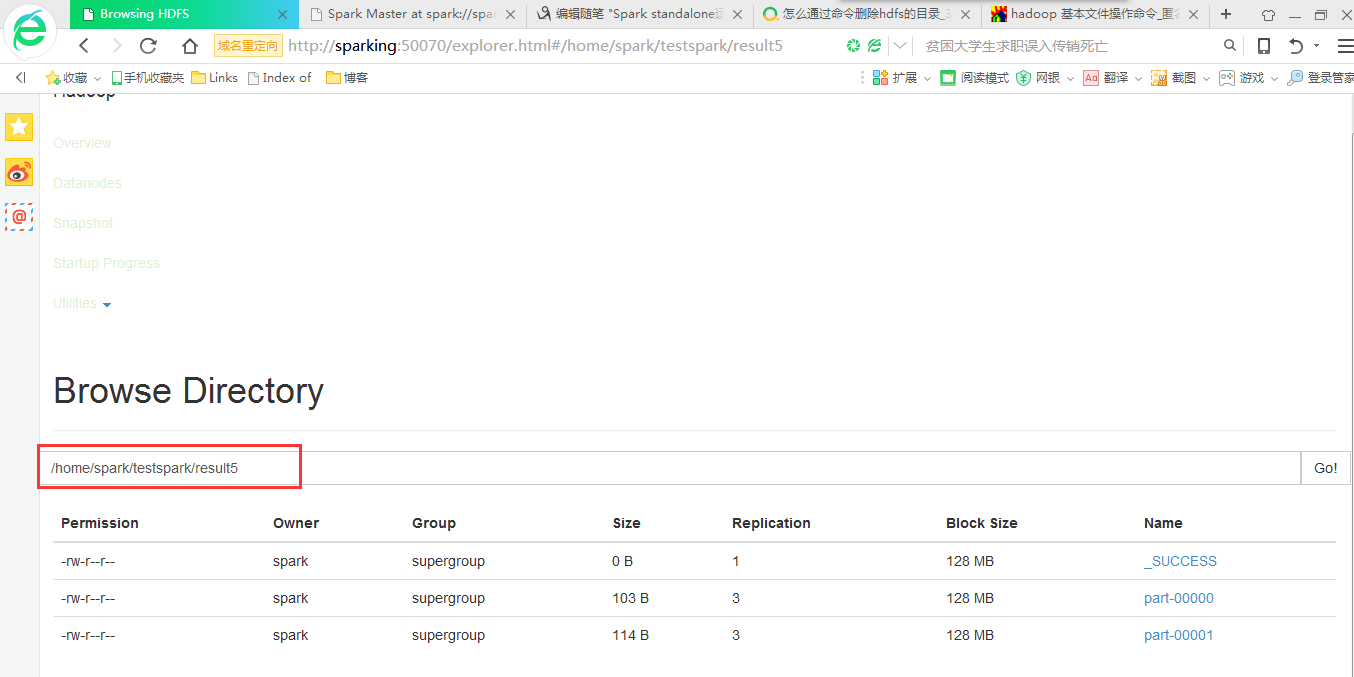
在hdfs上查看运行结果
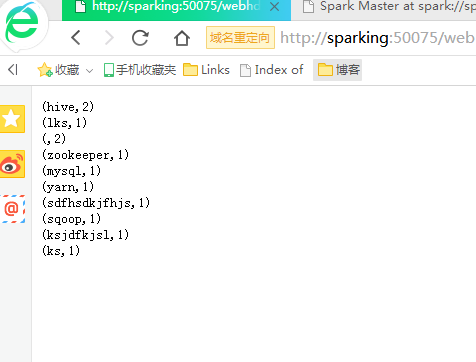
Spark standalone运行模式的更多相关文章
- Spark standalone运行模式(图文详解)
不多说,直接上干货! 请移步 Spark standalone简介与运行wordcount(master.slave1和slave2) Spark standalone模式的安装(spark-1.6. ...
- 【原】Spark不同运行模式下资源分配源码解读
版权声明:本文为原创文章,未经允许不得转载. 复习内容: Spark中Task的提交源码解读 http://www.cnblogs.com/yourarebest/p/5423906.html Sch ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
- 五、standalone运行模式
在上文中我们知道spark的集群主要有三种运行模式standalone.yarn.mesos,其中常被使用的是standalone和yarn,本文了解一下什么是standalone运行模式,它的运行流 ...
- Spark的运行模式(1)--Local和Standalone
Spark一共有5种运行模式:Local,Standalone,Yarn-Cluster,Yarn-Client和Mesos. 1. Local Local模式即单机模式,如果在命令语句中不加任何配置 ...
- Spark多种运行模式
1.测试或实验性质的本地运行模式(单机) 该模式被称为Local[N]模式,是用单机的多个线程来模拟Spark分布式计算,通常用来验证开发出来的应用程序逻辑上是否有问题. 其中N代表可以使用N个线程, ...
- Spark的运行模式(2)--Yarn-Cluster和Yarn-Client
3. Yarn-Cluster Yarn是一种统一资源管理机制,可以在上面运行多种计算框架.Spark on Yarn模式分为两种:Yarn-Cluster和Yarn-Client,前者Driver运 ...
- spark的运行模式
1.local(本地模式) 单机模式,通常用来测试 将spark应用以多线程方式,直接运行在本地 本地模式可以启动多个executor不过上限不能超过cpu数 2.standalone(独立模式) 独 ...
- 017 Spark的运行模式(yarn模式)
1.关于mapreduce on yarn 来提交job的流程 yarn=resourcemanager(RM)+nodemanager(NM) client向RM提交任务 RM向NM分配applic ...
随机推荐
- Mitmproxy介绍及Python拦截代理
使用 mitmproxy + python 做拦截代理 转自:https://blog.wolfogre.com/posts/usage-of-mitmproxy/ 本文是一个较为完整的 mitm ...
- HDU 3046
http://acm.hdu.edu.cn/showproblem.php?pid=3046 典型的最小割模型 #include <iostream> #include <cstdi ...
- TI AM335x Linux MUX hacking
/********************************************************************************************* * TI ...
- HDOJ 1061 Rightmost Digit
找出数学规律 原题: Rightmost Digit Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Ja ...
- Linux基础和网络管理上机试题 - imsoft.cnblogs
一.(使用at命令实现任务的的自动化,要求用一条条的指令完成) 找出系统中任何以txt为后缀名的文档,并且进行打印.打印结束后给用户foxy发出邮件通知取件.指定时间为十二月二十五日凌晨两点 ...
- 关于凑数问题的dfs
https://www.nowcoder.com/acm/contest/42/F 首先由于是单一解问题,所以使用返回值类型为bool的dfs 然后为了保证dfs的效率性,应该把加数dfs放在前面,不 ...
- 在windows下制作mac os x的启动安装U盘
前几天有幸用了下Macbook pro,可在给它装win 7系统时,无知而又手贱地在windows系统下分区了:( 然后再重启就找不到Mac os x,只有win 7了.可进win 7也不正常,直接给 ...
- Sublime Text3 使用
注: 1.绿色版的某些插件有问题,导致某些插件无法使用,而且无法删除和安装,需要删除Data/Cache目录,重新安装无法使用的插件 2.绿色版无法编译python,可使用安装版安装sublime后, ...
- device public set
backgroud: our dvertiser provide on device list of idfa to show ad to target audience,however none ...
- bat计算两个时间差
这个是脚本代码[保存为etime.bat放在当前路径下即可: 免费内容: :etime <begin_time> <end_time> <return>rem 所测 ...