Hawk 3. 网页采集器
1.基本入门
1. 原理(建议阅读)
网页采集器的功能是获取网页中的数据(废话)。通常来说,目标可能是列表(如购物车列表),或是一个页面中的固定字段(如JD某商品的价格和介绍,在页面中只有一个)。因此需要设置其读取模式。传统的采集器需要编写正则表达式,但方法过分复杂。
如果认识到html是一棵树,只要找到了承载数据的节点即可。XPath就是一种在树中描述路径的语法。指定XPath,就能搜索到树中的节点。
有关XPath的详细信息,建议参考网上相关章节。
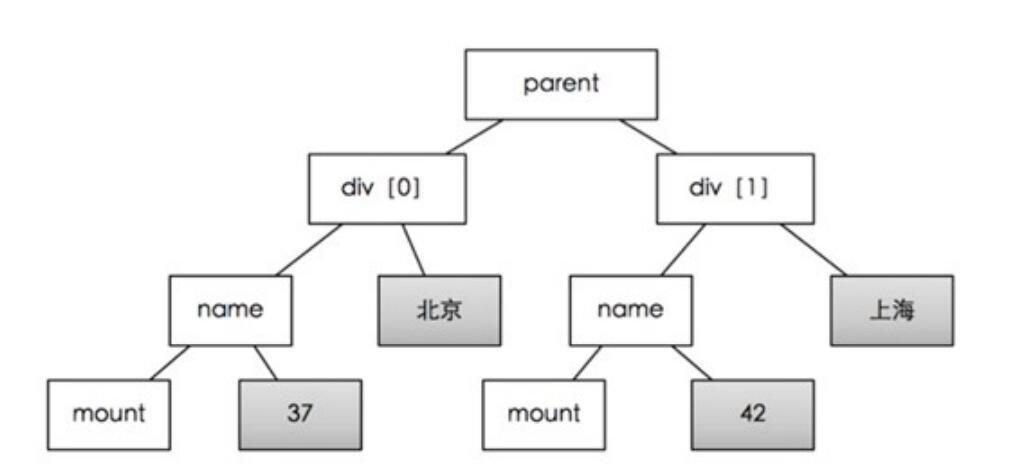
手工编写XPath也很复杂,因此软件可以通过关键字,自动检索XPath,提供关键字,软件就会从树中递归搜索包含该数据的叶子节点。因此关键字最好是在页面中独一无二的。
如上图所示,只要提供“北京”和“42”这两个关键字,就能找到parent节点, 进而获取div[0]和div1这两个列表元素。通过div[0]和div1两个节点的比较,我们就能自动发现相同的子节点(name,mount)和不同的节点(北京:上海,37:42)。相同的节点会保存为属性名,不同的节点为属性值。但是,不能提供北京和37,此时,公共节点是div[0], 这不是列表。
软件在不提供关键字的情况下,也能通过html文档的特征,去计算最可能是列表父节点(如图中的parent)的节点,但当网页特别复杂时,猜测可能会出错,所以需要至少提供两个关键字( 属性)。
本算法原理是原创的,可查看源码或留言交流。
2. 两种工作模式
Hawk把网页分成两种类型:
- 列表(List)->多文档模式
- 如二手房房源信息
- 某个购物清单
- 普通文档(One)->单文档模式
- 如京东的某个商品页面
- 某条新闻页面
对一些复杂的页面,可能包含多个列表和文档。Hawk建议你一次只抓取其中的一类信息,同时抓取多类信息会相当复杂。
你可以在网页采集器的【工作模式】下拉菜单中选择目标模式,默认List.
注意:
当你没有为网页采集器添加任何属性时,默认行为是返回只有一个字段
Content的单文档,内容为整个页面。
单文档和多文档模式,会让网页采集器在数据清洗模块中产生不同的行为。建议阅读 这部分内容
基本列表
我们以爬取链家二手房为例,介绍网页采集器的使用。首先双击图标,加载采集器:
在最上方的地址栏中,输入要采集的目标网址,本次是
并点击刷新网页。此时,下方展示的是获取的html文本。原始网站页面如下:
[QQ截图20160501121150.jpg-88kB][3]
可以点击
复制到粘贴板,方便使用其他工具对获取的页面进行搜索。
全自动模式
直接点击手气不错,第一次弹出来的列表可能不是我们想要的,没关系。关闭当前窗口,会弹出如下的对话框:
[image_1aur4cis61djc147c2b1e101o6um.png-44.5kB][4]
选择否,即可继续检查下一个可能的列表目标,直到检索到你要的内容为止,属性的名称是自动推断的,如果不满意,可以修改列表第一列的属性名, 在对应的列中敲键盘回车提交修改。之后系统就会自动将这些属性添加到属性列表中。最后点击是,确认结果。
你会发现,生成的数据中不包含超链接,因为超链接是不可见的标签(attribute),Hawk默认是不检索之的,需要勾选提取标签 即可。
手动模式
由于软件不知道到底要获取哪些内容,因此需要手工给定几个关键字, 让Hawk搜索关键字, 并获取位置。
以上述页面为例,通过检索820万和51789(单价,每次采集时都会有所不同),我们就能通过DOM树的路径,找出整个房源列表的根节点。
下面是实际步骤
[QQ截图20160501121344.jpg-21.6kB][6]
由于要抓取列表,所以读取模式选择List。 填入搜索字符700, 发现能够成功获取XPath, 编写属性为“总价”
,点击添加字段,即可添加一个属性。类似地,再填入30535,设置属性名称为“单价”,即可添加另外一个属性。
如果发现有错误,可点击编辑集合,
对属性进行删除,修改和排序。
你可以类似的将所有要抓取的特征字段添加进去,或是直接点击手气不错,系统会根据目前的属性,推测其他属性:
[QQ截图20160501121405.jpg-138.5kB][7]
结果检查
工作过程中,可点击提取测试 ,随时查看采集器目前的能够抓取的数据内容。这样,一个链家二手房的网页采集器即可完成。可属性管理器的上方,可以修改采集器的模块名称,这样就方便数据清洗 模块调用该采集器。
3. 单文档模式
该模式只能从一个网页中抽取一个文档出来。
你可以设置多个属性,这样采集器就会从网页中依次将其抽取出来。
以抓取新闻内容为例:
http://www.ce.cn/xwzx/gnsz/gdxw/201609/21/t20160921_16119449.shtml
页面如下:
[image_1at5pff7g7m71jtq1b2o1hlq1dt9.png-76.5kB][8]
你可以在搜索关键字中,搜索【2016年09月21日】,属性填写为时间,搜索【人民日报】,属性为【来源】。
提取正文需要注意,你可以随意填写正文中的一部分关键字,例如【量子隐形传态是一种传递量子】,这样Hawk就检索出了XPath:
前面省略/div[1]/p[1]
如果你直接使用这个路径,则抓取的内容只有这一段。为了抓取正文,我们可以将/p[1]部分去掉,只获取其父节点。这样就能抓取全文数据(是不是很赞)?
如果你想获取原始正文的html,则在属性列表的对话框里,可以勾选某个属性的【HTML标签】。
此时,点击提取测试,看看是不是获取了所需的数据?
Hawk 3. 网页采集器的更多相关文章
- 网页采集器-UA伪装
网页采集器-UA伪装 UA伪装 请求载体身份标识的伪装: User-Agent: 请求载体身份标识,通过浏览器发起的请求,请求载体为浏览器,则该请求的User-Agent为浏览器的身份标识,如果使用爬 ...
- 爬虫学习--Day4(网页采集器的实现)
#UA: User-Agent {请求载体的身份标识}#(反爬机制)UA检测:门户网站的服务器回检测对应请求的载体身份标识,如果检测到请求的载体身份为某一款浏览器就说明该请求时一个正常的请求.但是,如 ...
- javacoo/CowSwing 丑牛迷你采集器
丑牛迷你采集器是一款基于Java Swing开发的专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从 网页上抓取结构化的文本.图片.文件等资源信息,可编辑筛选处理后选择发布到网站 ...
- 八爪鱼采集器︱爬取外网数据(twitter、facebook)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 要想采集海外数据有两种方式:云采集+单机采集. ...
- 八爪鱼采集器︱加载更多、再显示20条图文教程(Xpatth、Ajax)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 由于代码布置采集器比较麻烦,又很早知道八爪鱼采 ...
- 使用火蜘蛛采集器Firespider采集天猫商品数据并上传到微店
有很多朋友都需要把天猫的商品迁移到微店上去.可在天猫上的商品数据非常复杂,淘宝开放接口禁止向外提供数据,一般的采集器对ajax数据采集的支持又不太好. 还有现在有了火蜘蛛采集器,经过一定的配置,终于把 ...
- 建站技能get(1)— Asp.net MVC快速集成ckplayer网页视频播放器
故事背景大概是这样的,我厂两年前给山西晋城人民政府做了一个门户网站(地址:http://jccq.cn/),运行了一年多固若金汤,duang的有一天市场部门过来说,新闻管理模块带视频的内容播放不了了. ...
- 火车采集器 帝国CMS7.2免登录发布模块
帝国cms7.2增加了金刚模式,登录发布有难度.免登录发布模块配合火车采集器,完美解决你遇到的问题. 免登录直接获取栏目列表 通过文件内设置密码免登录发布数据 帝国cms7.2免登陆文章发布接口使用说 ...
- WEB页面采集器编写经验之一:静态页面采集器
严格意义来说,采集器和爬虫不是一回事:采集器是对特定结构的数据来源进行解析.结构化,将所需的数据从中提取出来:而爬虫的主要目标更多的是页面里的链接和页面的TITLE. 采集器也写过不少了,随便写一点经 ...
随机推荐
- ASP.NET Core 中的那些认证中间件及一些重要知识点
前言 在读这篇文章之间,建议先看一下我的 ASP.NET Core 之 Identity 入门系列(一,二,三)奠定一下基础. 有关于 Authentication 的知识太广,所以本篇介绍几个在 A ...
- HDU1671——前缀树的一点感触
题目http://acm.hdu.edu.cn/showproblem.php?pid=1671 题目本身不难,一棵前缀树OK,但是前两次提交都没有成功. 第一次Memory Limit Exceed ...
- Ajax实现原理,代码封装
都知道实现页面的异步操作需要使用Ajax,那么Ajax到是怎么实现异步操作的呢? 首先需要认识一个对象 --> XMLHttpRequest 对象 --> Ajax的核心.它有许多的属性和 ...
- C# 给word文档添加水印
和PDF一样,在word中,水印也分为图片水印和文本水印,给文档添加图片水印可以使文档变得更为美观,更具有吸引力.文本水印则可以保护文档,提醒别人该文档是受版权保护的,不能随意抄袭.前面我分享了如何给 ...
- 小程序用户反馈 - HotApp小程序统计仿微信聊天用户反馈组件,开源
用户反馈是小程序开发必要的一个功能,但是和自己核心业务没关系,主要是产品运营方便收集用户的对产品的反馈.HotApp推出了用户反馈的组件,方便大家直接集成使用 源码下载地址: https://gith ...
- iOS系列教程 目录 (持续更新...)
前言: 听说搞iOS的都是高富帅,身边妹子无数.咱也来玩玩.哈哈. 本篇所有内容使用的是XCode工具.Swift语言进行开发. 我现在也是学习阶段,每一篇内容都是经过自己实际编写完一遍之后,发现 ...
- windows 7(32/64位)GHO安装指南(系统安装篇)~重点哦!!~~~~
经过了前三篇的铺垫,我们终于来到了最重要的部分~~如果没看过前几篇的小伙伴们,可以出门右转~~用十几分钟回顾一下~~然后在看这篇会感觉不一样的~~~~ 下面让我们来正式开始吧 我们进入大白菜的桌面是酱 ...
- 基于select的python聊天室程序
python网络编程具体参考<python select网络编程详细介绍>. 在python中,select函数是一个对底层操作系统的直接访问的接口.它用来监控sockets.files和 ...
- Linux 安装Mono环境 运行ASP.NET(一)
1.先看一下Linux环境下面请求的过程,(画的不是很好,简单的了解一下原理.) .NET跨平台其实需要这三个关键:编译器.CLR和基础类库.在.NET下我们编写一个最简单的"Hello W ...
- 《图解HTTP》读书笔记
目前国内讲解HTTP协议的书是在太少了,记忆中有两本被誉为经典的书<HTTP权威指南>与<TCP/IP详解,卷1>,但内容晦涩难懂,学习难度较大.其实,HTTP协议并不复杂,理 ...