Distributed3:SQL Server 分布式数据库性能测试
我在三台安装SQL Server 2012的服务器上搭建分布式数据库,把产品环境中一年近1.4亿条数据大致均匀地存储在这三台服务器中,每台Server 存储4个月的数据,物理机的系统配置基本相同:内存16G,双核 CPU 3.6GHz,软件环境是Windows Server 2012 R,和SQL Server 2012。
1,创建水平分区视图
基础表是dbo.Commits,每个基础表大致存储4个月的数据,近5000万条记录:
CREATE TABLE [dbo].[Commits]
(
[CommitID] [bigint] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[AuthorID] [bigint] NOT NULL,
[CreatedDate] [datetime2](7) NOT NULL,
[CreatedDateKey] [int] NOT NULL,
CONSTRAINT [PK__Commits_CommitID] PRIMARY KEY CLUSTERED
(
[CommitID] ASC,
[CreatedDateKey] ASC
)
)
创建分区视图,Linked Server的Alias是db2 和 db3,Catalog 是 tdw(test data warehouse):
CREATE view [dbo].[view_commits]
as select [CommitID]
,[AuthorID]
,[CreatedDate]
,[CreatedDateKey]
from dbo.commits c with(nolock)
where c.[CreatedDateKey] between 20150900 and 20160000 union ALL
select [CommitID]
,[AuthorID]
,[CreatedDate]
,[CreatedDateKey]
from db3.tdw.dbo.commits c with(nolock)
where c.[CreatedDateKey] between 20150000 and 20150500 union ALL
select [CommitID]
,[AuthorID]
,[CreatedDate]
,[CreatedDateKey]
from db2.tdw.dbo.commits c with(nolock)
where c.[CreatedDateKey] between 20150500 and 20150900
WITH check OPTION;
GO
2,查询性能测试
Test1,在基础表上测试,基础表是全部的数据,cost:79s
select count(0)
from dbo.commits_total c with(nolock)
where day(c.[CreatedDate])=1

Test2,使用分区视图测试,cost=134s,比Test1的查询性能明显降低。
select count(0)
from dbo.view_commits c with(nolock)
where day(c.[CreatedDate])=1
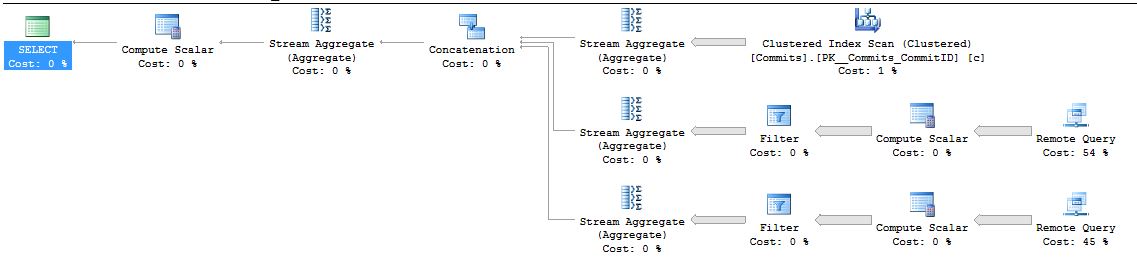
3,使用OpenQuery查询
OpenQuery把查询语句直接发送到Linked Server上执行,返回查询的结果,cost:105s,还是很高,相对提高20%的性能。
select sum(t.cnt) as cnt
from
(
select count(0) as cnt
from dbo.commits c with(nolock)
where day(c.[CreatedDate])=1 UNION all
select p.cnt
from openquery(db2,
N'select count(0) as cnt
from dbo.commits c with(nolock)
where day(c.[CreatedDate])=1') as p UNION all
select p.cnt
from openquery(db3,
N'select count(0) as cnt
from dbo.commits c with(nolock)
where day(c.[CreatedDate])=1') as p
) as t
4,使用C# 多线程编程
创建三个Task同时运行在三台Server上,Cost:28s
static void Main(string[] args)
{
List<Task> tasks = new List<Task>();
int c1=, c2=, c3=; Task t1 = new Task(()=>
{
c1= GetCount("xxx");
}); Task t2 = new Task(() =>
{
c2= GetCount("xxx");
}); Task t3 = new Task(() =>
{
c3= GetCount("xxx");
});
tasks.Add(t1);
tasks.Add(t2);
tasks.Add(t3); Stopwatch sw = new Stopwatch();
sw.Start();
t1.Start();
t2.Start();
t3.Start(); Task.WaitAll(tasks.ToArray()); int sum = c1 + c2 + c3;
sw.Stop(); Console.Read();
} static int GetCount(string str)
{
using (SqlConnection con = new SqlConnection(str))
{
con.Open();
var cmd = con.CreateCommand();
cmd.CommandText = @" select count(0) as cnt
from dbo.commits c with(nolock)
where day(c.[CreatedDate]) = 1";
int count = (int)cmd.ExecuteScalar();
con.Close();
return count;
}
}
5,结论
- 将数据水平切分,分布式部署在不同的SQL Server上,其查询性能并不一定比单一DB性能更好。
- 使用OpenQuery函数将查询语句在Remote Server上执行,返回查询结果,能够优化Linked Server 的查询性能。
- 在使用分布式数据库查询数据时,针对特定的应用,编写特定的代码,这需要fore-end 更多的参与。
参考doc:
Top 3 Performance Killers For Linked Server Queries
[翻译]——SQL Server使用链接服务器的5个性能杀手
Distributed3:SQL Server 分布式数据库性能测试的更多相关文章
- Distributed4:SQL Server 分布式数据库性能测试
我使用三台SQL Server 2012 搭建分布式数据库,将一年的1.4亿条数据大致均匀存储在这三台Server中,每台Server 存储4个月的数据,Physical Server的配置基本相同, ...
- SQL Server分布式数据库技术(LinkedServer,CT,SSB)
SQL Server自定义业务功能的数据同步 在不同业务需求的驱动下,数据库的模块化拆分将会面临一些比较特殊的业务逻辑处理需求.例如,在数据库层面的数据同步需求.同步过程中,可能会有一些比较复杂的业务 ...
- SQL Server 2012 数据库笔记
慕课网 首页 实战 路径 猿问 手记 Python 手记 \ SQL Server 2012 数据库笔记 SQL Server 2012 数据库笔记 2016-10-25 16:29:33 1 ...
- SQL Server 2008 数据库镜像部署实例之一 数据库准备
SQL Server 2008 数据库镜像部署实例之一 数据库准备 一.目标 利用Sql Server 2008 enterprise X64,建立异步(高性能)镜像数据库,同时建立见证服务器实现自动 ...
- SQL SERVER 分布式事务(DTC)
BEGIN DISTRIBUTED TRANSACTION指定一个由 Microsoft 分布式事务处理协调器 (MS DTC) 管理的 Transact-SQL 分布式事务的起始. 语法BEGIN ...
- Microsoft SQL server 2012数据库学习总结(一)
一.Microsoft SQL Server2012简介 1.基本概要 Microsoft SQL Server 2012是微软发布的新一代数据平台产品,全面支持云技术与平台,并且能够快速构建相应的解 ...
- 让PDF.NET支持不同版本的SQL Server Compact数据库
最近项目中需要用到嵌入式数据库,我们选用的数据开发框架是PDF.NET(http://www.pwmis.com/SqlMap/),之前的博文已经总结了让PDF.NET支持最新的SQLite,今天我们 ...
- Linux下使用FreeTDS访问MS SQL Server 2005数据库(包含C测试源码)
Linux下使用FreeTDS访问MS SQL Server 2005数据库(包含C测试源码) http://blog.csdn.net/helonsy/article/details/7207497 ...
- 如何转换SQL Server 2008数据库到SQL Server 2005
背景介绍: 公司一套系统使用的是SQL SERVER 2008数据库,突然一天收到邮件,需要将这套系统部署到各个不同地方(海外)的工厂,需要在各个工厂部署该数据库,等我将准备工作做好,整理文档 ...
随机推荐
- lua调用c++函数返回值作用
2015/05/28 lua调用c++接口,返回给lua函数的是压入栈的内容,可以有多个返回值.但是c++接口本身也是有返回值的,这个返回值也非常的重要,会决定最后返回到lua函数的值的个数. (1) ...
- zabbix 监控iptables
参看的文章链接忘了...... yum -y install iptstate 1.脚本位置和内容 [root@web1 scripts]# pwd /etc/zabbix/scripts [root ...
- zabbix的日常监控-自动化监控(十一)
自动化监控: 1.自动注册 1.1.zabbix agent自动添加 2.主动发现 2.1.自动发现Discover 2.2.zabbix api 自动发现与自动注册,哪一个更好? 共同的特点均可以添 ...
- Ardunio led呼吸灯
#include <Adafruit_NeoPixel.h> #define PIN 9#define LED_NUM 16Adafruit_NeoPixel strip = Adafru ...
- Lonely(非洲NANA作品)
Lonely(非洲NANA作品) 编辑 Lonely NANA,出生于1968年10月5日的非洲加纳.来自于加纳的NANA出身于一个富有的家庭,但是父亲在他小时候离他们而去,母亲带着年幼的NANA定居 ...
- WCF自寄宿实现Https绑定
一.WCF配置 1 Address 将服务端发布地址和客户端访问地址都配置为https开始的安全地址.参考如下. <add key="SrvUrl" value=" ...
- laravel 资料
1.http://maxoffsky.com/maxoffsky-blog/building-a-shop-with-laravel-tutorial-series-announcement/ 一篇 ...
- weblogic之CVE-2018-3246 XXE分析
通过ftp通道将数据传出来.上传1.xml <!DOCTYPE xmlrootname [<!ENTITY % aaa SYSTEM "http://192.168.172.12 ...
- Hadoop学习之路(十七)MapReduce框架Partitoner分区
Partitioner分区类的作用是什么? 在进行MapReduce计算时,有时候需要把最终的输出数据分到不同的文件中,比如按照省份划分的话,需要把同一省份的数据放到一个文件中:按照性别划分的话,需要 ...
- 3、JVM--垃圾回收期和内存分配策略(2)
3.5.垃圾收集器 如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现.Java虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商.不同版本的虚拟机所提供的垃圾收集 ...