【转】Caffe初试(八)Blob,Layer和Net以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成。Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型。它将所有的信息数据定义为blobs,从而进行便利的操作和通讯。Blob是caffe框架中一种标准的数组,一种统一的内存接口,它详细描述了信息是如何存储的,以及如何在层之间通讯的。
1、blob
Blobs封装了运行时的数据信息,提供了CPU和GPU的同步。从数学上来说,Blob就是一个N维数组。它是caffe中的数据基本单位,就像matlab中以矩阵为基本操作对象一样。只是矩阵是二维的,而Blob是N维的。N可以是2,3,4等等。对于图片数据来说,Blob可以表示为(N*C*H*W)这样一个4D数组。其中N表示图片的数量,C表示图片的通道数,H和W分别表示图片的高度和宽度。当然,除了图片数据,Blob也可以用于非图片数据。比如传统的多层感知机,就是比较简单的全连接网络,用2D的Blob,调用innerProduct层来计算就可以了。
2、layer
层是网络模型的组成要素和计算基本单位。层的类型比较多,如Data,Convolution,Pooling,ReLUmSoftmax-loss,Accuracy等,一个层的定义大致如下图:
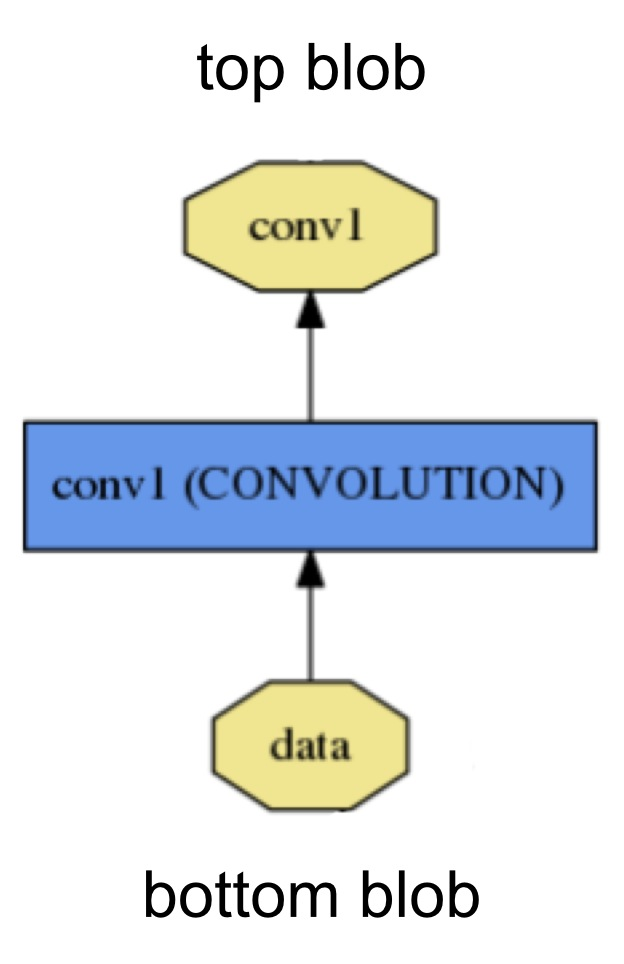
从bottom进行数据的输入,计算后,通过top进行输出。图中的黄色多边形表示输入输出的数据,蓝色矩形表示层。
每一种类型的层都定义为三种关键的计算:setup,forward and backword
setup:层的建立和初始化,以及在整个模型中的连接初始化。
forward:从bottom得到输入数据,进行计算,并将计算结果送到top,进行输出。
backward:从层的输出端top得到数据的梯度,计算当前层的梯度,并将计算结果送到bottom,向前传递。
3、Net
就像搭积木一样,一个net由多个layer组合而成。
现给出一个简单的2层神经网络的模型定义(加上loss层就变成三层了),先给出这个网络拓扑。

第一层:name为mnist,type为Data,没有输入(bottom),只有两个输出(top),一个为data,一个为label
第二层:name为ip,type为InnerProduct,输入数据data,输出数据ip
第三层:name为loss,type为SoftmaxWithLoss,有两个输入,一个为ip,一个为label,有一个输出loss,没有画出来。
对应的配置文件prototxt就可以这样写:
name: "LogReg"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
data_param {
source: "input_leveldb"
batch_size: 64
}
}
layer {
name: "ip"
type: "InnerProduct"
bottom: "data"
top: "ip"
inner_product_param {
num_output: 2
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip"
bottom: "label"
top: "loss"
}
第一行将这个模型取名为LogReg,然后是三个layer的定义,参数都比较简单,只列出必须的参数。
【转】Caffe初试(八)Blob,Layer和Net以及对应配置文件的编写的更多相关文章
- Caffe学习系列(6):Blob,Layer and Net以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成.Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型.它将所有的信息数据定义为blob ...
- (Caffe)基本类Blob,Layer,Net(一)
本文地址:http://blog.csdn.net/mounty_fsc/article/details/51085654 Caffe中,Blob.Layer,Net,Solver是最为核心的类,下面 ...
- 怎样在caffe中添加layer以及caffe中triplet loss layer的实现
关于triplet loss的原理.目标函数和梯度推导在上一篇博客中已经讲过了.详细见:triplet loss原理以及梯度推导.这篇博文主要是讲caffe下实现triplet loss.编程菜鸟.假 ...
- 【caffe Blob】caffe中与Blob相关的代码注释、使用举例
首先,Blob使用的小例子(通过运行结果即可知道相关功能): #include <vector> #include <caffe/blob.hpp> #include < ...
- 【转】Caffe初试(九)solver及其设置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 #caffe train --solver=*_solver. ...
- caffe初试(一)happynear的caffe-windows版本的配置及遇到的问题
之前已经配置过一次caffe环境了: Caffe初试(一)win7_64bit+VS2013+Opencv2.4.10+CUDA6.5配置Caffe环境 但其中也提到,编译时,用到了cuda6.5,但 ...
- Caffe初试(三)使用caffe的cifar10网络模型训练自己的图片数据
由于我涉及一个车牌识别系统的项目,计划使用深度学习库caffe对车牌字符进行识别.刚开始接触caffe,打算先将示例中的每个网络模型都拿出来用用,当然这样暴力的使用是不会有好结果的- -||| ,所以 ...
- 如何给caffe添加新的layer ?
如何给caffe添加新的layer ? 初学caffe难免会遇到这个问题,网上搜来一段看似经典的话, 但是问题来了,貌似新版的caffe并没有上面提到的vision_layer:
- caffe(6) Blob,Layer,Net 以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成.Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型.它将所有的信息数据定义为blob ...
随机推荐
- py-faster-rcnn之python引入_caffe.so
本文并不给出"编写一个c++代码,然后编译为.so文件,然后在python中引入"的hello world,需要的请参考:http://www.oschina.net/questi ...
- Android Studio解决未识别Java文件(出现红J)问题
1.问题:java文件出现了红J的问题,正常情况下应该是显示蓝色的C标识. 2.解决方案:切换到project视图下,找到app这个module里的build.gradle,在android结构里插入 ...
- 网站引入了css样式文件能访问,就是没有效果
今天后端的同事遇到这么个问题,引入了外部css文件也能访问,就是页面上没有效果. 大概是下面这个样子: css引入如下: 我非常的纳闷,说真的我还没遇到过这种情况,UI是可以运行的,一点事都没有... ...
- 关于BFC的初步了解以及常见使用
在学习CSS的过程中,掌握一些常用方法或效果实现的原理对于我们的学习来说是很有帮助的.如最常见的清除浮动和取消外边距塌陷时使用overflow:hidden;,在学习初期往往只知道有这种用法,且使用时 ...
- Forward+
http://aras-p.info/blog/2012/03/02/2012-theory-for-forward-rendering/ http://www.slideshare.net/taka ...
- gevent
gevent是一个基于协程的python网络库. 特性: 1.基于libev的事件循环 2.基于greenlet 轻量级的执行单元 (what is greenlet ?) 3.来自python标准 ...
- java 多线程 1 线程 进程
Java多线程(一).多线程的基本概念和使用 2012-09-10 16:06 5108人阅读 评论(0) 收藏 举报 分类: javaSE综合知识点(14) 版权声明:本文为博主原创文章,未经博 ...
- 关于TableView上有一段留白的解决方法
当cell的类型是plaint类型时 直接设置self.automaticallyAdjustsScrollViewInsets=NO; 还有要注意检查你自己设置的frame是否正确 当cel ...
- RabbitMQ学习
参考链接:http://www.cnblogs.com/leocook/p/mq_rabbitmq_0.html
- 高可用mysql之MHA源码剖析
* MHA的整个故障(离线)切换过程 - 检测主库的状态,确认是否崩溃. - 确认服务崩溃,保存binlog,推送到主控机,并可以强制关闭主库避免脑裂. - 找出数据最新的从库(也就是read_mas ...