【转】Caffe初试(八)Blob,Layer和Net以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成。Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型。它将所有的信息数据定义为blobs,从而进行便利的操作和通讯。Blob是caffe框架中一种标准的数组,一种统一的内存接口,它详细描述了信息是如何存储的,以及如何在层之间通讯的。
1、blob
Blobs封装了运行时的数据信息,提供了CPU和GPU的同步。从数学上来说,Blob就是一个N维数组。它是caffe中的数据基本单位,就像matlab中以矩阵为基本操作对象一样。只是矩阵是二维的,而Blob是N维的。N可以是2,3,4等等。对于图片数据来说,Blob可以表示为(N*C*H*W)这样一个4D数组。其中N表示图片的数量,C表示图片的通道数,H和W分别表示图片的高度和宽度。当然,除了图片数据,Blob也可以用于非图片数据。比如传统的多层感知机,就是比较简单的全连接网络,用2D的Blob,调用innerProduct层来计算就可以了。
2、layer
层是网络模型的组成要素和计算基本单位。层的类型比较多,如Data,Convolution,Pooling,ReLUmSoftmax-loss,Accuracy等,一个层的定义大致如下图:
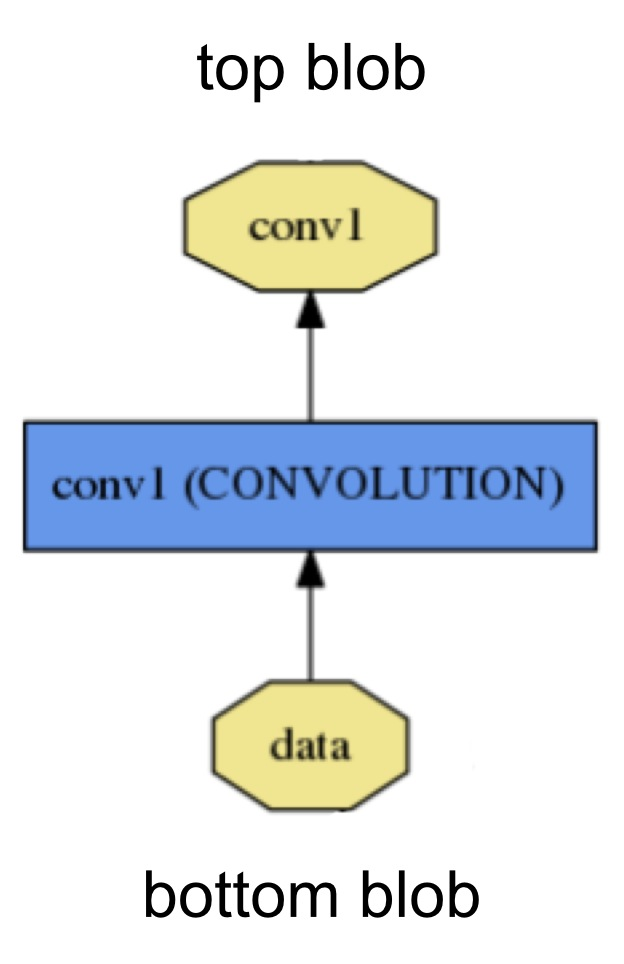
从bottom进行数据的输入,计算后,通过top进行输出。图中的黄色多边形表示输入输出的数据,蓝色矩形表示层。
每一种类型的层都定义为三种关键的计算:setup,forward and backword
setup:层的建立和初始化,以及在整个模型中的连接初始化。
forward:从bottom得到输入数据,进行计算,并将计算结果送到top,进行输出。
backward:从层的输出端top得到数据的梯度,计算当前层的梯度,并将计算结果送到bottom,向前传递。
3、Net
就像搭积木一样,一个net由多个layer组合而成。
现给出一个简单的2层神经网络的模型定义(加上loss层就变成三层了),先给出这个网络拓扑。

第一层:name为mnist,type为Data,没有输入(bottom),只有两个输出(top),一个为data,一个为label
第二层:name为ip,type为InnerProduct,输入数据data,输出数据ip
第三层:name为loss,type为SoftmaxWithLoss,有两个输入,一个为ip,一个为label,有一个输出loss,没有画出来。
对应的配置文件prototxt就可以这样写:
name: "LogReg"
layer {
name: "mnist"
type: "Data"
top: "data"
top: "label"
data_param {
source: "input_leveldb"
batch_size: 64
}
}
layer {
name: "ip"
type: "InnerProduct"
bottom: "data"
top: "ip"
inner_product_param {
num_output: 2
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip"
bottom: "label"
top: "loss"
}
第一行将这个模型取名为LogReg,然后是三个layer的定义,参数都比较简单,只列出必须的参数。
【转】Caffe初试(八)Blob,Layer和Net以及对应配置文件的编写的更多相关文章
- Caffe学习系列(6):Blob,Layer and Net以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成.Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型.它将所有的信息数据定义为blob ...
- (Caffe)基本类Blob,Layer,Net(一)
本文地址:http://blog.csdn.net/mounty_fsc/article/details/51085654 Caffe中,Blob.Layer,Net,Solver是最为核心的类,下面 ...
- 怎样在caffe中添加layer以及caffe中triplet loss layer的实现
关于triplet loss的原理.目标函数和梯度推导在上一篇博客中已经讲过了.详细见:triplet loss原理以及梯度推导.这篇博文主要是讲caffe下实现triplet loss.编程菜鸟.假 ...
- 【caffe Blob】caffe中与Blob相关的代码注释、使用举例
首先,Blob使用的小例子(通过运行结果即可知道相关功能): #include <vector> #include <caffe/blob.hpp> #include < ...
- 【转】Caffe初试(九)solver及其设置
solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是solver配置文件.运行代码一般为 #caffe train --solver=*_solver. ...
- caffe初试(一)happynear的caffe-windows版本的配置及遇到的问题
之前已经配置过一次caffe环境了: Caffe初试(一)win7_64bit+VS2013+Opencv2.4.10+CUDA6.5配置Caffe环境 但其中也提到,编译时,用到了cuda6.5,但 ...
- Caffe初试(三)使用caffe的cifar10网络模型训练自己的图片数据
由于我涉及一个车牌识别系统的项目,计划使用深度学习库caffe对车牌字符进行识别.刚开始接触caffe,打算先将示例中的每个网络模型都拿出来用用,当然这样暴力的使用是不会有好结果的- -||| ,所以 ...
- 如何给caffe添加新的layer ?
如何给caffe添加新的layer ? 初学caffe难免会遇到这个问题,网上搜来一段看似经典的话, 但是问题来了,貌似新版的caffe并没有上面提到的vision_layer:
- caffe(6) Blob,Layer,Net 以及对应配置文件的编写
深度网络(net)是一个组合模型,它由许多相互连接的层(layers)组合而成.Caffe就是组建深度网络的这样一种工具,它按照一定的策略,一层一层的搭建出自己的模型.它将所有的信息数据定义为blob ...
随机推荐
- centos手动编译安装apache、php、mysql
64位centos 5.5手动安装lamp,要求curl.json.pdo_mysql.gd,记录如下. centos 5.4.5.5.5.6的内核都是2.6.18,都可以安装php 5.3. 卸载旧 ...
- delphi 2010与delphi XE破解版的冲突
在系统中同时安装了Dephi 2010LITE版与Delphi XE lite后,总是会有一个有问题 是因为两者都是读取C:\ProgramData\Embarcadero目录下的license文件, ...
- c# .net获取随机字符串!
public string getStr(bool b,int n)//b:是否有复杂字符,n:生成的字符串长度 { string str = "0123456789abcdefghijkl ...
- 关于elasticsearch和kibana的时区和日期问题
elasticsearch原生支持date类型,json格式通过字符来表示date类型.所以在用json提交日期至elasticsearch的时候,es会隐式转换,把es认为是date类型的字符串直接 ...
- Tomcat8安装, 安全配置与性能优化(转)
一.Tomcat 安装 官网:http://tomcat.apache.org/ Tomcat8官网下载地址:http://tomcat.apache.org/download-80.cgi 为了便于 ...
- 【10-25】intelliji ide 学习笔记
快捷键 /** alter+enter 导包,异常处理等提示 psvm 快速main函数 sout 快速sysout语句 fi 快速for循环 ctrl+d 重复一行 Ctrl+X 删除行 Ctrl+ ...
- asp.net core 如何在Controller获取配置文件的值
场景:我们会把一些配置信息,写在配置文件文件中,便于我们修改和配置.在之前的asp.net 中可以通过ConfigurationManger来获取web.config里面的配置.在.net core ...
- 03 Yarn 原理介绍
Yarn 原理介绍 大纲: Hadoop 架构介绍 YARN 产生的背景 YARN 基础架构及原理 Hadoop的1.X架构的介绍 在1.x中的NameNodes只可能有一个,虽然可以通过Se ...
- Python - 类与对象的方法
类与对象的方法
- dom解析和sax解析的区别及优缺点
dom解析一开始就将文档所有内容装入内存,每个元素(标签)都作为一个element对象存储,形成对象树,缺点是对内存占用大,不能解析数据量很大的文档:优点是方便进行crud操作. sax解析,逐行解析 ...