使用maven&&make-distribution.sh编译打包spark源码
1》基础环境准备:
jdk1.8.0_101
maven 3.3.9
scala2.11.8
安装好上述软件,配置好环境变量,并检查是否生效。
2》配置maven:intellij idea maven配置及maven项目创建
3》设置maven编译内存
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
4.》使用maven命令编译源码。
mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7. -Phive -Phive-thriftserver -DskipTests
5》使用spark自带打包脚本打包(实际上该脚本调用上述的mvn命令,所以可以直接跳过第4步,当然如果只是调试用,不用打成压缩包,则直接到第4步即可)。
首先修改脚本:在spark源码包根目录下执行如下命令, vi dev/make-distribution.sh
注释掉以下内容:位于文件中的120~136行。 #VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ >/dev/null | grep -v "INFO" | tail -n )
#SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ >/dev/null\
# | grep -v "INFO"\
# | tail -n )
#SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ >/dev/null\
# | grep -v "INFO"\
# | tail -n )
#SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ >/dev/null\
# | grep -v "INFO"\
# | fgrep --count "<id>hive</id>";\
# # Reset exit status to , otherwise the script stops here if the last grep finds nothing\
# # because we use "set -o pipefail"
# echo -n) 添加以下内容: VERSION=2.3.
SCALA_VERSION=2.11
SPARK_HADOOP_VERSION=2.7.
SPARK_HIVE=
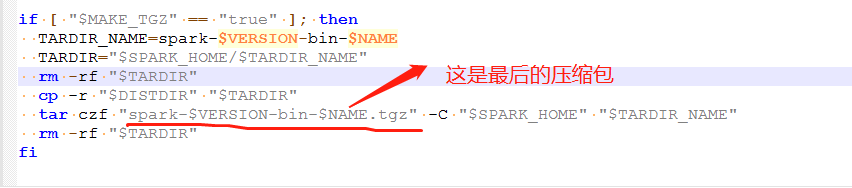
6》修改后保存退出。在源码包根目录指定以下命令:
./dev/make-distribution.sh –name 2.7.3 –tgz -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -Phadoop-provided -Phive -Phive-thriftserver -DskipTests
如果要编译对应的cdh版本,需要在源码的根目录下的pom文件中添加如下的仓库。
添加 cdh的仓库。
<repository>
<id>clouders</id>
<name>clouders Repository</name>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
命令解释:
--name 2.7.3 ***指定编译出来的spark名字,name=
--tgz ***压缩成tgz格式
-Pyarn \ ***支持yarn平台
-Phadoop-2.7 \ -Dhadoop.version=2.7.3 \ ***指定hadoop版本为2.7.3
-Phive -Phive-thriftserver \ ***支持hive
-DskipTests clean package ***跳过测试包
使用maven&&make-distribution.sh编译打包spark源码的更多相关文章
- 【源码编译】spark源码编译
本文采用cdh版本spark-1.6.0-cdh5.12.0 1.源码包下载 2.进入根目录编译,编译的方式有2种 maven mvn clean package \ -DskipTests -Pha ...
- Spark源码的编译过程详细解读(各版本)
说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要先清理maven(使用命 ...
- Spark源码的编译过程详细解读(各版本)(博主推荐)
不多说,直接上干货! 说在前面的话 重新试多几次.编译过程中会出现下载某个包的时间太久,这是由于连接网站的过程中会出现假死,按ctrl+c,重新运行编译命令. 如果出现缺少了某个文件的情况,则要 ...
- window环境下使用sbt编译spark源码
前些天用maven编译打包spark,搞得焦头烂额的,各种错误,层出不穷,想想也是醉了,于是乎,换种方式,使用sbt编译,看看人品如何! 首先,从官网spark官网下载spark源码包,解压出来.我这 ...
- idea下关联spark源码环境(转)
0.环境: java 1.8 scala 2.11.8 maven 3.5.0 idea 2017 spark 2.2.0 1完成以下配置 java环境变量 scala环境变量 maven setti ...
- Spark笔记--使用Maven编译Spark源码(windows)
1. 官网下载源码 source code,地址: http://spark.apache.org/downloads.html 2. 使用maven编译: 注意在编译之前,需要设置java堆大小以及 ...
- Spark 学习(三) maven 编译spark 源码
spark 源码编译 scala 版本2.11.4 os:ubuntu 14.04 64位 memery 3G spark :1.1.0 下载源码后解压 1 准备环境,安装jdk和scala,具体参考 ...
- 编译Spark源码
Spark编译有两种处理方式,第一种是通过SBT,第二种是通过Maven.作过Java工作的一般对于Maven工具会比较熟悉,这边也是选用Maven的方式来处理Spark源码编译工作. 在开始编译工作 ...
- 使用 IntelliJ IDEA 导入 Spark源码及编译 Spark 源代码
1. 准备工作 首先你的系统中需要安装了 JDK 1.6+,并且安装了 Scala.之后下载最新版的 IntelliJ IDEA 后,首先安装(第一次打开会推荐你安装)Scala 插件,相关方法就不多 ...
随机推荐
- JVM虚拟机20:内存区域详解(Eden Space、Survivor Space、Old Gen、Code Cache和Perm Gen)
1.内存区域划分 根据我们之前介绍的垃圾收集算法,限定商用虚拟机基本都采用分代收集算法进行垃圾回收.根据对象的生命周期的不同将内存划分为几块,然后根据各块的特点采用最适当的收集算法.大批对象死去.少量 ...
- 【node.js】全局变量、常用工具、文件系统
学习链接:http://www.runoob.com/nodejs/nodejs-global-object.html 在 JavaScript 中,通常 window 是全局对象, 而 Node.j ...
- mac 安装npm
npm是什么 NPM的全称是Node Package Manager ,是一个NodeJS包管理和分发工具,已经成为了非官方的发布Node模块(包)的标准. 如何安装 一:如果你安装了Homebrew ...
- js之checkbox判断常用示例
checkbox常用示例可参考: 关于checkbox自动选中 checkbox选中并通过ajax传数组到后台接收 MP实战系列(十三)之批量修改操作(前后台异步交互) 本次说的是,还是关于智能门锁开 ...
- 集合之asList的缺陷
在实际开发过程中我们经常使用asList讲数组转换为List,这个方法使用起来非常方便,但是asList方法存在几个缺陷: 一.避免使用基本数据类型数组转换为列表 使用8个基本类型数组转换为列表时会存 ...
- TortoiseGit需要重复填写用户名和密码的问题
命令行执行: git config --global credential.helper store 即可
- 代码收藏系列--php--生成简短唯一订单号
/** * 生成商家交易单号 * <br />特点:不重复 * <br />示例: * <br />普通付款:array('shop_id'=>1,'prod ...
- 【OC底层】KVO原理
KVO的原理是什么?底层是如何实现的? KVO是Key-value observing的缩写. KVO是Objective-C是使用观察者设计模式实现的. Apple使用了isa混写(isa-swiz ...
- 2019北航OO第一单元作业总结
一.前三次作业内容分析总结 前言 前三次作业,我提交了三次,但是有效作业只有两次,最后一次作业没能实现多项式求导的基本功能因此无疾而终,反思留给后文再续,首先我介绍一下这三次作业,三次作业围绕着多项式 ...
- chrome浏览器使用jqprint插件打印时偶尔空白页问题
最近测试老是提bug说是有50%的概率打印出空白页,之前我也一直发现偶尔会出现这个问题,只是一直没有发现原因. 今天终于下定决心找到问题所在.开始吧! 查看源码一行行debug,发现问题只可能出现在这 ...