scrapy运行机制
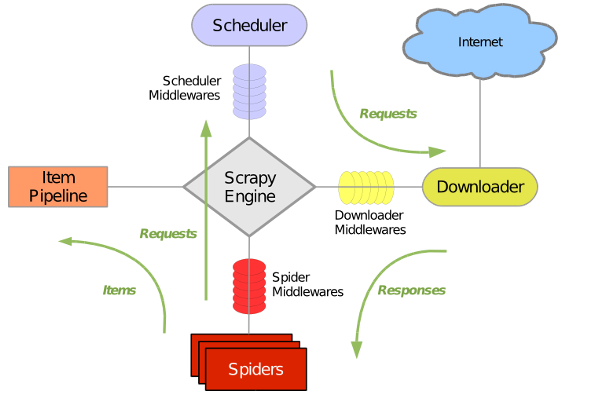
Scrapy主要包括了以下组件:
- 引擎(Scrapy)
用来处理整个系统的数据流, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
位于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
Scrapy运行流程大概如下:
- 引擎从调度器中取出一个链接(URL)用于接下来的抓取
- 引擎把URL封装成一个请求(Request)传给下载器
- 下载器把资源下载下来,并封装成应答包(Response)
- 爬虫解析Response
- 解析出实体(Item),则交给实体管道进行进一步的处理
- 解析出的是链接(URL),则把URL交给调度器等待抓取
scrapy运行机制的更多相关文章
- Scrapy(爬虫)基本运行机制
Scrapy(爬虫)基本运行机制
- Scrapy各部分运行机制?Xpath为None?多层Response如何编写?搞定Scrapy的坑
前言 Scrapy那么多模块都是怎么结合的啊?明明在chrome上的xpath helper插件写好了xpath,为什么到程序就读取的是None?Scrapy可以直接写多层response么?难道必须 ...
- python的scrapy框架的使用 和xpath的使用 && scrapy中request和response的函数参数 && parse()函数运行机制
这篇博客主要是讲一下scrapy框架的使用,对于糗事百科爬取数据并未去专门处理 最后爬取的数据保存为json格式 一.先说一下pyharm怎么去看一些函数在源码中的代码实现 按着ctrl然后点击函数就 ...
- (十三)Maven插件解析运行机制
这里给大家详细说一下Maven的运行机制,让大家不仅知其然,更知其所以然. 1.插件保存在哪里? 与我们所依赖的构件一样,插件也是基于坐标保存在我们的Maven仓库当中的.在用到插件的时候会先从本地仓 ...
- 深入理解JavaScript运行机制
深入理解JavaScript运行机制 前言 本文是写作在给团队新人培训之际,所以其实本文的受众是对JavaScript的运行机制不了解或了解起来有困难的小伙伴.也就是说,其实真正的原理和本文阐述的并不 ...
- javascript运行机制
太久没更新博客了,Javascript运行机制 Record it 1.代码块 JavaScript中的代码块是指由<script>标签分割的代码段.例如: <script type ...
- ASP.NET MVC的运行机制--url的全局分析
全局 首先我们来看一副图片 首先,用户通过Web浏览器向服务器发送一条url请求,这里请求的url不再是xxx.aspx格式,而是http://HostName/ControllerNam ...
- Windows程序内部运行机制 转自http://www.cnblogs.com/zhili/p/WinMain.html
一.引言 要想熟练掌握Windows应用程序的开发,首先需要理解Windows平台下程序运行的内部机制,然而在.NET平台下,创建一个Windows桌面程序,只需要简单地选择Windows窗体应用程序 ...
- JavaWeb三大组件——过滤器的运行机制理解
过滤器Filter 文章前言:本文侧重实用和理解. 一.过滤器的概念. lFilter也称之为过滤器,它是Servlet技术中最实用的技术,WEB开发人员通过Filter技术,对web服务器管理的所有 ...
随机推荐
- POJ 1240 Pre-Post-erous! && East Central North America 2002 (由前序后序遍历序列推出M叉树的种类)
题目链接 问题描述 : We are all familiar with pre-order, in-order and post-order traversals of binary trees. ...
- STL-set and multiset
! ! ! ! set 中的元素总是保持单调递增. set<int> a; set的插入 set没有尾部插入函数push_back(),元素的插入一般使用insert进行动态检索插入. a ...
- 升级lamp中php5.6到php7.0过程
升级过程我就直接摘录博友,http://www.tangshuang.net/1765.html,几乎问题和解决办法都是参照他的,所以我也就不另外写了.谢谢!! 周末看了一下php7的一些情况,被其强 ...
- 【codeforces】【比赛题解】#960 CF Round #474 (Div. 1 + Div. 2, combined)
终于打了一场CF,不知道为什么我会去打00:05的CF比赛…… 不管怎么样,这次打的很好!拿到了Div. 2选手中的第一名,成功上紫! 以后还要再接再厉! [A]Check the string 题意 ...
- Android浮动窗口的实现
1.浮动窗口的实现原理 看到上图的那个小Android图标了吧,它不会被其他组建遮挡,也可以响应用户的点击和拖动事件,它的显示和消失由WindowManager直接管理,它就是Android浮动窗口. ...
- docker修改docker0 mtu
由于docker宿主机设置了mtu造成docker镜像中mtu和宿主机mtu不匹配,大包后网络不同.所以需要设置docker0的mtu. 1.修改docker.service vi /usr/lib/ ...
- GreenPlum学习笔记:date_part与extract提取日期时间、时间差
GP可以使用date_part / extract从日期时间类型中抽取部分内容. 方法一:extract 格式:extract(field from source) extract函数从日期.时间数 ...
- Zabbix监控websphere和weblogic
本节内容 zabbix java gateway 配置和运行java gateway 配置zabbix server使用java gateway 调整java gateway的日志级别 监控weblo ...
- CCF CSP 201604-4 游戏
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201604-4 游戏 问题描述 小明在玩一个电脑游戏,游戏在一个n×m的方格图上进行,小明控制 ...
- RabbitMQ系列之高可用集群
为了实现高可用,我采用LVS+双节点RabbitMq , 架构图如下: 在RabbitMQ之前放了LVS, LVS 采用 rr 轮询算法 , 目的是将请求平均分配到两个真实节点,并配置5672端口监控 ...