python 统计MySQL大于100万的表
一、需求分析
线上的MySQL服务器,最近有很多慢查询。需要统计出行数大于100万的表,进行统一优化。
需要筛选出符合条件的表,统计到excel中,格式如下:
| 库名 | 表名 | 行数 |
| db1 | users | 1234567 |
二、统计表的行数
统计表的行数,有2中方法:
1. 通过查询mysql的information_schema数据库中INFODB_SYS_TABLESTATS表,它记录了innodb类型每个表大致的数据行数
2. select count(1) from 库名.表名
下面来分析一下这2种方案。
第一种方案,不是精确记录的。虽然效率快,但是表会有遗漏!
第二钟方案,才是准确的。虽然慢,但是表不会遗漏。
备注:
count(1)其实这个1,并不是表示第一个字段,而是表示一个固定值。
count(1),其实就是计算一共有多少符合条件的行。
1并不是表示第一个字段,而是表示一个固定值。
其实就可以想成表中有这么一个字段,这个字段就是固定值1,count(1),就是计算一共有多少个1.
写入json文件
下面这段代码,是参考我之前写的一篇文章:
https://www.cnblogs.com/xiao987334176/p/9901692.html
在此基础上,做了部分修改,完整代码如下:
#!/usr/bin/env python3
# coding: utf-8 import pymysql
import json conn = pymysql.connect(
host="192.168.91.128", # mysql ip地址
user="root",
passwd="root",
port=3306, # mysql 端口号,注意:必须是int类型
connect_timeout = 3 # 超时时间
) cur = conn.cursor() # 创建游标 # 获取mysql中所有数据库
cur.execute('SHOW DATABASES') data_all = cur.fetchall() # 获取执行的返回结果
# print(data_all) dic = {} # 大字典,第一层
for i in data_all:
if i[0] not in dic: # 判断库名不在dic中时
# 排序列表,排除mysql自带的数据库
exclude_list = ["sys", "information_schema", "mysql", "performance_schema"]
if i[0] not in exclude_list: # 判断不在列表中时
# 写入第二层数据
dic[i[0]] = {'name': i[0], 'table_list': []}
conn.select_db(i[0]) # 切换到指定的库中
cur.execute('SHOW TABLES') # 查看库中所有的表
ret = cur.fetchall() # 获取执行结果 for j in ret:
# 查询表的行数
cur.execute('select count(1) from `%s`;'% j[0])
ret = cur.fetchall()
# print(ret)
for k in ret:
print({'tname': j[0], 'rows': k[0]})
dic[i[0]]['table_list'].append({'tname': j[0], 'rows': k[0]}) with open('tj.json','w',encoding='utf-8') as f:
f.write(json.dumps(dic))
三、写入excel中
直接读取tj.json文件,进行写入,完整代码如下:
#!/usr/bin/env python3
# coding: utf-8 import xlwt
import json
from collections import OrderedDict f = xlwt.Workbook()
sheet1 = f.add_sheet('统计', cell_overwrite_ok=True)
row0 = ["库名", "表名", "行数"] # 写第一行
for i in range(0, len(row0)):
sheet1.write(0, i, row0[i]) # 加载json文件
with open("tj.json", 'r') as load_f:
load_dict = json.load(load_f) # 反序列化文件
order_dic = OrderedDict() # 有序字典
for key in sorted(load_dict): # 先对普通字典key做排序
order_dic[key] = load_dict[key] # 再写入key num = 0 # 计数器
for i in order_dic: # 遍历所有表
for j in order_dic[i]["table_list"]:
# 判断行数大于100万时
if j['rows'] > 1000000:
# 写入库名
sheet1.write(num + 1, 0, i)
# 写入表名
sheet1.write(num + 1, 1, j['tname'])
# 写入行数
sheet1.write(num + 1, 2, j['rows'])
num += 1 # 自增1 f.save('test1.xls')
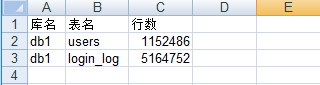
执行程序,打开excel文件,效果如下:
python 统计MySQL大于100万的表的更多相关文章
- 教你如何6秒钟往MySQL插入100万条数据!然后删库跑路!
教你如何6秒钟往MySQL插入100万条数据!然后删库跑路! 由于我用的mysql 8版本,所以增加了Timezone,然后就可以了 前提是要自己建好库和表. 数据库test, 表user, 三个字段 ...
- python 统计MySQL表信息
一.场景描述 线上有一台MySQL服务器,里面有几十个数据库,每个库有N多表. 现在需要将每个表的信息,统计到excel中,格式如下: 库名 表名 表说明 建表语句 db1 users 用户表 CRE ...
- 统计mysql库中每张表的行数据
修改数据库配置文件:vim /etc/my.cnf [client] user=username password=password 使用shell脚本统计表中的行数据:count.sh #!/bin ...
- 题目:企业发放的奖金根据利润提成。 利润(I)低于或等于10万元时,奖金可提10%; 利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提成7.5%; 20万到40万之间时,高于20万元的部分,可提成5%; 40万到60万之间时高于40万元的部分,可提成 3%; 60万到100万之间时,高于60万元的部分,可提成1.5%; 高于100万元时,超过
题目:企业发放的奖金根据利润提成. 利润(I)低于或等于10万元时,奖金可提10%: 利润高于10万元,低于20万元时,低于10万元的部分按10%提成,高于10万元的部分,可可提成7.5%: 20万到 ...
- 多表查询思路、navicat可视化软件、python操作MySQL、SQL注入问题以及其他补充知识
昨日内容回顾 外键字段 # 就是用来建立表与表之间的关系的字段 表关系判断 # 一对一 # 一对多 # 多对多 """通过换位思考判断""" ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- python、mysql四-2:多表查询
一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 准备表 #建表 create table department( id int, name varchar() ); create tabl ...
- 微信抢红包小技巧(python模拟100万次)
之前,在网上看到一篇文章,说多人抢红包时,微信红包金额的分配规则是0.01元到当前剩余金额平均数的2倍(最后一个人金额为当前剩下的所有金额),所以写了一个python程序,模拟量一百万次,分析了一下抢 ...
- Python 基于Python从mysql表读取千万数据实践
基于Python 从mysql表读取千万数据实践 by:授客 QQ:1033553122 场景: 有以下两个表,两者都有一个表字段,名为waybill_no,我们需要从tl_waybill_b ...
随机推荐
- IAR ------- 在线调试技巧
调试模式下,右击某一行选“Set Next Statement”,可以不执行中间程序,执行点直接到此行,用于不执行某些代码.
- VLOOKUP函数将一个excel表格的数据匹配到另一个表中
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- Oracle的基本语法,存储函数及触发器
1.PL/SQL PL/SQL是Oracle对 ql语言的过程化扩展,指在 SQL 命令语言中增加了过程处理语句,使SQL语言具有过程处理能力.把 SQL 语言的数据操纵能 力与过程语言的数据 ...
- element ui 上传文件,读取内容乱码解决
element ui 上传文件,读取内容乱码解决: 加第二个参数 reader.readAsText(file.raw,'gb2312'); <el-upload class="upl ...
- bzoj千题计划137:bzoj [CQOI2014]危桥
http://www.lydsy.com/JudgeOnline/problem.php?id=3504 往返n遍,即单向2*n遍 危桥流量为2,普通桥流量为inf 原图跑一遍最大流 交换b1,b2再 ...
- Seven Techniques for Data Dimensionality Reduction
Seven Techniques for Data Dimensionality Reduction Seven Techniques for Data Dimensionality Reductio ...
- Java并发编程原理与实战二:并行&并发&多线程的理解
1.CPU的发展趋势: 核心数目依旧会越来越多,根据摩尔定律,由于单个核心性能提升有着严重的瓶颈问题,普通的PC桌面在2018年可能回到24核心. 2.并发和并行的区别: 所有的并发处理都有排队等候, ...
- 网站监控系统安装部署(zabbix,nagios)
zabbix分布式监控系统安装部署 官方网站链接 https://www.zabbix.com/documentation/2.0/manual/installation 安装环境说明 参考地址 ht ...
- MySQL在net中Datatime转换
<add name="adDb" connectionString="Persist Security Info=False;database=ad ...
- sklearn进行拟合
# codind:utf-8 from sklearn.linear_model import SGDRegressor,LinearRegression,Ridge from sklearn.pre ...