缓存算法LRU笔记
LRU原理与分析
LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,也就是说,LRU缓存把最近最少使用的数据移除,让给最新读取的数据。而往往最常读取的,也是读取次数最多的,所以,利用LRU缓存,我们能够提高系统的performance.
LRU实现
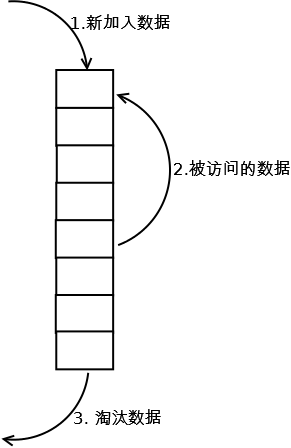
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
LRU分析
【命中率】
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】
实现简单。
【代价】
命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
LRU实现
细节
添加元素时,放到链表头
缓存命中,将元素移动到链表头
缓存满了之后,将链表尾的元素删除
LRU算法实现
- 可以用一个双向链表保存数据
- 使用hash实现O(1)的访问
groupcache中LRU算法实现(Go语言)
https://github.com/golang/groupcache/blob/master/lru/lru.go
源码简单注释:
package lru import "container/list" // Cache 结构体,定义lru cache 不是线程安全的
type Cache struct {
// 数目限制,0是无限制
MaxEntries int // 删除时, 可以添加可选的回调函数
OnEvicted func(key Key, value interface{}) ll *list.List // 使用链表保存数据
cache map[interface{}]*list.Element // map
} // Key 是任何可以比较的值 http://golang.org/ref/spec#Comparison_operators
type Key interface{} type entry struct {
key Key
value interface{}
} // 创建新的cache 对象
func New(maxEntries int) *Cache {
return &Cache{
MaxEntries: maxEntries,
ll: list.New(),
cache: make(map[interface{}]*list.Element),
}
} // 添加新的值到cache里
func (c *Cache) Add(key Key, value interface{}) {
if c.cache == nil {
c.cache = make(map[interface{}]*list.Element)
c.ll = list.New()
}
if ee, ok := c.cache[key]; ok {
// 缓存命中移动到链表的头部
c.ll.MoveToFront(ee)
ee.Value.(*entry).value = value
return
}
// 添加数据到链表头部
ele := c.ll.PushFront(&entry{key, value})
c.cache[key] = ele
if c.MaxEntries != 0 && c.ll.Len() > c.MaxEntries {
// 满了删除最后访问的元素
c.RemoveOldest()
}
} // 从cache里获取值.
func (c *Cache) Get(key Key) (value interface{}, ok bool) {
if c.cache == nil {
return
}
if ele, hit := c.cache[key]; hit {
// 缓存命中,将命中元素移动到链表头
c.ll.MoveToFront(ele)
return ele.Value.(*entry).value, true
}
return
} // 删除指定key的元素
func (c *Cache) Remove(key Key) {
if c.cache == nil {
return
}
if ele, hit := c.cache[key]; hit {
c.removeElement(ele)
}
} // 删除最后访问的元素
func (c *Cache) RemoveOldest() {
if c.cache == nil {
return
}
ele := c.ll.Back()
if ele != nil {
c.removeElement(ele)
}
} func (c *Cache) removeElement(e *list.Element) {
c.ll.Remove(e)
kv := e.Value.(*entry)
delete(c.cache, kv.key)
if c.OnEvicted != nil {
c.OnEvicted(kv.key, kv.value)
}
} // cache 缓存数
func (c *Cache) Len() int {
if c.cache == nil {
return 0
}
return c.ll.Len()
}
LRU-K
LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
实现
相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。只有当数据的访问次数达到K次的时候,才将数据放入缓存。当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。详细实现如下:
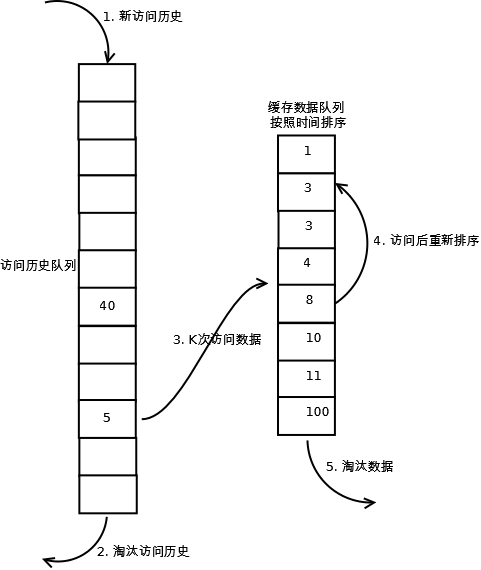
1. 数据第一次被访问,加入到访问历史列表;
2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;
3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;
4. 缓存数据队列中被再次访问后,重新排序;
5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
分析
【命中率】
LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】
LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】
由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU要高。
缓存算法LRU笔记的更多相关文章
- 缓存算法–LRU
LRU LRU是Least Recently Used 的缩写,翻译过来就是“最近最少使用”,也就是说,LRU缓存把最近最少使用的数据移除,让给最新读取的数据.而往往最常读取的,也是读取次数最多的,所 ...
- Android图片缓存之Lru算法
前言: 上篇我们总结了Bitmap的处理,同时对比了各种处理的效率以及对内存占用大小.我们得知一个应用如果使用大量图片就会导致OOM(out of memory),那该如何处理才能近可能的降低oom发 ...
- 面试挂在了 LRU 缓存算法设计上
好吧,有人可能觉得我标题党了,但我想告诉你们的是,前阵子面试确实挂在了 RLU 缓存算法的设计上了.当时做题的时候,自己想的太多了,感觉设计一个 LRU(Least recently used) 缓存 ...
- 缓存算法(FIFO 、LRU、LFU三种算法的区别)
FIFO算法 FIFO 算法是一种比较容易实现的算法.它的思想是先进先出(FIFO,队列),这是最简单.最公平的一种思想,即如果一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小.空间满的时 ...
- Android图片缓存之Lru算法(二)
前言: 上篇我们总结了Bitmap的处理,同时对比了各种处理的效率以及对内存占用大小.我们得知一个应用如果使用大量图片就会导致OOM(out of memory),那该如何处理才能近可能的降低oom发 ...
- Android ImageCache图片缓存,使用简单,支持预取,支持多种缓存算法,支持不同网络类型,扩展性强
本文主要介绍一个支持图片自动预取.支持多种缓存算法的图片缓存的使用及功能.图片较大需要SD卡保存情况推荐使用ImageSDCardCache. 与Android LruCache相比主要特性:(1). ...
- 缓存算法之belady现象
前言 在使用FIFO算法作为缺页置换算法时,分配的缺页增多,但缺页率反而提高,这样的异常现象称为belady Anomaly. 虽然这种现象说明的场景是缺页置换,但在运用FIFO算法作为缓存算法时,同 ...
- android上的缓存、缓存算法和缓存框架
1.使用缓存的目的 缓存是存取数据的临时地,因为取原始数据代价太大了,加了缓存,可以取得快些.缓存可以认为是原始数据的子集,它是从原始数据里复制出来的,并且为了能被取回,被加上了标志. 在andr ...
- java缓存算法【转】
http://my.oschina.net/u/866190/blog/188712 提到缓存,不得不提就是缓存算法(淘汰算法),常见算法有LRU.LFU和FIFO等算法,每种算法各有各的优势和缺点及 ...
随机推荐
- 【1】mongoDB 的安装及启动
MongoDB是一个面向文档(document-oriented)的数据库,不是关系型数据库.与关系型数据库相比,面向文档的数据库没有"行"的概念,取而代之的是"文档&q ...
- 阶段2 JavaWeb+黑马旅游网_15-Maven基础_第1节 基本概念_02maven依赖管理的概念
传统的web项目jar放在项目中,占用磁盘空间 maven项目里面只保存jar包的坐标.jar包文件都在仓库中.扎包重用都在jar包仓库中.
- HTML——<body> 计算机代码 【头部在“网站开发”中】
HTML属性 完整的属性列表 在引用属性值的时候,如果某些属性本身就有双引号——name= 'John "ShotGun" Nelson'
- POJ 1330 Nearest Common Ancestors (dfs+ST在线算法)
详细讲解见:https://blog.csdn.net/liangzhaoyang1/article/details/52549822 zz:https://www.cnblogs.com/kuang ...
- paramiko远程连接linux服务器进行上传下载文件
花了不少时间来研究paramiko中sftpclient的文件传输,一顿操作猛如虎,最后就一直卡在了路径报错问题,疯狂查阅资料借鉴大佬们的心得,还是搞不好,睡了个午觉醒来,仔细一看原来是指定路径的文件 ...
- spring(二)
什么是AOP 在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是OOP(面向对 ...
- 小油2018 win7旗舰版64位GHOST版的,安装telnet客户端时,提示:出现错误。并非所有的功能被成功更改。
win7旗舰版64位GHOST版的,安装telnet客户端时,提示:出现错误.并非所有的功能被成功更改. 从安装成功的电脑上拷贝ghost版本缺少的文件,然后再安装telnet客户端,我已打包 链接: ...
- 【JZOJ 3909】Idiot 的乘幂
题面: 正文: 把题目中的方程组组合在一起就变成了: \(X^{a+c}\equiv b \cdot d (\mod p)\) 那这时,我们假定两个数\(x\)和\(y\),使得: \(ax + cy ...
- Codeforces 1262E Arson In Berland Forest(二维前缀和+二维差分+二分)
题意是需要求最大的扩散时间,最后输出的是一开始的火源点,那么我们比较容易想到的是二分找最大值,但是我们在这满足这样的点的时候可以发现,在当前扩散时间k下,以这个点为中心的(2k+1)2的正方形块内必 ...
- linux:输入/输出、重定向、管道
输入.输出: 程序的默认输入设备,叫标准输入. stdin 键盘 0 程序的默认输出设备,叫标准输出. stdout 监视器 1 程序的默认错误输出设备,叫标准错误输出.stde ...