爬虫中GET方法应用基本模型
根据get方法,更改界面url从而获取信息
GET请求URL附带查询参数
POST请求保存在form表单中
分析百度贴吧url特点:
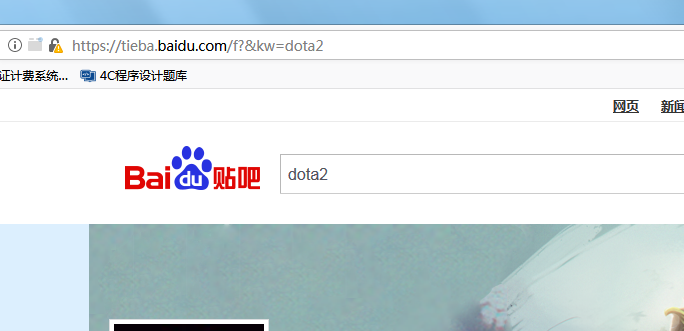
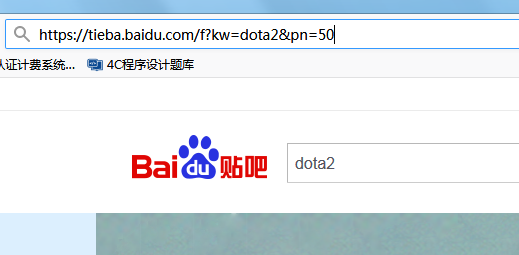
分析url https://tieba.baidu.com/f是贴吧总的url,?后是get请求,kw=xxx,&后是页码信息
爬取百度贴吧对应内容信息:
#python3
import urllib
import urllib.request
import urllib.response
import urllib.parse def tieBarSpider(url,beginPage,endPage):
"""
作用:负责处理url,分配每个url去发送请求
url:需要处理的url
beginPage:爬虫执行的起始页面
endpage:爬虫执行的截止页面
:return:
"""
for page in range(beginPage,endPage):
pn = (page-1)*50 fileName = "第" + str(page) + "页"
fullUrl = url + "&pn=" + str(pn)
#print(fullUrl)
html = loadHtmls(fullUrl)
#将爬到的html页面保存到本地
writeFiles(html,fileName)
print("aleady:%s"%fileName) def loadHtmls(fullUrl):
"""
作用:根据url发送请求,获取服务器响应
fullUrl:完整的每页的url
:return:
"""
#添加User-Agent头,伪装成浏览器访问
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'} request = urllib.request.Request(fullUrl,headers=headers) reponse = urllib.request.urlopen(request) return reponse.read().decode() #选择将爬取到的页面保存到本地
def writeFiles(html,filename):
"""
功能:将爬取到的页面保存到本地
html:页面html源码
filename:保存到本地的名字
:return:
"""
#下面语句相当于
# f = open(filename,'w')
# f.write(html)
# f.close()
with open(filename,'w') as f:
f.write(html) print('-'*20) if __name__ == '__main__': #初始页url构建
url = "https://tieba.baidu.com/f?"
keyword = input("请输入要爬取的贴吧内容:")
beginPage = int(input("BeginPage:"))
endPage = int(input("EndPage:"))
#转码为url编码,urlencode()接受的是一个字典
kw = urllib.parse.urlencode({"kw":keyword})
fullUrl = url + kw tieBarSpider(fullUrl,beginPage,endPage+1)
爬虫中GET方法应用基本模型的更多相关文章
- thinkphp模型中的获取器和修改器(根据字段名自动调用模型中的方法)
thinkphp模型中的获取器和修改器(根据字段名自动调用模型中的方法) 一.总结 记得看下面 1.获取器的作用是在获取数据的字段值后自动进行处理 2.修改器的作用是可以在数据赋值的时候自动进行转换处 ...
- 09 Scrapy框架在爬虫中的使用
一.简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.它集成高性能异步下载,队列,分布式,解析,持久化等. Scrapy 是基于twisted框架开发而来,twisted是一个 ...
- thinkphp中where方法
今天来给大家讲下查询最常用但也是最复杂的where方法,where方法也属于模型类的连贯操作方法之一,主要用于查询和操作条件的设置.where方法的用法是ThinkPHP查询语言的精髓,也是Think ...
- thinkphp中page方法
page方法也是模型的连贯操作方法之一,是完全为分页查询而诞生的一个人性化操作方法. 用法 我们在前面已经了解了关于limit方法用于分页查询的情况,而page方法则是更人性化的进行分页查询的方法,例 ...
- CI中的控制器中要用model中的方法,是统一写在构造器方法中,还是在每一个方法中分别写
Q: CI中的控制器中要用model中的方法,是统一写在构造器方法中,还是在每一个方法中分别写 A: 建议统一写,CI框架会自动识别已经加载过的类,所以不用担心重复加载的问题 class C_User ...
- 008.Adding a model to an ASP.NET Core MVC app --【在 asp.net core mvc 中添加一个model (模型)】
Adding a model to an ASP.NET Core MVC app在 asp.net core mvc 中添加一个model (模型)2017-3-30 8 分钟阅读时长 本文内容1. ...
- Class实例在堆中还是方法区中?
1.JVM中OOP-KLASS模型 在JVM中,使用了OOP-KLASS模型来表示java对象,即:1.jvm在加载class时,创建instanceKlass,表示其元数据,包括常量池.字段.方法等 ...
- Python爬虫防封杀方法集合
Python爬虫防封杀方法集合 mrlevo520 2016.09.01 14:20* 阅读 2263喜欢 38 Python 2.7 IDE Pycharm 5.0.3 前言 ...
- ThinkPHP中create()方法自动验证表单信息
自动验证是ThinkPHP模型层提供的一种数据验证方法,可以在使用create创建数据对象的时候自动进行数据验证. 原理: create()方法收集表单($_POST)信息并返回,同时触发表单自动验证 ...
随机推荐
- Form表单组件验证
第一版:最基本版本 views源码 #——————————————————————form验证—————————————— from django import forms from django.f ...
- Rsync+inotify 数据同步应用指南
Rsync+Inotify-tools (1):Inotify-tools 只能记录下被监听的目录发生了变化(包括增加.删除.修改),并没有 把具体是哪个文件或者哪个目录发生了变化记录下来: (2): ...
- Linq 高级应用实例
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Tex ...
- Mybatis中dao层实现
在上一个笔记中继续: 因为要基于dao层,那么我们只需要又一个dao的接口,和一个mapper的文件就可以测试了. 但是基于dao层的时候需要规范: Mapper.xml文件中的namespace与m ...
- poj 1269 Intersecting Lines(直线相交)
Intersecting Lines Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 8637 Accepted: 391 ...
- Spring如何解决循环依赖问题
目录 1. 什么是循环依赖? 2. 怎么检测是否存在循环依赖 3. Spring怎么解决循环依赖 本文主要是分析Spring bean的循环依赖,以及Spring的解决方式. 通过这种解决方式,我们可 ...
- git点滴
git指定版本,SHA-1短的,长的都可以 git checkout c66a9be git checkout c66a9befsadf1sdf1s3fd21 git log ##查询本地log gi ...
- django 修改字段后,同步数据库,失败:django.db.utils.InternalError: (1054, "Unknown column 'api_config.project_id_id' in 'field list'")
问题原因是,修改字段后,同步失败了,然后执行查询的时候,就会提示这个错误,这个字段没有 最暴力的方法可以直接在数据库中修改字段,但是修改后,models没同步,可能会存在问题,因此开始我的百度之旅(这 ...
- Cobaltstrike系列教程(三)-beacon详解
0x000--前文 Cobaltstrike系列教程(一)-简介与安装 Cobaltstrike系列教程(二)-Listner与Payload生成 heatlevel 0x001-Beacon详解 1 ...
- go入门收集(转)
go mod 使用 原文地址: https://juejin.im/post/5c8e503a6fb9a070d878184a