Numpy的补充(重要!!)
轴的概念
英文解释 https://www.sharpsightlabs.com/blog/numpy-axes-explained/
汉化解释 https://www.jianshu.com/p/f4e9407f9f9d
多维数组的索引及切片
https://blog.csdn.net/brucewong0516/article/details/79186126
核心 每个维度一个索引值,逗号分割
每个维度取切片用冒号
隔行取 需嵌套索引,arr[ [ 1,3,4,5] , : ]
np.newaxis
给原数组增加一个维度,newaxis放在第几个位置,就会在shape里 相应的位置增加了一个维数
https://www.jb51.net/article/144967.htm

广播机制
涉及到不同shape的数组运算的时候的概念
https://www.runoob.com/numpy/numpy-broadcast.html
https://zhuanlan.zhihu.com/p/60365398
np.where( condition, [x, y] )
condition:array_like,bool
x,y:array_like
实际上 感觉涉及到的东西很多,比如涉及到了广播。这个应该是个很强大的方法。某种程度上像布尔值索引。
https://zhuanlan.zhihu.com/p/83208224

arr.reshape(1,-1) / np.reshape(-1,1)
实际就是自动计算的方法。-1代表自动计算,666
https://blog.csdn.net/W_weiying/article/details/82112337

数组的添加 有两个方法 np.insert 和 np.append
np.insert(arr, obj, values, axis=None)
https://blog.csdn.net/lcxxcl_1234/article/details/80869152
1 values 可能是个m*1维数组

np.append()

数组的行列相互交换
不值一提了

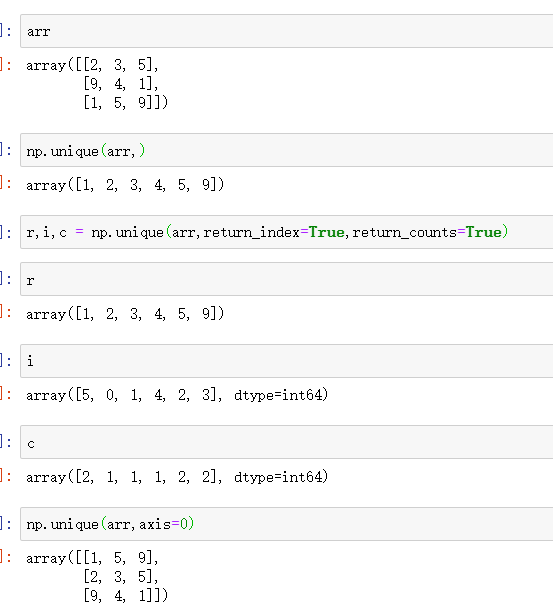
np.unique(ar,return_index=False,return_inverse=False,return_counts=False,axis=None)
最常用的功能是 去重。
有这几个参数,return_index,return_counts 可能用到的频率比较高。知道有这几参数就行。
当指定axis后,对多维数组可以使用,不会返回惟一值,而是对指定轴进行排序。
np.maximum()
返回较大值,参数可以广播。完全可以用np.where 实现。可能 广播机制 会用的比较广。

np.concatenate()
与np.stack的区别是 concatenate不改变维度

DateFram的切片,索引
牢记,一定优先用 df.loc[ ]
df.loc['a':'c','xx':'xxx'] 只有这一种方法,可以取多行多列
df.loc[['a','d'],['xx','xxxx']]
df.rename()
用处就是对index,column进行重命名。
也可以df.index = df.columns = 直接改。这个方法的好处就是可以对想单独改一个名称比较方便,参数可以是字典。
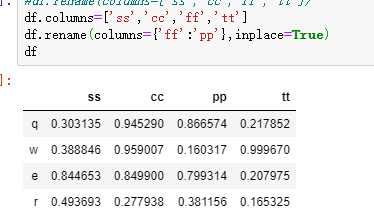
df.set_index()
Set the DataFrame index using existing columns
可能会有一定的应用场景。原来一列的数值,变为index,对从数据库中读到的数据,把id变为index,这种场景下就能用到了
DateFrame 两个df的合并
df.append(df1)

pd.concat( [df1,df2] )

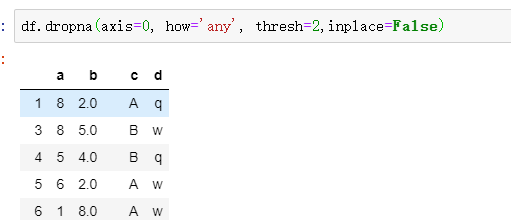
df.dropna()
这几个参数注意下
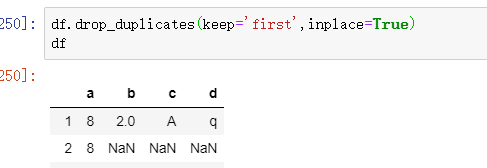
df.drop_duplicates
去重,这几个参数眼熟下
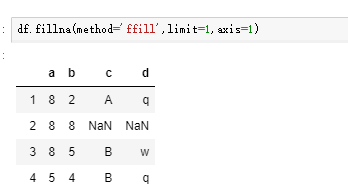
df.fillna()
添补na数据。熟悉下这几个参数
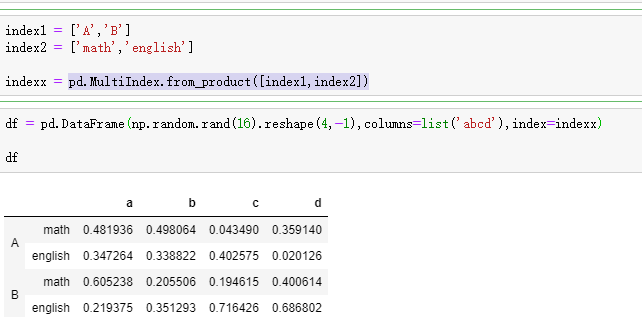
多重索引
了解下这个方法就够了,切片,索引都差不多
pd.MultiIndex.from_product([index1,index2])
聚合运算
什么叫聚合函数,聚合函数就是对一组值执行计算,并返回单个值。返回单个值,这是重点!
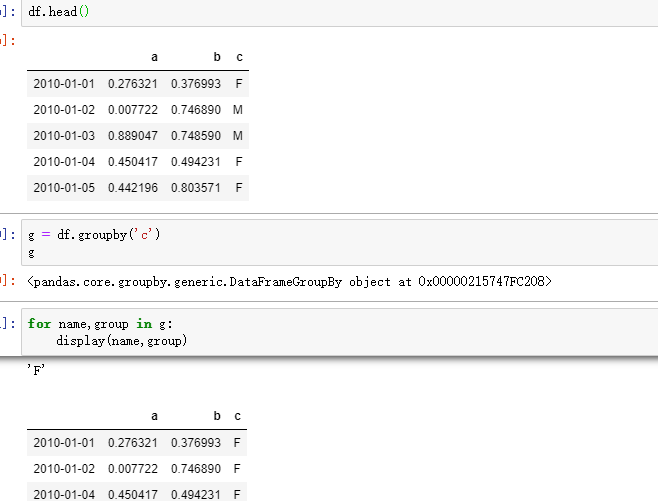
g = df.groupby(' ')
1)这个 g 可以拿来直接聚合 ,g.agg( ) , g.apply( ) ,这里想说的不是这个,而是 g 本身有很多方法。
通过 for 循环 取 ,或者 g.get_group() 取分组后的结果。
2) groupby( by =)
by = mapping, function, label, or list of labels,可以接很多参数,最常见的就是dataframe的columns,一个 或多个列表都可以。
函数也是可以的,只不是是函数的返回值的value值 作为分组的依据,可以是个范围(之前我们看到的都是确定值,比如男,女,省份等)。最好的例子就是 df.groupby(pd.cut(df,[])).count()
(即groupby可以按照具体的值分类,也可以按照范围分类,具体的值不必多说,说道范围,就想到了pd.cut )
g.agg() 聚合运算,参数比较灵活,可以接列表,字典,懂含义就行。 优点,速度快,缺点,局限性大,只能聚合。聚合接收的参数是每一个列,即series。
g.apply( func ,* args ) 。 优点,自定义,灵活,缺点,速度慢。接收的参数是dateframe。 这个方法应用的场景很广。
时间序列索引
ts = pd.date_range( )
这里介绍的是由时间序列作为索引而引申出的两个方法,一个是truncate,一个是between_time,这两个方法的调用者 都是 series或者dataframe,而不是 timeindex。
Numpy的补充(重要!!)的更多相关文章
- numpy&pandas补充常用示例
Numpy [数组切片] In [115]: a = np.arange(12).reshape((3,4)) In [116]: a Out[116]: array([[ 0, 1, 2, 3], ...
- numpy库补充 mean函数应用
mean()函数功能:求取均值经常操作的参数为axis,以m * n矩阵举例: axis 不设置值,对 m*n 个数求均值,返回一个实数 axis = 0:压缩行,对各列求均值,返回 1* n 矩阵 ...
- Python:numpy.ma模块
翻译总结自:The numpy.ma module - NumPy v1.21 Manual 前言 ma是Mask的缩写,关于Mask的解释,如果有PS的基础,可以理解为蒙版,如果有计算机网络的基础, ...
- 【小白的CFD之旅】05 补充基础
黄师姐是一个很干脆果敢的人,从她的日常装扮就能显露出来.卡帕运动装,白色运动鞋,马尾辫,这是小白对黄师姐的第一印象.“明天早上九点钟来实验室,我给你安排这阵子的任务.”黄师姐对小白说.说话语气和老蓝一 ...
- 《利用python进行数据分析》读书笔记--第四章 numpy基础:数组和矢量计算
http://www.cnblogs.com/batteryhp/p/5000104.html 第四章 Numpy基础:数组和矢量计算 第一部分:numpy的ndarray:一种多维数组对象 实话说, ...
- numpy库的常用知识
为什么有numpy这个库呢?准安装的Python中用列表(list)保存一组值,可以用来当作数组使用,不过由于列表的元素可以是任何对象,因此列表中所保存的是对象的指针.这样为了保存一个简单的[1,2, ...
- python numpy 使用笔记 矩阵操作
(原创文章转载请标注来源) 在学习机器学习的过程中经常会用到矩阵,那么使用numpy扩展包将是不二的选择 建议在平Python中用多维数组(array)代替矩阵(matrix) 入门请考 http:/ ...
- 《利用python进行数据分析》NumPy基础:数组和矢量计算 学习笔记
一.有关NumPy (一)官方解释 NumPy is the fundamental package for scientific computing with Python. It contains ...
- [补充资料] 手动搭建 Cloudera 集群
本课主题 集群搭建 设置 Web 服务器 启动 ClouderManager 登入 Cloudera Manager 引言 这部份是一个补充资料,记录如何安装 Cloudera 服务器 集群搭建 查看 ...
随机推荐
- MySql+EF+CodeFirst
ef+mssql详细是许多.net程序员的标配.作为一个程序员当然不能只会mssql这一个数据库,今天简单聊聊ef+mysql.推荐新人阅读. 1]首先创建一个mvc项目,如图: 创建完毕之后再nug ...
- burp intruder模块详解
0×01 介绍 安装要求: Java 的V1.5 + 安装( 推荐使用最新的JRE ), 可从这里免费 http://java.sun.com/j2se/downloads.html Burp Sui ...
- 小程序之如和使用view内部组件来进行页面的排版功能
这篇文章主要介绍了关于小程序之如和使用view内部组件来进行页面的排版功能,有着一定的参考价值,现在分享给大家,有需要的朋友可以参考一下 涉及知识点: 1.垂直排列,水平排列 2.居中对齐 示例: 1 ...
- spring整合apache-shiro的简单使用
这里不对shiro进行介绍,介绍什么的没有意义 初学初用,不求甚解,简单使用 一.导入jar包(引入坐标) <!--shiro和spring整合--> <dependency> ...
- sql中关闭自增,并插入数据
ET IDENTITY_INSERT 允许将显式值插入表的标识列中. 语法 SET IDENTITY_INSERT [ database.[ owner.] ] { table } { ON | OF ...
- Tomcat启动慢的原因及解决方法
Tomcat启动慢的原因及解决方法 在CentOS启动Tomcat时,启动过程很慢,需要几分钟,经过查看日志,发现耗时在这里:是session引起的随机数问题导致的.Tocmat的Session ID ...
- Linux学习--第二天--分区、格式化、系统安装、vmware、远程管理工具
分区 主分区加上扩展分区只能有四个,其中扩展分区只能有一个,扩展分区不能写入数据,不能格式化,只能包含逻辑分区.这是硬盘的限制. 格式化 分为高级与低级.文件系统是高级格式化.低级是硬盘操作. 扩展分 ...
- Centos 7 Mysql 最大连接数超了问题解决
错误:Can not connect to MySQL server. Too many connections -mysql 1040错误 这是因为对 Mysql 进行访问,未释放的连接数已经达到 ...
- 内置time模块和random模块
#time模块#time模块中有三种时间表达方式#时间戳(timestamp):指从1970年1月1号0:0:0开始按秒计算的时间偏移量#元组形式的结构化时间(strut_time):含有9个元素(t ...
- 03Java基础——继承
1.继承 例如一个员工类,包括开发员工和经理. package cn.jxufe.java.chapter2.demo12; public class Employee { String name; ...