Kafka详解与总结(五)
Kafka持久化
1. 概述
Kafka大量依赖文件系统去存储和缓存消息。对于硬盘有个传统的观念是硬盘总是很慢,这使很多人怀疑基于文件系统的架构能否提供优异的性能。实际上硬盘的快慢完全取决于使用它的方式。设计良好的硬盘架构可以和内存一样快。
在6块7200转的SATA RAID-5磁盘阵列的线性写速度差不多是600MB/s,但是随即写的速度却是100k/s,差了差不多6000倍。现在的操作系统提供了预读取和后写入的技术。实际上发现线性的访问磁盘,很多时候比随机的内存访问快得多。
为了提高性能,现代操作系统往往使用内存作为磁盘的缓存,现代操作系统乐于把所有空闲内存用作磁盘缓存,虽然这可能在缓存回收和重新分配时牺牲一些性能。所有的磁盘读写操作都会经过这个缓存,这不太可能被绕开除非直接使用I/O。所以虽然每个程序都在自己的线程里只缓存了一份数据,但在操作系统的缓存里还有一份,这等于存了两份数据。
基于jvm内存有以下缺点:
- Java对象占用空间是非常大的,差不多是要存储的数据的两倍甚至更高。
- 随着堆中数据量的增加,垃圾回收回变的越来越困难,而且可能导致错误
基于以上分析,如果把数据缓存在内存里,因为需要存储两份,不得不使用两倍的内存空间,Kafka基于JVM,又不得不将空间再次加倍,再加上要避免GC带来的性能影响,在一个32G内存的机器上,不得不使用到28-30G的内存空间。并且当系统重启的时候,又必须要将数据刷到内存中( 10GB 内存差不多要用10分钟),就算使用冷刷新(不是一次性刷进内存,而是在使用数据的时候没有就刷到内存)也会导致最初的时候新能非常慢。
基于操作系统的文件系统来设计有以下好处:
- 可以通过os的pagecache来有效利用主内存空间,由于数据紧凑,可以cache大量数据,并且没有gc的压力
- 即使服务重启,缓存中的数据也是热的(不需要预热)。而基于进程的缓存,需要程序进行预热,而且会消耗很长的时间。(10G大概需要10分钟)
- 大大简化了代码。因为在缓存和文件系统之间保持一致性的所有逻辑都在OS中。以上建议和设计使得代码实现起来十分简单,不需要尽力想办法去维护内存中的数据,数据会立即写入磁盘。
总的来说,Kafka不会保持尽可能多的内容在内存空间,而是尽可能把内容直接写入到磁盘。所有的数据都及时的以持久化日志的方式写入到文件系统,而不必要把内存中的内容刷新到磁盘中。
2. 日志数据持久化特性
写操作:通过将数据追加到文件中实现
读操作:读的时候从文件中读就好了
3. 优势
- 读操作不会阻塞写操作和其他操作(因为读和写都是追加的形式,都是顺序的,不会乱,所以不会发生阻塞),数据大小不对性能产生影响;
- 没有容量限制(相对于内存来说)的硬盘空间建立消息系统;
- 线性访问磁盘,速度快,可以保存任意一段时间!
4. 持久化原理
Topic在逻辑上可以被认为是一个queue。每条消费都必须指定它的topic,可以简单理解为必须指明把这条消息放进哪个queue里。为了使得Kafka的吞吐率可以水平扩展,物理上把topic分成一个或多个partition,每个partition在物理上对应一个文件夹,该文件夹下存储这个partition的所有消息和索引文件。

每个日志文件都是“log entries”序列,每一个log entry包含一个4字节整型数(值为N),其后跟N个字节的消息体。每条消息都有一个当前partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:
消息长度: 4 bytes (value: 1 + 4 + n)
版本号: 1 byte
CRC校验码: 4 bytes
具体的消息: n bytes
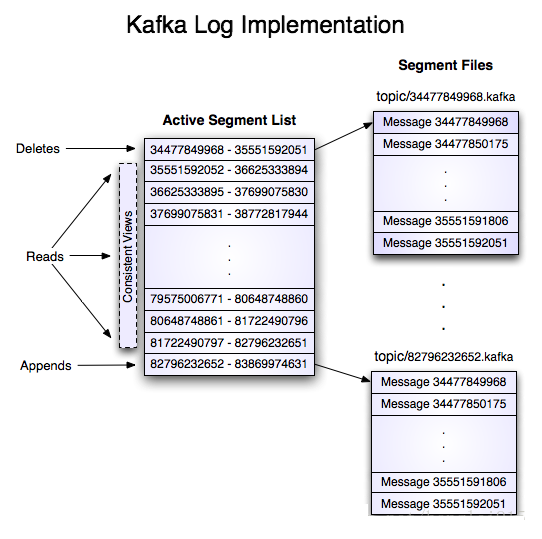
这个“log entries”并非由一个文件构成,而是分成多个segment,每个segment名为该segment第一条消息的offset和“.kafka”组成。另外会有一个索引文件,它标明了每个segment下包含的log entry的offset范围,如下图所示:
Kafka详解与总结(五)的更多相关文章
- 【Java入门提高篇】Day34 Java容器类详解(十五)WeakHashMap详解
源码详解系列均基于JDK8进行解析 说明 在Java容器详解系列文章的最后,介绍一个相对特殊的成员:WeakHashMap,从名字可以看出它是一个 Map.它的使用上跟HashMap并没有什么区别,所 ...
- Spring Boot 集成 FreeMarker 详解案例(十五)
一.Springboot 那些事 SpringBoot 很方便的集成 FreeMarker ,DAO 数据库操作层依旧用的是 Mybatis,本文将会一步一步到来如何集成 FreeMarker 以及配 ...
- Kafka详解五:Kafka Consumer的底层API- SimpleConsumer
问题导读 1.Kafka如何实现和Consumer之间的交互?2.使用SimpleConsumer有哪些弊端呢? 1.Kafka提供了两套API给Consumer The high-level Con ...
- [转]kafka详解
一.入门 1.简介 Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设 ...
- kafka详解
一.基本概念 介绍 Kafka是一个分布式的.可分区的.可复制的消息系统.它提供了普通消息系统的功能,但具有自己独特的设计. 这个独特的设计是什么样的呢? 首先让我们看几个基本的消息系统术语:Kafk ...
- (转)kafka 详解
kafka入门:简介.使用场景.设计原理.主要配置及集群搭建(转) 问题导读: 1.zookeeper在kafka的作用是什么? 2.kafka中几乎不允许对消息进行"随机读写"的 ...
- Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下: hostname ipaddress ...
- 大数据入门第十七天——storm上游数据源 之kafka详解(一)入门与集群安装
一.概述 1.kafka是什么 根据标题可以有个概念:kafka是storm的上游数据源之一,也是一对经典的组合,就像郭德纲和于谦 根据官网:http://kafka.apache.org/intro ...
- Kafka详解四:Kafka的设计思想、理念
问题导读 1.Kafka的设计基本思想是什么?2.Kafka消息转运过程中是如何确保消息的可靠性的? 本节主要从整体角度介绍Kafka的设计思想,其中的每个理念都可以深入研究,以后我可能会发专题文章做 ...
随机推荐
- try catch影响Spring事务吗?
对于这个问题有两种情况: 1.catch只打印异常,不抛出异常 try { 数据库做添加订单表; /; 数据库减少库存; }catch (Exception e){ e.printStackTrace ...
- eclipse 中常用快捷键
* 字母大小写转换 ctrl+shift+x 转为大写 ctrl+shift+y 转为小写 * eclipse 自动生成对象来接收方法的返回值的快捷键 说明:光标一定要定位到要自动生成返回值对 ...
- ubuntu 通过ppa源安装mysql5.6
添加mysql5.6的源 sudo add-apt-repository -y ppa:ondrej/mysql-5.6 更新源 sudo apt-get update 安装mysql5.6 sudo ...
- Python的/整除
在python3和python2里,正整数的/结果是一样的,但是负数的整除却有区别 比如python3中,-1/2是等于0的,c/c++的结果也是这样, 但在python2中,-1/2确是-1,想要得 ...
- sublime 使用笔记
unbuntu安装sublime---------------------------------------------sudo add-apt-repository ppa:webupd8team ...
- Django 命令行调用模版渲染
首先我们需要进入 Django 的 shell python manage.py shell 渲染模版中的 name from django.template import Context,Templ ...
- eshing wind/tidal turbine using Turbogrid
Table of Contents 1. meshing wind turbine using Turbogrid 1.1. ref 1 meshing wind turbine using Turb ...
- python基础学习 str,list,dict,set,range,enumerate
一.字符串 s = 'python' s1 = 'python' + 'learn' #相加其实就是简单拼接 s2 = 'python' * 5 #相乘其实就是复制自己多少次,再拼接在一起 字符串切片 ...
- 【Codeforces 711C】Coloring Trees
[链接] 我是链接,点我呀:) [题意] 连续相同的数字分为一段 你可以改变其中0为1~m中的某个数字(改变成不同数字需要不同花费) 问你最后如果要求分成恰好k段的话,最少需要多少花费 [题解] dp ...
- java 远程调用
1.webservice (soap+http) -aixs -axis2 -xfire—>cxf 2.webservice问题 -基于xml,xml效率,(数据传输效率,xml序列化效率) - ...