我的Python成长之路---第二天---Python基础(7)---2016年1月9日(晴)
再说字符串
一、字符串的编码
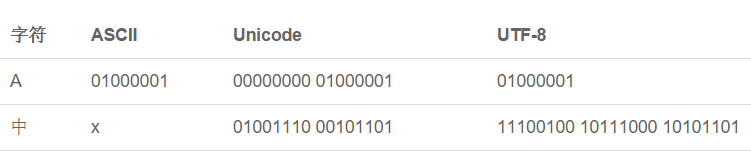
字符串的编码是个很令人头疼的问题,由于计算机是美国人发明的,他们很理所当然的认为计算机只要能处理127个字母和一些符号就够用了,所以规定了一个字符占用8个比特(bit)也就是一个字节(byte)来存储字符,也就是ASCII码。
由于1个字节能表示的最大整数是255,所以处理中文是跟定不行的。鉴于此我们国家制定了了GB2312编码,用来把中文编进去。同样各个国家都有自己的标准来表示本国的文字,比如日本的Shift_JIS,棒子国的Euc-kr。由于各国采用自己的标准,就会不可避免的出现冲突,多语言混合的文本里就出现乱码。
因此,Unicode应运而生。Unicode第一次把所有国家的语言统一编码。Unicode用两个字节表示一个字符(非常偏僻的字符可能会用到4个字节)。原来ASCII的只需要在前面补零就可以了,例如A的ASCII码是01000001,Unic码就是00000000 01000001。
但是新问题来了,由于英文字符也占用两个字节,如果一篇文章都是用英文写的,Unicode的要比ASCII多占用1倍的存储空间,非常不划算。
所以本着节约的原则,可变长编码UTF-8出现了。UTF-8通常用1-6个字节,常用的英文编码还是1个字节,汉子通常3个字节,只有很生僻的字符才会用4-6个字节。我不明白为什么UTF-8三个字节表示中文,如果一篇文章一半英文一半中文,平均下来还是两个字节,更何况如果都是中文的情况,不是反而更占空间了吗。
三种编码对比:
二、Python的字符串
在最新的Python3版本中,字符串是用Unicode表示的,对于单个字符我们可以用Python提供的ord()函数或字符的整数编码(编码的十进制),用chr()吧编码转换为对应的字符
>>> ord('A')
65
>>> ord('张')
24352
>>> chr(24353)
'弡'
如果知道字符串的整数编码,可以用十六进制这么表示中文
>>> '\u4e2d\u6587'
'中文'
>>> '中文'
'中文'
这两种方式是完全等价的。
由于Python的字符串在内存中用Unicode表示,如果要存储到硬盘或在网络上传输,就需要把字符转化为字节为单位的bytes,Python中用b前缀来表示
x = b'ABC'
注意:'ABC'和b'ABC'完全是不一样的,前者是Unicode(占用两个字节)后者是bytes(占用一个字节)
>>> 'ABC'.encode('ascii')
b'ABC'
>>> 'ABC'.encode('utf-8')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
可以看出英文既可以用ASCII也可以用Utf-8,而中文只能用Utf-8,参数为通过把字符窜的那种编码转化为bytes(姑且成为字节流吧,不知道正不正确)
反过来如果想把从网络或磁盘上的字节流转换为Python的字符串,就需要用decode方法
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'ABC'.decode('utf-8')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
关于内置的len方法,如果参数是字符串就统计出字符串的个数,如果是字节流,统计的就是字节数,这点一定要注意
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文')
2
最后说一下,Python源代码也是一种文本文件,所以我们在保存的时候要保存成UTF-8格式,这还不够,保存成UTF-8只是让操作系统知道是什么格式的文件,Python解释器还不知道。所以要我们要在我们的代码第二行用注释的形式声明是什么格式的文件
#! /usr/bin/env python3
# coding=utf-8
或者
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
这两种方式都可以。
三、字符串的内置方法
1、capitalize(首字母大写)
代码:
def capitalize(self): # real signature unknown; restored from __doc__
"""
S.capitalize() -> str
# 返回新的字符串对象,首字母大写
Return a capitalized version of S, i.e. make the first character
have upper case and the rest lower case.
"""
return ""
示例:
>>> str.capitalize()
'Hello python'
2、center(居中对齐)
代码:
def center(self, width, fillchar=None): # real signature unknown; restored from __doc__
"""
S.center(width[, fillchar]) -> str
返回新的字符串对象,居中对齐
width:宽度,返回的字符串长度
fillchar:填充字符
Return S centered in a string of length width. Padding is
done using the specified fill character (default is a space)
"""
return ""
示例:
>>> str.center(25)
' hello python '
>>> str.center(25, '*')
'*******hello python******'
3、count(返回子串出现的次数)
代码:
def count(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.count(sub[, start[, end]]) -> int
# 返回整形,子串出现的次数
sub:查询的子串
start:开始索引
end:结束索引 Return the number of non-overlapping occurrences of substring sub in
string S[start:end]. Optional arguments start and end are
interpreted as in slice notation.
"""
return 0
示例
>>> str = 'hello python'
>>> str.count("o")
2
>>> str.count("o",5)
1
>>> str.count("o",5,7)
0
4、encode(返回指定编码的字节流)
代码
def encode(self, encoding='utf-8', errors='strict'): # real signature unknown; restored from __doc__
"""
S.encode(encoding='utf-8', errors='strict') -> bytes
返回指定编码的字节流(老师说是uncode编码) Encode S using the codec registered for encoding. Default encoding
is 'utf-8'. errors may be given to set a different error
handling scheme. Default is 'strict' meaning that encoding errors raise
a UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
'xmlcharrefreplace' as well as any other name registered with
codecs.register_error that can handle UnicodeEncodeErrors.
"""
return b""
示例
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
5、endswith(判断是否某个子串结尾)
代码:
def endswith(self, suffix, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.endswith(suffix[, start[, end]]) -> bool
返回布尔值,是否以某个子串结尾
suffix:子串
start:开始索引
end:结束索引
Return True if S ends with the specified suffix, False otherwise.
With optional start, test S beginning at that position.
With optional end, stop comparing S at that position.
suffix can also be a tuple of strings to try.
"""
return False
示例:
>>> str = 'hello python'
>>> str.endswith('thon')
True
>>> str[2:8]
'llo py'
>>> str.endswith('py', 2, 8)
True
6、expandtabs(设定制表符的宽度)
代码:
def expandtabs(self, tabsize=8): # real signature unknown; restored from __doc__
"""
S.expandtabs(tabsize=8) -> str
返回新的字符串对象,设定制表符的宽度
Return a copy of S where all tab characters are expanded using spaces.
If tabsize is not given, a tab size of 8 characters is assumed.
"""
return ""
示例
>>> str = 'hello\tpython'
>>> str
'hello\tpython'
>>> print(str)
hello python
>>> print(str.expandtabs())
hello python
>>> print(str.expandtabs(8))
hello python
>>> print(str.expandtabs(16))
hello python
疑惑:这个宽度是单位是什么,8和16也不太成比例
8、find(查找子串)
代码
def find(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.find(sub[, start[, end]]) -> int
查找子串,返回第一个找到的索引
sub:要查找的子串
start:开始索引
end:结束索引
Return the lowest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation. Return -1 on failure.
找不到返回-1
"""
return 0
示例
>>> str.find('python')
6
>>> str.find('abc')
-1
9、format(格式化输出)
代码:
def format(*args, **kwargs): # known special case of str.format
"""
S.format(*args, **kwargs) -> str
格式化字符串,返回新的字符串对象,类似占位符 Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').
"""
pass
示例:
>>> str = "hello {0}"
>>> str.format('python')
'hello python'
>>> str = "hello {0}{1}"
>>> str.format('python','!')
'hello python!'
>>> str = "hello {name}"
>>> str.format(name = 'peter')
'hello peter'
10、format_map(格式化输出)
代码
def format_map(self, mapping): # real signature unknown; restored from __doc__
"""
S.format_map(mapping) -> str
格式化字符串,返回新的字符串对象
mapping:字典对象,用来替换站位符
Return a formatted version of S, using substitutions from mapping.
The substitutions are identified by braces ('{' and '}').
"""
return ""
示例
>>> str = "hello {name}"
>>> str.format_map({"name":"peter"})
'hello peter'
11、index(查找子串,返回子串的索引)
代码:
def index(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.index(sub[, start[, end]]) -> int
查找子串,使用方法同find,不同是如果不存在会报错
Like S.find() but raise ValueError when the substring is not found.
"""
return 0
示例:
>>> str = 'hello python'
>>> str.index('python')
6
>>> str.index('abc')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: substring not found
12、isalnum(判断字符串是否有字母和数字组成)
代码:
def isalnum(self): # real signature unknown; restored from __doc__
"""
S.isalnum() -> bool
判断是否为数字和字母组成
Return True if all characters in S are alphanumeric
and there is at least one character in S, False otherwise.
"""
return False
示例
>>> str = 'hello python'
>>> str.isalnum()
False
>>> str = 'hellopython'
>>> str.isalnum()
True
>>> str = 'hellopython345'
>>> str = 'hello python3.4'
>>> str.isalnum()
False
13、isalpha(判断字符串是否全有字母组成)
代码:
def isalpha(self): # real signature unknown; restored from __doc__
"""
S.isalpha() -> bool
判断是否全部全由字母组成
Return True if all characters in S are alphabetic
and there is at least one character in S, False otherwise.
"""
return False
示例:
>>> str.isalnum()
False
>>> str = 'hellopython345'
>>> str.isal
str.isalnum( str.isalpha(
>>> str.isalpha()
False
>>> str = 'hellopython'
>>> str.isalpha()
True
>>> str = 'hello python'
>>> str.isalpha()
False
14、isdecimal(判断是否由十进制数组成,相当于由[0-9]组成)
代码:
def isdecimal(self): # real signature unknown; restored from __doc__
"""
S.isdecimal() -> bool
判断是否由十进制数字组成
Return True if there are only characters in S,
False otherwise.
"""
return False
示例:
>>> str = ""
>>> str.isdecimal()
True
>>> str = "10.1"
>>> str.isdecimal()
False
15、isdigit(判断是否由数字组成,同上)
代码:
def isdigit(self): # real signature unknown; restored from __doc__
"""
S.isdigit() -> bool
判断是否由数字组成
Return True if all characters in S are digits
and there is at least one character in S, False otherwise.
"""
return False
示例:
>>> str = ""
>>> str.isdigit()
True
>>> str = "12.3"
>>> str.isdigit()
False
16、ididentifier(返回是否合法标识符,也就是是否符合python变量名语法)
代码:
def isidentifier(self): # real signature unknown; restored from __doc__
"""
S.isidentifier() -> bool
返回是否为合法表示符(是否符合python变量名语法,但是不搞包括是否是python保留的关键字)
Return True if S is a valid identifier according
to the language definition. Use keyword.iskeyword() to test for reserved identifiers
such as "def" and "class".
"""
return False
示例:
>>> str = "p1"
>>> str.isidentifier()
True
>>> str = "1p"
>>> str.isidentifier()
False
>>> str = "__pp"
>>> str.isidentifier()
True
>>> str = "def" # python关键字,一样是合法的
>>> str.isidentifier()
True
17、islower(判断字符是否是小写字符)
代码:
def islower(self): # real signature unknown; restored from __doc__
"""
S.islower() -> bool
判断字符是否全为小写(只判断字母,数字符号被忽略)
Return True if all cased characters in S are lowercase and there is
at least one cased character in S, False otherwise.
"""
return False
示例:
>>> str = "hello python"
>>> str.islower()
True
>>> str = "hello python123"
>>> str.islower() # 数字和空格等符号被忽略
True
18、isnumeric(判断是否由数字组成)
代码:
def isnumeric(self): # real signature unknown; restored from __doc__
"""
S.isnumeric() -> bool
判断是否由数字组成
Return True if there are only numeric characters in S,
False otherwise.
"""
return False
示例:
>>> str = "12.3"
>>> str.isnumeric()
False
>>> str = "12a"
>>> str.isnumeric()
False
>>> str = "-1"
>>> str.isnumeric()
False
>>> str = ""
>>> str.isnumeric()
True
19、isprintable(判断是否由可打印字符组成)
代码:
def isprintable(self): # real signature unknown; restored from __doc__
"""
S.isprintable() -> bool
判断是会否由可打印字符组成
Return True if all characters in S are considered
printable in repr() or S is empty, False otherwise.
"""
return False
示例:
>>> str = ""
>>> str.isprintable()
True
>>> str = "123\t"
>>> str.isprintable()
False
>>> str = "123\\"
>>> str.isprintable()
True
>>> str = "123%s"
>>> str.isprintable()
True
>>> str = "123\n"
>>> str.isprintable()
False
20、isspace(是否由空字符组成:空格、tab、回车)
代码:
def isspace(self): # real signature unknown; restored from __doc__
"""
S.isspace() -> bool
判断是否为空字符组成空格、tab、回车
Return True if all characters in S are whitespace
and there is at least one character in S, False otherwise.
"""
return False
示例:
>>> str = ""
>>> str.isspace()
False
>>> str = " "
>>> str.isspace()
True
>>> str = "\t"
>>> str.isspace()
True
>>> str = "hello python"
>>> str.isspace()
False
>>> str = "\n"
>>> str.isspace()
True
21、istitle(判断是否是标题格式)
代码:
def istitle(self): # real signature unknown; restored from __doc__
"""
S.istitle() -> bool
判断是否是标题格式(单词首字母大写)
Return True if S is a titlecased string and there is at least one
character in S, i.e. upper- and titlecase characters may only
follow uncased characters and lowercase characters only cased ones.
Return False otherwise.
"""
return False
示例:
>>> str = "Hello Python"
>>> str.istitle()
True
>>> str = "Hello python"
>>> str.istitle()
False
22、isupper(判断是否是大写)
代码:
def isupper(self): # real signature unknown; restored from __doc__
"""
S.isupper() -> bool
判断字符是否为大写
Return True if all cased characters in S are uppercase and there is
at least one cased character in S, False otherwise.
"""
return False
示例:
>>> str = "HELLO PYTHON"
>>> str.isupper()
True
>>> str = "HELLO PYTHOn"
>>> str.isupper()
False
23、join(拼接序列)
代码:
def join(self, iterable): # real signature unknown; restored from __doc__
"""
S.join(iterable) -> str
以当前字符串为分隔符,拼接序列对象(如列表、元祖等),返回新的字符串对象
iterable:要拼接的序列化对象
Return a string which is the concatenation of the strings in the
iterable. The separator between elements is S.
"""
return ""
示例:
>>> li = ['hello','python']
>>> ' '.join(li)
'hello python'
24、ljust(左对齐)
代码:
def ljust(self, width, fillchar=None): # real signature unknown; restored from __doc__
"""
S.ljust(width[, fillchar]) -> str
左对齐,返回新的字符串对象
width:新出的字符串对象宽度
fillchar:填充字符串,默认是空格
Return S left-justified in a Unicode string of length width. Padding is
done using the specified fill character (default is a space).
"""
return ""
示例:
>>> str = "Python"
>>> str.ljust(15)
'Python '
>>> str.ljust(15,'*')
'Python*********'
25、lower(字符串小写)
代码:
def lower(self): # real signature unknown; restored from __doc__
"""
S.lower() -> str
返回小写
Return a copy of the string S converted to lowercase.
"""
return ""
示例:
>>> str = "PythoN"
>>> str.lower()
'python'
26、lstrip(脱去左侧的空格或自定子串)
代码:
def lstrip(self, chars=None): # real signature unknown; restored from __doc__
"""
S.lstrip([chars]) -> str
脱去左侧的空格或自定子串
chars:要脱去的子串
Return a copy of the string S with leading whitespace removed.
If chars is given and not None, remove characters in chars instead.
"""
return ""
示例:
>>> str = " Python"
>>> str.lstrip()
'Python'
>>> str = "Python"
>>> str.lstrip("Py")
'thon'
27、maketrans和translate
代码
def maketrans(self, *args, **kwargs): # real signature unknown
"""
Return a translation table usable for str.translate().
创建translate对照表
If there is only one argument, it must be a dictionary mapping Unicode
ordinals (integers) or characters to Unicode ordinals, strings or None.
Character keys will be then converted to ordinals.
If there are two arguments, they must be strings of equal length, and
in the resulting dictionary, each character in x will be mapped to the
character at the same position in y. If there is a third argument, it
must be a string, whose characters will be mapped to None in the result.
"""
pass
def translate(self, table): # real signature unknown; restored from __doc__
"""
S.translate(table) -> str
通过对照表完成字符替换
table:对照表对象,maketrans返回的对象
Return a copy of the string S in which each character has been mapped
through the given translation table. The table must implement
lookup/indexing via __getitem__, for instance a dictionary or list,
mapping Unicode ordinals to Unicode ordinals, strings, or None. If
this operation raises LookupError, the character is left untouched.
Characters mapped to None are deleted.
"""
return ""
示例:
>>> trantab = str.maketrans('', 'abc')
>>> s = ('')
>>> s.translate(trantab)
'abc456'
28、partition(返回分隔符分隔的元祖,从左侧开始查找)
代码:
def partition(self, sep): # real signature unknown; restored from __doc__
"""
S.partition(sep) -> (head, sep, tail)
返回一个三个元素的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串
sep:分隔符 Search for the separator sep in S, and return the part before it,
the separator itself, and the part after it. If the separator is not
found, return S and two empty strings.
"""
pass
示例:
>>> str = "http://www.baidu.com"
>>> str.partition("//")
('http:', '//', 'www.baidu.com')
29、replace(子串替换)
代码:
def replace(self, old, new, count=None): # real signature unknown; restored from __doc__
"""
S.replace(old, new[, count]) -> str
子串替换
old:旧的子串
new:新的子串
count:替换的次数
Return a copy of S with all occurrences of substring
old replaced by new. If the optional argument count is
given, only the first count occurrences are replaced.
"""
return ""
示例:
>>> str = "abcadd"
>>> str.replace("a","")
'1bc1dd'
>>> str.replace("a","", 1)
'1bcadd'
30、rfind(从右查找子串)
def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.rfind(sub[, start[, end]]) -> int
从右查找子串,返回索引,找不到返回-1
sub:查找的子串
strat:开始索引
end:结束所以你能 Return the highest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation. Return -1 on failure.
"""
return 0
31、rindex(从右查找子串)
代码:
def rfind(self, sub, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.rfind(sub[, start[, end]]) -> int
从右查找子串,返回索引
sub:查找的子串
strat:开始索引
end:结束所以你能 Return the highest index in S where substring sub is found,
such that sub is contained within S[start:end]. Optional
arguments start and end are interpreted as in slice notation. Return -1 on failure.
"""
return 0
32、rjust(右对齐)
代码:
def rjust(self, width, fillchar=None): # real signature unknown; restored from __doc__
"""
S.rjust(width[, fillchar]) -> str
右对齐
width:宽度
fillchar:填充字符
Return S right-justified in a string of length width. Padding is
done using the specified fill character (default is a space).
"""
return ""
33、rpartition(返回分隔符分隔的元祖,从右侧开始查找)
代码:
def rpartition(self, sep): # real signature unknown; restored from __doc__
"""
S.rpartition(sep) -> (head, sep, tail)
返回一个三个元素的元祖,第一个元素为分隔符左侧的子串,第二个元素为分隔符,第三个元素为分隔符右侧的子串
sep:分隔符
Search for the separator sep in S, starting at the end of S, and return
the part before it, the separator itself, and the part after it. If the
separator is not found, return two empty strings and S.
"""
pass
34、rsplit(分隔字符串,从右侧开始分隔)
代码:
def rsplit(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__
"""
S.rsplit(sep=None, maxsplit=-1) -> list of strings
返回将字符串以指定分隔符分隔的列表,从右边开始查找分隔符
sep:分隔符
maxsplit:最多分隔的次数
Return a list of the words in S, using sep as the
delimiter string, starting at the end of the string and
working to the front. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified, any whitespace string
is a separator.
"""
return []
示例:
>>> str = "hello python nihao"
>>> str.rsplit(maxsplit = 1)
['hello python', 'nihao']
>>> str.rsplit()
['hello', 'python', 'nihao']
35、rstrip(脱去右边的空格或自定义字符串)
代码:
def rstrip(self, chars=None): # real signature unknown; restored from __doc__
"""
S.rstrip([chars]) -> str
脱去右边的空格或自定义字符串
chars:欲脱去的字符串或字符
Return a copy of the string S with trailing whitespace removed.
If chars is given and not None, remove characters in chars instead.
"""
return ""
36、split(分隔字符串,从左侧开始)
代码:
def split(self, sep=None, maxsplit=-1): # real signature unknown; restored from __doc__
"""
S.split(sep=None, maxsplit=-1) -> list of strings
分隔字符串
sep:分隔符
maxsplit:最多分隔的次数
Return a list of the words in S, using sep as the
delimiter string. If maxsplit is given, at most maxsplit
splits are done. If sep is not specified or is None, any
whitespace string is a separator and empty strings are
removed from the result.
"""
return []
37、splitlines(以换行符为分隔符分隔字符串)
代码:
def splitlines(self, keepends=None): # real signature unknown; restored from __doc__
"""
S.splitlines([keepends]) -> list of strings
以换行符为分隔符分隔字符串
keepends:是否保留换行符
Return a list of the lines in S, breaking at line boundaries.
Line breaks are not included in the resulting list unless keepends
is given and true.
"""
return []
示例:
>>> str = "hello\npython\nnihao\n"
>>> str.splitlines()
['hello', 'python', 'nihao']
>>> str.splitlines(True)
['hello\n', 'python\n', 'nihao\n']
38、startswith(以某个子串开头)
代码:
def startswith(self, prefix, start=None, end=None): # real signature unknown; restored from __doc__
"""
S.startswith(prefix[, start[, end]]) -> bool
返回布尔值,是否以某个子串开头
prefix:前缀也就是要查找的子串
start:开始索引
end:结束索引
Return True if S starts with the specified prefix, False otherwise.
With optional start, test S beginning at that position.
With optional end, stop comparing S at that position.
prefix can also be a tuple of strings to try.
"""
return False
示例:
>>> str = 'Python'
>>> str.startswith('Py')
True
>>> str.startswith('Py',2)
False
39、strip(脱去两边的空格或自定义字符)
代码:
def strip(self, chars=None): # real signature unknown; restored from __doc__
"""
S.strip([chars]) -> str
脱去两边的空格或自定义字符
chars:欲脱去的字符串或字符
Return a copy of the string S with leading and trailing
whitespace removed.
If chars is given and not None, remove characters in chars instead.
"""
return ""
示例:
>>> str = ' Python '
>>> str.strip()
'Python'
>>> str = '***python**'
>>> str.strip('*')
'python'
40、swapcase(大小写交换)
代码:
def swapcase(self): # real signature unknown; restored from __doc__
"""
S.swapcase() -> str
大小写交换
Return a copy of S with uppercase characters converted to lowercase
and vice versa.
"""
return ""
示例:
>>> str = 'PythoN'
>>> str.swapcase()
'pYTHOn'
41、title(将字符串转为标题格式、每个单词首字母大写)
代码:
def title(self): # real signature unknown; restored from __doc__
"""
S.title() -> str
判断是否是标题格式、每个单词首字母大写
Return a titlecased version of S, i.e. words start with title case
characters, all remaining cased characters have lower case.
"""
return ""
示例:
>>> str = 'hello python'
>>> str.title()
'Hello Python'
42、upper(将字母转为大写)
代码:
def upper(self): # real signature unknown; restored from __doc__
"""
S.upper() -> str
将字母转化为大写
Return a copy of S converted to uppercase.
"""
return ""
示例:
>>> str = 'Hello Python'
>>> str.upper()
'HELLO PYTHON'
43、zfill(右对齐,以字符0填充)
代码:
def zfill(self, width): # real signature unknown; restored from __doc__
"""
S.zfill(width) -> str
右对齐,以字符0填充
width:宽度
Pad a numeric string S with zeros on the left, to fill a field
of the specified width. The string S is never truncated.
"""
return ""
示例:
>>> str = 'Python'
>>> str.zfill(10)
'0000Python'
我的Python成长之路---第二天---Python基础(7)---2016年1月9日(晴)的更多相关文章
- 我的Python成长之路---第二天---Python基础(8)---2016年1月9日(晴)
数据类型之字典 一.字典简介 字典dict(dictionary),在其他语言中也成为map,使用键-值(key-value)的形式存储和展现,具有极快的查找速度. 字典的定义 d = {'key': ...
- 我的Python成长之路---第八天---Python基础(25)---2016年3月5日(晴)
多进程 multiprocessing模块 multiprocessing模块提供了一个Process类来代表一个进程对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 ...
- 我的Python成长之路---第八天---Python基础(24)---2016年3月5日(晴)
多线程编程 什么是多线程,线程是操作系统能够进行运算调度的最小单位.他包含在进程之中,是进程中的实际运作单位.线程是进程中一个单顺序的空值六,一个进程可以并发多个线程,每个线程可以并行处理不同的任务. ...
- 我的Python成长之路---第八天---Python基础(23)---2016年3月5日(晴)
socketserver 之前讲道德socket模块是单进程的,只能接受一个客户端的连接和请求,只有当该客户端断开的之后才能再接受来自其他客户端的连接和请求.当然我们也可以通过python的多线程等模 ...
- python成长之路——第二天
cpython:c解释器 .pyc(字节码)——机器码 jpython :java解释器 java字节码 ironpython :C#解释器 C#字节码 .... 上面的:编译完之后 ...
- 我的Python成长之路---第一天---Python基础(1)---2015年12月26日(雾霾)
2015年12月26日是个特别的日子,我的Python成之路迈出第一步.见到了心目中的Python大神(Alex),也认识到了新的志向相投的伙伴,非常开心. 尽管之前看过一些Python的视频.书,算 ...
- 我的Python成长之路---第一天---Python基础(作业2:三级菜单)---2015年12月26日(雾霾)
作业二:三级菜单 三级菜单 可一次进入各个子菜单 思路: 这个题看似不难,难点在于三层循环的嵌套,我的思路就是通过flag的真假来控制每一层的循环的,简单来说就是就是通过给每一层循环一个单独的布尔变量 ...
- Python成长之路第二篇(1)_数据类型内置函数用法
数据类型内置函数用法int 关于内置方法是非常的多这里呢做了一下总结 (1)__abs__(...)返回x的绝对值 #返回x的绝对值!!!都是双下划线 x.__abs__() <==> a ...
- python成长之路第二篇(4)_collections系列
一.分别取出大于66的数字和小于66的数字 小练习:需求要求有一个列表列表中存着一组数字,要求将大于66的数字和小于66的数字分别取出来 aa = [11,22,33,44,55,66,77,88,9 ...
随机推荐
- JSP 9 大内置对象详解
内置对象特点: 1. 由JSP规范提供,不用编写者实例化. 2. 通过Web容器实现和管理 3. 所有JSP页面均可使用 4. ...
- UC/0S2之中断
中断是计算机系统处理异步事件的重要机制.当异步事件发生时,事件通常是通过硬件向cpu发出中断请求的.在一般情况下,cpu响应这个请求后会立即运行中断服务程序来处理该事件: 为了处理任务延时.任务调度等 ...
- mysqlcluster笔记
1.config的datamemory和indexmemory规定的内存占有量会在ndb启动时直接占用掉,所以在计算内存时,这两个加起来要小于ndb的内存,这两个还只是数据和索引的内存,查询或者插入时 ...
- google chrome字体最小12px的问题
解决Google浏览器不支持12px以下的字体大小的问题,有时设定了12PX,可在浏览器看时确不起作用 网络出现内核的浏览器有微软的Internet Explorer, Mozilla的Firefox ...
- eclipse打war包
链接地址:http://jingyan.baidu.com/article/c910274be14164cd361d2ddc.html 一个程序要想放到服务器容器中很多人想到了打一个war包放到tom ...
- MYSQL 好文章集锦
比较细致的讲解MySQL数据库的数据结构以及实现原理 MySQL索引背后的数据结构及算法原理 MySQL的InnoDB索引原理详解 MySQL索引原理及慢查询优化 持续更新,快乐学习.
- mysql在linux上的一点操作
1,查看打开端口. show variables like 'port'; 2, 指定ip,用户名,密码 1 grant all privileges on *.* to root@"% ...
- C# 计算器 运算符和数字键的keys对照
keys. private void Computer_KeyDown(object sender, KeyEventArgs e) { if (e.KeyCode == Keys.NumPad0) ...
- BZOJ 1652: [Usaco2006 Feb]Treats for the Cows
题目 1652: [Usaco2006 Feb]Treats for the Cows Time Limit: 5 Sec Memory Limit: 64 MBSubmit: 234 Solve ...
- codility上的练习 (1)
codility上面添加了教程.目前只有lesson 1,讲复杂度的……里面有几个题, 目前感觉题库的题简单. tasks: Frog-Jmp: 一只青蛙,要从X跳到Y或者大于等于Y的地方,每次跳的距 ...