开放定址法——平方探测(Quadratic Probing)
为了消除一次聚集,我们使用一种新的方法:平方探测法。顾名思义就是冲突函数F(i)是二次函数的探测方法。通常会选择f(i)=i2。和上次一样,把{89,18,49,58,69}插入到一个散列表中,这次用平方探测看看效果,再复习一下探测规则:hi(x)= ( Hash(x) + F(I) ) % TableSize(I=0,1,2…)
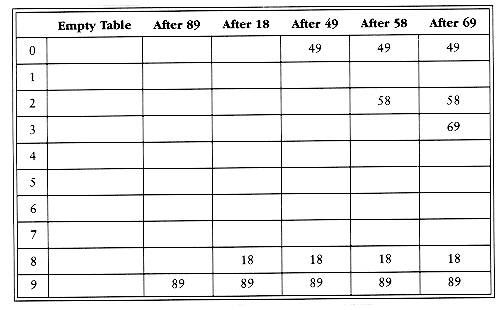
脑内调试一下:49和89冲突时,下一个空闲位置是0号单元。58和18冲突时,i=1也冲突,再试i=2,h2(58)=(8+4)%10=2是空的可以放。69同理。
对于线性探测法而言,我们得避免元素几乎填满的情况,因为这时候性能会急剧降低。对于平方探测法,这会更糟:如果表超过一半被填满,那当表的规模不是素数时,甚至在表被填满一般之前就已经不能一下找到空单元了,需要试探好几次才能找到一个空单元。原因是表最多有一半位置可以用来解决冲突。凭什么如此断言呢?Talk is cheap,show me your….proof.
定理
如果使用平方探测,且表的规模是素数,那么当表至少有一半是空的时候,总能插入新的元素。
我们假设表的Size是一个大于3的素数,直接拿着定理证明有点让人不知所措,那把这个定理的证明转化为:证明“前$\frac{\mbox{Si}ze}{2}$个备选位置是互异的”,然后用反证法。从所有前$\frac{\mbox{Si}ze}{2}$个的位置里选两个:( h(x) + i2 )%Size和( h(x) + j2 )%Size,其中 0 < i,j$ \leq \frac{\mbox{Si}ze}{2}$。假设这两个位置相同,且i ≠ j,然后让他们位置相等,推出矛盾就行了,因为都mod Size,根据等式性质我们只需要考察括号里的项就行了。
(h(x) + i2)=(h(x) + j2)
=> i2 = j2
=> (i-j)(i+j) = 0
前面说了i ≠ j,所以只可能i = - j。但是这和他们的定义域矛盾,所以也是不可能的。所以前一半位置互异,可供选择,任何元素都有$\frac{\mbox{Si}ze}{2}$个可能被放的位置。综上,如果最多有一半的位置可用,那么空闲单元总是能找到的。反过来讲,哪怕表里有一半+1个位置被填上,那么插入都有可能失败(虽然这比较偶然,但还是有可能的),这一点是十分重要的,要拿小本本记下来,说不定校招或考研就出题了哈哈哈。另外保证Size是素数也是非常重要的,如果不是的话,那遭遇冲突时可供选择的空单元个数会锐减到你难以置信的地步,远比一半少,这样一来,我们的战略纵深就太小了,难以迂回,这种情况没人希望见到。

Size=16的时候,找备选的单元只能取i=1,2,3,也就是距离冲突单元1,4,9个单位的位置了。
另外,在开放定址的散列表里,我们之前意义上的删除操作是不能进行的,因为某个数对应的单元可能已经引起过冲突了,然后他探测跑到别的位置了。比如我们要删除69,你find一下,定位到9,发现那躺着89,那我们只能跟着平方探测的思路再找找9+12,结果发现还不对,在那的是58。得,继续找吧,试试9+2^2,这才找到。想想吧,这才Size=10就这么费劲了,那企业级软件要处理千万级甚至亿级的数据怎么办,比如头条app的数据量,那程序还不跑到天荒地老。。。因此开放定址散列表需要懒惰删除。
谈谈怎么实现吧,先给出类型声明。在这里我们不用结构体数组,而使用散列表单元的数组,而且单元是动态分配地址这和分离链接一样。
#ifndef HashQuad_h
#define HashQuad_h
typedef unsigned int Index;
typedef Index Position;
struct HashTb1;
typedef struct HashTb1 *HashTable; HashTable Init(int size);
void DestroyTable(HashTable H);
void Insert(int key, HashTable H);
Position Find(int key,HashTable H);
int Retrieve(Position P);
HashTable ReTable(HashTable H);
#endif /* HashQuad_h */ enum KindOfEntry{
Legitimate,
Empty,
Deleted
}; struct HashEntry {
int value;
enum KindOfEntry Info;
}; typedef struct HashEntry Cell; /*Cell *TheCells will be an array of
HashEntry cells,allocated later
*/
struct HashTb1 {
int TableSize;
Cell *TheCells;
};
顺便一说,Hash函数还是设置为简单的%Size
Index Hash(int key,int size) {
return key%size;
}
初始化由2步组成:分配空间,然后将每个单元的Info设置为Empty。
#define aPrime 307
#define MinTableSize 5 HashTable Initial(int size){
HashTable H;
int i;
if (size<MinTableSize) {
printf("Table size too small\n");
return NULL;
}
//Allocate table
H=(HashTable)malloc(sizeof(struct HashTb1));
H->TableSize=aPrime;
//Allocate array of cells
H->TheCells=(Cell*)malloc(sizeof(Cell)*H->TableSize);
//Allocate list headers
for (i=; i<H->TableSize; i++)
H->TheCells[i].Info=Empty;
return H;
}
和分离链接一样,Find返回key在散列表里的单元号码。而且因为被标记了Empty,我们想表达查找失败也很容易。
Position Find(int key,HashTable H){
Position cur;
int CollisionNum=;
cur=Hash(key,H->TableSize);
while (H->TheCells[cur].Info != Empty &&
H->TheCells[cur].value!= key)
{
cur+= (++CollisionNum<<) - ;
if (cur>=H->TableSize)
cur-=H->TableSize;
}
return cur;
}
第8行到第10行是进行平方探测的快速方法,因为在实现的时候不太好判断进行到第几次探测了,所以直接算i^2不容易,另设个变量监测倒也可以,不过那样挺麻烦的,还占用空间,还多了一次监测变量的++,还多了一次判断,还多了一次平方运算,尤其是算平方开销太大了。所有的这些都会让效率变低。所以我们要把平方计算转化为单纯的+-计算,用i2 - ( i - 1 )2算出他们之间的差距是2 * i - 1,所以F(i)=F( i - 1 ) + 2 * i - 1这个几乎全是加减,乘法用移位代替速度就快多了。如果新的定位越过数组,那么可以通过-Size把它拉回到数组的范围里。这比通常办法快多了,因为他避免了看似要做的乘法和平方。第行的判断顺序很重要,别翻过来,不然短路性质就用不上了。
然后说插入,如果Key存在,就什么也不做,否则就把插入元素放在Find的位置。
void Insert(int key, HashTable H){
Position P=Find(key, H);
if (H->TheCells[P].Info != Legitimate)
{
H->TheCells[P].Info=Legitimate;
H->TheCells[P].value=key;
}
}
虽然平方探测法排除了一次聚集,但是散列到同一位置上的元素将探测相同的备选单元,这么说有点抽象,就是探测的时候都会踩同样的坑,比如说89,49,69这三个数往散列表里放,h0(49)撞到89了,试试i=1,可以了。69撞到89了然后试试i=1,算完之后h1(69)=0和h1(49)又撞了,这就叫“探测到相同的备选单元”,再试一次69才被安置。想想规模更大的表,相撞次数会更多,用f(i)=i2探测的时候分批扎堆,这就叫二次聚集,和之前相比,不是0,1,2,3这样连着一整块扎堆,而是在i=1,4,9,16附近扎堆。这是这两种聚集的区别。
二次聚集是理论上的一个缺憾,下一篇里我们继续讨论如何排除这个缺憾,从而对散列表冲突问题的排解更为高效和优美。不过这需要花费另外一些时间去做乘除法,比平方探测单纯的加减法慢一些,有利有弊吧,实际场景里因地制宜地选择不同模型就好。
开放定址法——平方探测(Quadratic Probing)的更多相关文章
- 开放定址法——线性探测(Linear Probing)
之前我们所采用的那种方法,也被称之为封闭定址法.每个桶单元里存的都是那些与这个桶地址比如K相冲突的词条.也就是说每个词条应该属于哪个桶所对应的列表,都是在事先已经注定的.经过一个确定的哈希函数,这些绿 ...
- java 解决Hash(散列)冲突的四种方法--开放定址法(线性探测,二次探测,伪随机探测)、链地址法、再哈希、建立公共溢出区
java 解决Hash(散列)冲突的四种方法--开放定址法(线性探测,二次探测,伪随机探测).链地址法.再哈希.建立公共溢出区 标签: hashmaphashmap冲突解决冲突的方法冲突 2016-0 ...
- Python与数据结构[4] -> 散列表[2] -> 开放定址法与再散列的 Python 实现
开放定址散列法和再散列 目录 开放定址法 再散列 代码实现 1 开放定址散列法 前面利用分离链接法解决了散列表插入冲突的问题,而除了分离链接法外,还可以使用开放定址法来解决散列表的冲突问题. 开放定 ...
- C# Dictionary源码剖析---哈希处理冲突的方法有:开放定址法、再哈希法、链地址法、建立一个公共溢出区等
C# Dictionary源码剖析 参考:https://blog.csdn.net/exiaojiu/article/details/51252515 http://www.cnblogs.com/ ...
- Java解决Hash(散列)冲突的四种方法--开放地址法(线性探测,二次探测,伪随机探测)、链地址法、再哈希、建立公共溢出区
最近时间有点紧,暂时先放参考链接了,待有时间在总结一下: 查了好多,这几篇博客写的真心好,互有优缺点,大家一个一个看就会明白了: 参考 1. 先看这个明白拉链法(链地址法),这个带源码,很好看懂,只不 ...
- Hash冲突的线性探测开放地址法
在实际应用中,无论如何构造哈希函数,冲突是无法完全避免的. 开放地址法 这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止.这个过程可用下式描述: ...
- [MIT6.006] 10. Open Addressing, Cryptographic Hashing 开放定址,加密哈希
前几节课讲散列表的时候,我们需要用Chaining,链接法需要用到指针pointer,但有一种方法可以不要Chaining和指针,还能在发生冲突时,为产生冲突的关键字寻找下一个"空" ...
- 面试准备 - HashTable 的C#实现 开放地址法
Hashtable是很经常在面试中遇到的数据结构,因为他的O(1)操作时间和O(n)空间 之所以自己写一份是因为: 加深对于hashtable的理解 某些公司面试的时候需要coding....... ...
- 开放地址法实现HashTable
前注:本文不是讲解Java类库的Hashtable实现原理,而是根据计算机哈希表原理自己实现的一个Hashtable. HashTable内部是用数组存放一个(Key-Value pair)键值对的引 ...
随机推荐
- thinkphp中怎么判断是手机端访问还是pc端访问?
function isMobile() { // 如果有HTTP_X_WAP_PROFILE则一定是移动设备 if (isset ($_SERVER['HTTP_X_WAP_PROFILE'])) r ...
- 【起航计划 013】2015 起航计划 Android APIDemo的魔鬼步伐 12 App->Activity->SetWallpaper 设置壁纸 WallpaperManager getDrawingCache使用
SetWallpaper介绍如何在Android获取当前Wallpaper,对Wallpaper做些修改,然后用修改后的图像重新设置Wallpaper.(即设置>显示>壁纸>壁纸的功 ...
- mysql> set sql_mode=''; mysql> set sql_mode='traditional';
mysql> set sql_mode=''; mysql> set sql_mode='traditional';
- Java运行机制及相关术语
JVM java虚拟机(Java Virtual Machine)JVM可以实现java程序的夸平台运行,即运行的操作平台各不相同 JVM基本原理 java运行机制 编译型语言(如C.C++) 源文件 ...
- Suggestion: use tools:overrideLibrary="android.support.v17.leanback" to force usage
Android Studio下修改方法: 在manifest中添加<uses-sdk tools:overrideLibrary="android.support.v17.leanba ...
- 简单的Nodejs模块
说千遍,道万遍,不如动手做一遍,我们实现一个node所谓的模块 看下上面的图,了解一下模块自始至终的一个流程,首先是创建模块,也就是一个入口的js文件,里面加了一些特定的功能,然后导出这个模块, ex ...
- P1151 子数整数
题目描述 对于一个五位数a_1a_2a_3a_4a_5a1a2a3a4a5,可将其拆分为三个子数: sub_1=a_1a_2a_3sub1=a1a2a3 sub_2=a_2a_3a_ ...
- 20145238-荆玉茗 《Java程序设计》第8周学习总结
20145238 <Java程序设计>第8周学习总结 教材学习内容总结 第15章 通用API 15.1.1 ·java.util.logging包提供了日志功能相关类与接口,使用日志的起点 ...
- Linux笔记(开机自动将kerne log保存到SD卡中)
有时候为了测试机器的稳定性,需要煲机测试几天的情况,这个时候机器已经封装好,不能再接串口线出来. 为了追溯问题,就需要将log信息保存下来. 于是就需要这样一个功能:系统启动后,自动将kernel的l ...
- iphone应用程序生命周期浅析
做iphone开发有必要知道iphone程序的生命周期,说白点就是当点击程序图标启动程序开始到退出程序整个使用运行过程中底下的代码都发生了什么,只有理解生命周期,有利于我们开发人员开发出更棒的应用 接 ...