Node.js 中流操作实践
本文节选自 Node.js CheatSheet | Node.js 语法基础、框架使用与实践技巧,也可以阅读 JavaScript CheatSheet 或者 现代 Web 开发基础与工程实践 了解更多 JavaScript/Node.js 的实际应用。
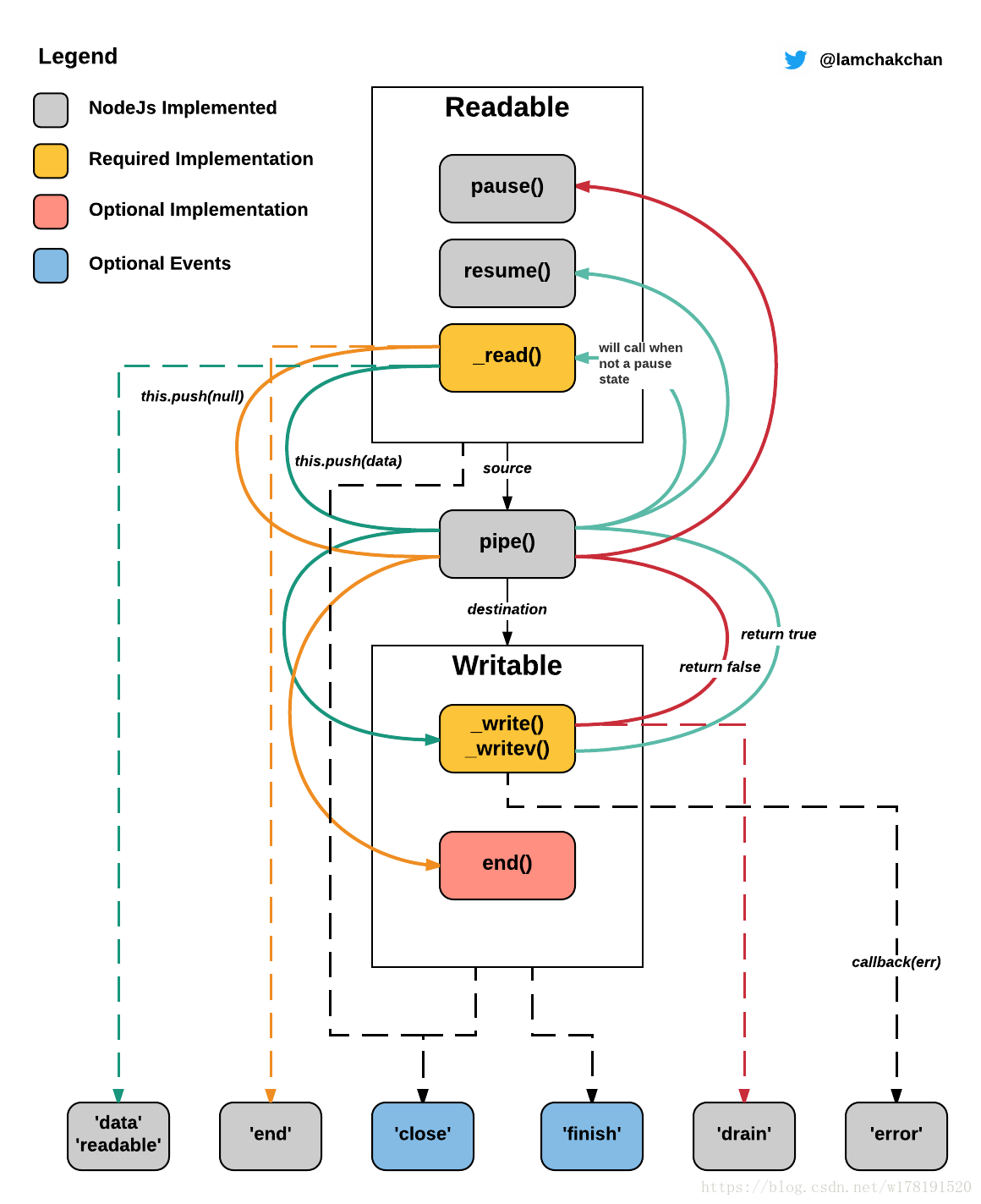
Stream 是 Node.js 中的基础概念,类似于 EventEmitter,专注于 IO 管道中事件驱动的数据处理方式;类比于数组或者映射,Stream 也是数据的集合,只不过其代表了不一定正在内存中的数据。。Node.js 的 Stream 分为以下类型:
- Readable Stream: 可读流,数据的产生者,譬如 process.stdin
- Writable Stream: 可写流,数据的消费者,譬如 process.stdout 或者 process.stderr
- Duplex Stream: 双向流,即可读也可写
- Transform Stream: 转化流,数据的转化者
Stream 本身提供了一套接口规范,很多 Node.js 中的内建模块都遵循了该规范,譬如著名的 fs 模块,即是使用 Stream 接口来进行文件读写;同样的,每个 HTTP 请求是可读流,而 HTTP 响应则是可写流。
Readable Stream
const stream = require('stream');
const fs = require('fs');
const readableStream = fs.createReadStream(process.argv[2], {
encoding: 'utf8'
});
// 手动设置流数据编码
// readableStream.setEncoding('utf8');
let wordCount = 0;
readableStream.on('data', function(data) {
wordCount += data.split(/\s{1,}/).length;
});
readableStream.on('end', function() {
// Don't count the end of the file.
console.log('%d %s', --wordCount, process.argv[2]);
});
当我们创建某个可读流时,其还并未开始进行数据流动;添加了 data 的事件监听器,它才会变成流动态的。在这之后,它就会读取一小块数据,然后传到我们的回调函数里面。 data 事件的触发频次同样是由实现者决定,譬如在进行文件读取时,可能每行都会触发一次;而在 HTTP 请求处理时,可能数 KB 的数据才会触发一次。可以参考 nodejs/readable-stream/_stream_readable 中的相关实现,发现 on 函数会触发 resume 方法,该方法又会调用 flow 函数进行流读取:
// function on
if (ev === 'data') {
// Start flowing on next tick if stream isn't explicitly paused
if (this._readableState.flowing !== false) this.resume();
}
...
// function flow
while (state.flowing && stream.read() !== null) {}
我们还可以监听 readable 事件,然后手动地进行数据读取:
let data = '';
let chunk;
readableStream.on('readable', function() {
while ((chunk = readableStream.read()) != null) {
data += chunk;
}
});
readableStream.on('end', function() {
console.log(data);
});
Readable Stream 还包括如下常用的方法:
- Readable.pause(): 这个方法会暂停流的流动。换句话说就是它不会再触发 data 事件。
- Readable.resume(): 这个方法和上面的相反,会让暂停流恢复流动。
- Readable.unpipe(): 这个方法会把目的地移除。如果有参数传入,它会让可读流停止流向某个特定的目的地,否则,它会移除所有目的地。
在日常开发中,我们可以用 stream-wormhole 来模拟消耗可读流:
sendToWormhole(readStream, true);
Writable Stream
readableStream.on('data', function(chunk) {
writableStream.write(chunk);
});
writableStream.end();
当 end() 被调用时,所有数据会被写入,然后流会触发一个 finish 事件。注意在调用 end() 之后,你就不能再往可写流中写入数据了。
const { Writable } = require('stream');
const outStream = new Writable({
write(chunk, encoding, callback) {
console.log(chunk.toString());
callback();
}
});
process.stdin.pipe(outStream);
Writable Stream 中同样包含一些与 Readable Stream 相关的重要事件:
- error: 在写入或链接发生错误时触发
- pipe: 当可读流链接到可写流时,这个事件会触发
- unpipe: 在可读流调用 unpipe 时会触发
Pipe | 管道
const fs = require('fs');
const inputFile = fs.createReadStream('REALLY_BIG_FILE.x');
const outputFile = fs.createWriteStream('REALLY_BIG_FILE_DEST.x');
// 当建立管道时,才发生了流的流动
inputFile.pipe(outputFile);
多个管道顺序调用,即是构建了链接(Chaining):
const fs = require('fs');
const zlib = require('zlib');
fs.createReadStream('input.txt.gz')
.pipe(zlib.createGunzip())
.pipe(fs.createWriteStream('output.txt'));
管道也常用于 Web 服务器中的文件处理,以 Egg.js 中的应用为例,我们可以从 Context 中获取到文件流并将其传入到可写文件流中:
Node.js 中流操作实践的更多相关文章
- Cookie和Session在Node.JS中的实践(二)
Cookie和Session在Node.JS中的实践(二) cookie篇在作者的上一篇文章Cookie和Session在Node.JS中的实践(一)已经是写得算是比较详细了,有兴趣可以翻看,这篇是s ...
- node.js高效操作mongodb
node.js高效操作mongodb Mongoose库简而言之就是在node环境中操作MongoDB数据库的一种便捷的封装,一种对象模型工具,类似ORM,Mongoose将数据库中的数据转换为Jav ...
- Node.js之操作文件系统(一)
Node.js之操作文件系统(一) 1. 同步方法与异步方法 在Node.js中,使用fs模块来实现所有有关文件及目录的创建.写入及删除操作.,在fs模块中,所有对文件及目录的操作都可以使用同步与异步 ...
- Node.js之操作文件系统(二)
Node.js之操作文件系统(二) 1.创建与读取目录 1.1 创建目录 在fs模块中,可以使用mkdir方法创建目录,该方法的使用方法如下: fs.mkdir(path,[mode],callbca ...
- 在Node.js中操作文件系统(一)
在Node.js中操作文件系统 在Node.js中,使用fs模块来实现所有有关文件及目录的创建,写入及删除操作.在fs模块中,所有对文件及目录的操作都可以使用同步与异步这两种方法.比如在执行读文件操作 ...
- Node.js文件操作二
前面的博客 Node.js文件操作一中主要是对文件的读写操作,其实还有文件这块还有一些其他操作. 一.验证文件path是否正确(系统是如下定义的) fs.exists = function(path, ...
- Cookie和Session在Node.JS中的实践(三)
Cookie和Session在Node.JS中的实践(三) 前面作者写的COOKIE篇.SESSION篇,算是已经比较详细的说明了两者间的区别.机制.联系了.阅读时间可能稍长,因为作者本身作图也做了不 ...
- [转] Node.js 服务端实践之 GraphQL 初探
https://medium.com/the-graphqlhub/your-first-graphql-server-3c766ab4f0a2#.n88wyan4e 0.问题来了 DT 时代,各种业 ...
- Node.js微服务实践(一)
什么是微服务 微服务是一种架构风格,一个大型复杂软件应用由一个或多个微服务组成.系统中的各个微服务可被独立部署,各个微服务之间是松耦合的.每个微服务仅关注于完成一件任务并很好地完成该任务.在所有情况下 ...
随机推荐
- python 用turtle 画小猪佩奇
from turtle import * def nose(x,y):#鼻子 penup()#提起笔 goto(x,y)#定位 pendown()#落笔,开始画 setheading(-30)#将乌龟 ...
- UiAutomator新建工程
新建工程步骤: 1.打开Eclipse 2.新建一个java工程UiAutomatorDemo1,然后新建一个包com.hhb 3.选中java工程,右击新建文件夹,命名为libs,在D:\Andro ...
- JavaFX常用汇总
1. 描述备注 1.1 参考教程 博客 易百教程 JavaFX中国 1.5 安装 a). 在线安装e(fx)clipse插件 b). 下载安装SceneBuilder c). eclipse重启以后, ...
- VMware下linux与window文件夹共享
这里说的是在虚拟机下来实现在windows下共享一个文件夹. 下面来说明一下是如何实现的: 1. 安装VMware.Workstation. 2. 安装Redhat Linux 9.0,在虚拟机下 ...
- How to Install VMware Tools on RHEL 7/CentOS 7
The original address Mware Tools is one of important components for virtual machine (VM) in order ge ...
- Spring整合Struts2 XML版
1.jar包 <!--spring配置--> <dependency> <groupId>org.springframework</groupId> & ...
- 在LINUX系统中MySQL数据库区分表名的大小写--解决办法
因为linux下mysql默认是要区分表名大小写的.mysql是否区分大小写设置是由参数lower_case_table_names决定的, 其中:1)lower_case_table_names = ...
- [Java]在xp系统下java调用wmic命令获取窗口返回信息无反应(阻塞)的解决方案
背景:本人写了一段java代码,调用cmd命令“wmic ...”来获取系统cpu.mem.handle等资源信息.在win7操作系统下运行没有问题,在xp系统下却发现读取窗口反馈信息时无反应(阻塞) ...
- LeetCode Unique Binary Search Trees (DP)
题意: 一棵BST有n个节点,每个节点的key刚好为1-n.问此树有多少种不同形态? 思路: 提示是动态规划. 考虑一颗有n个节点的BST和有n-1个节点的BST.从n-1到n只是增加了一个点n,那么 ...
- innobackupex基于binlog日志的恢复 -- 模拟slave恢复
说明:一般来说,如果恢复的binlog量不大,可以使用此方法来恢复:mysqlbinlog /data/mysqlbak/binlogbak/restoredb-bin.000018 |mysql - ...