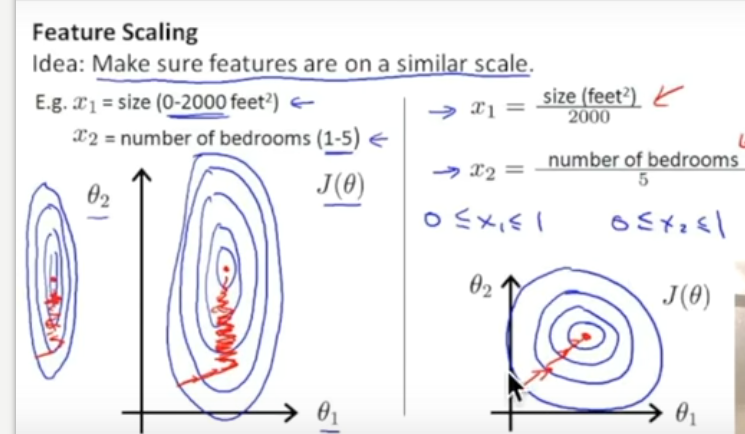
sklearn正规化(Normalization或者scale)
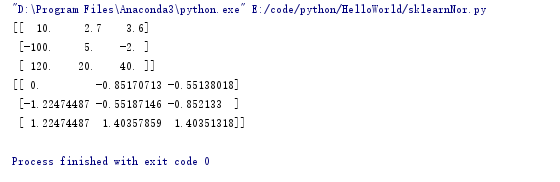
from sklearn import preprocessing
import numpy as np a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
print(a)
print(preprocessing.scale(a))
from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# print(a)
# print(preprocessing.scale(a))
X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=Y)
# plt.show()
#X=preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# print(a)
# print(preprocessing.scale(a))
X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=Y)
# plt.show()
X=preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

sklearn正规化(Normalization或者scale)的更多相关文章
- sklearn数据预处理-scale
对数据按列属性进行scale处理后,每列的数据均值变成0,标准差变为1.可通过下面的例子加深理解: from sklearn import preprocessing import numpy as ...
- normalization正规化
用到sklearn模块 from sklearn import preprocessing用preprocessing.scale正规化 print(preprocessing.scale(a))
- 机器学习-Sklearn
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一. Sklearn 包含了很多种机器学习的方式: Classification 分类 Regres ...
- Python中常用包——sklearn主要模块和基本使用方法
在从事数据科学的人中,最常用的工具就是R和Python了,每个工具都有其利弊,但是Python在各方面都相对胜出一些,这是因为scikit-learn库实现了很多机器学习算法. 加载数据(Data L ...
- 【机器学习学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 【机器学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 复盘一篇讲sklearn库的文章(下)
skleran-处理流程 获取数据 以用sklearn的内置数据集, 先导入datasets模块. 最经典的iris数据集作为例子. from sklearn import datasets iris ...
- Scikit-learn:数据预处理Preprocessing data
http://blog.csdn.net/pipisorry/article/details/52247679 本blog内容有标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 基础 ...
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
随机推荐
- 【Flask】视图高级
# 视图高级笔记:### `add_url_rule(rule,endpoint=None,view_func=None)`这个方法用来添加url与视图函数的映射.如果没有填写`endpoint`,那 ...
- Shiro身份认证-JdbcRealm
Subject 认证主体 Subject认证主体包含两个信息 Principals : 身份,可以是用户名.邮箱.手机号等,用来标识一个登录主体身份. Credentials : 凭证,常见有密码,数 ...
- Linux查看外网IP
Linux查看外网IP curl cip.cc curl ifconfig.me curl ipinfo.io
- java学习进度条四
- jQuery 开发一个简易插件
jQuery 开发一个简易插件 //主要内容 $.changeCss = function(options){ var defaults = { color:'blue', ele:'text', f ...
- 深度学习—池化、padding的理解
1.池化层的理解 pooling池化的作用则体现在降采样:保留显著特征.降低特征维度,增大kernel的感受野.另外一点值得注意:pooling也可以提供一些旋转不变性. 池化层可对提取到的特征信息进 ...
- string 中的 length函数 和size函数 返回值问题
string 中的 length函数 和 size函数 的返回值 ( 还有 char [ ] 中 测量字符串的 strlen 函数 ) 应该是 unsigned int 类型的 不可以 和 -1 ...
- js的trim方法(转)
写成类的方法格式如下:(str.trim();) <script language="javascript"> String.prototype.trim=functi ...
- log4j报错ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only err ...
- luogu1901 发射站
单调栈 正着插一遍反着插一遍 记录每个点左边右边第一个比他高的... yyc太强辣 #include<iostream> #include<cstdlib> #include& ...