sklearn正规化(Normalization或者scale)
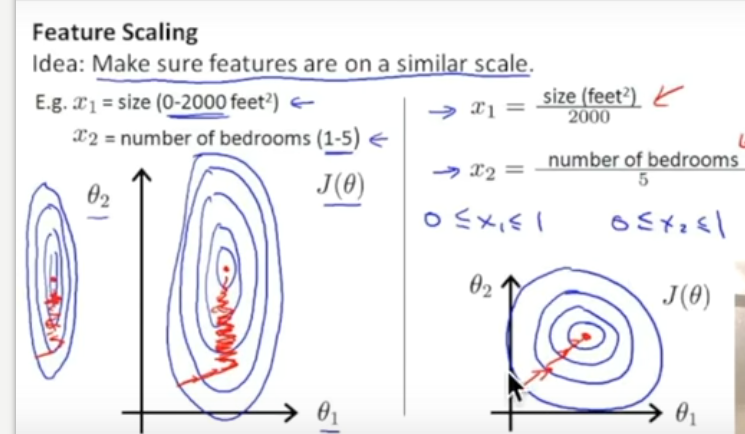
from sklearn import preprocessing
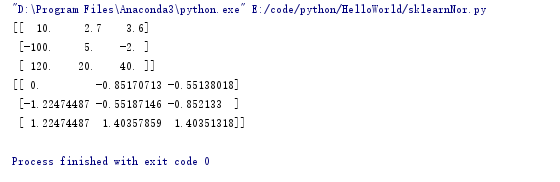
import numpy as np a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
print(a)
print(preprocessing.scale(a))
from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# print(a)
# print(preprocessing.scale(a))
X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=Y)
# plt.show()
#X=preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

from sklearn import preprocessing
import numpy as np
from sklearn.cross_validation import train_test_split
from sklearn.datasets.samples_generator import make_classification
from sklearn.svm import SVC
import matplotlib.pyplot as plt
# a = np.array([[10,2.7,3.6],[-100,5,-2],[120,20,40]],dtype=np.float64)
# print(a)
# print(preprocessing.scale(a))
X,Y = make_classification(n_samples=300,n_features=2,n_redundant=0,n_informative=2,random_state=22, n_clusters_per_class=1, scale=100)
# plt.scatter(X[:, 0], X[:, 1], c=Y)
# plt.show()
X=preprocessing.scale(X)
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3)
clf = SVC()
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))

sklearn正规化(Normalization或者scale)的更多相关文章
- sklearn数据预处理-scale
对数据按列属性进行scale处理后,每列的数据均值变成0,标准差变为1.可通过下面的例子加深理解: from sklearn import preprocessing import numpy as ...
- normalization正规化
用到sklearn模块 from sklearn import preprocessing用preprocessing.scale正规化 print(preprocessing.scale(a))
- 机器学习-Sklearn
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一. Sklearn 包含了很多种机器学习的方式: Classification 分类 Regres ...
- Python中常用包——sklearn主要模块和基本使用方法
在从事数据科学的人中,最常用的工具就是R和Python了,每个工具都有其利弊,但是Python在各方面都相对胜出一些,这是因为scikit-learn库实现了很多机器学习算法. 加载数据(Data L ...
- 【机器学习学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 【机器学习】SKlearn + XGBoost 预测 Titanic 乘客幸存
Titanic 数据集是从 kaggle下载的,下载地址:https://www.kaggle.com/c/titanic/data 数据一共又3个文件,分别是:train.csv,test.csv, ...
- 复盘一篇讲sklearn库的文章(下)
skleran-处理流程 获取数据 以用sklearn的内置数据集, 先导入datasets模块. 最经典的iris数据集作为例子. from sklearn import datasets iris ...
- Scikit-learn:数据预处理Preprocessing data
http://blog.csdn.net/pipisorry/article/details/52247679 本blog内容有标准化.数据最大最小缩放处理.正则化.特征二值化和数据缺失值处理. 基础 ...
- 采用梯度下降优化器(Gradient Descent optimizer)结合禁忌搜索(Tabu Search)求解矩阵的全部特征值和特征向量
[前言] 对于矩阵(Matrix)的特征值(Eigens)求解,采用数值分析(Number Analysis)的方法有一些,我熟知的是针对实对称矩阵(Real Symmetric Matrix)的特征 ...
随机推荐
- 【leetcode刷题笔记】Scramble String
Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty substrin ...
- Vue组件通信(传值)
先介绍一下什么是组件把: 创建组件的两种方式: 全局组件 // 组件就是vue的一个拓展实例 let component=Vue.extend({ data(){ return{ //与vue实例中的 ...
- 暑假集训第一周比赛C题
http://acm.hust.edu.cn/vjudge/contest/view.action?cid=83146#problem/C C - 学 Crawling in process... C ...
- 启动Hadoop时DFSZKFailoverController没有启动
在启动Hadoop成功后,并没有报错信息,jps查看进程,发现DFSZKFailoverController没有启动成功,后来发现是因为防火墙的原因,关掉重试就OK了 systemctl stop f ...
- jquery插件之jquery.extend和jquery.fn.extend的区别
jquery.extend jquery.extend(),是拓展jquery这个类,即可以看作是jquery这个类本身的静态方法,例如: <!DOCTYPE html> <html ...
- hdu3572线性欧拉筛
用线性筛来筛,复杂度O(n) #include<bits/stdc++.h> #include<ext/rope> #define fi first #define se se ...
- LSM Tree 学习笔记——MemTable通常用 SkipList 来实现
最近发现很多数据库都使用了 LSM Tree 的存储模型,包括 LevelDB,HBase,Google BigTable,Cassandra,InfluxDB 等.之前还没有留意这么设计的原因,最近 ...
- Struts2与OGNL
Action会自动放入值栈,成员变量会自动放入root区 如果是方法中的对象 要放入值栈 push()或者getRoot().push(); 界面取值 直接用对象的属性名进行取值
- java支付宝开发-00-资源帖
一.一些重要的官方文档 1.沙箱登录 2.沙箱环境使用说明 3.如何使用沙箱环境 4.当面付产品介绍 5.扫码支付接入指引 6.当面付快速接入 7.当面付接入必读 8.当面付进阶功能 9.当面付异步通 ...
- linux命令学习笔记(3):pwd命令
Linux中用 pwd 命令来查看”当前工作目录“的完整路径. 简单得说,每当你在终端进行操作时, 你都会有一个当前工作目录. 在不太确定当前位置时,就会使用pwd来判定当前目录在文件系统内的确切位置 ...