破解数据匮乏现状:纵向联邦学习场景下的逻辑回归(LR)
摘要:主要介绍了华为云可信智能计算服务(TICS)采用的纵向联邦逻辑回归(LR)方案。
本文分享自华为云社区《纵向联邦学习场景下的逻辑回归(LR)》,作者: 汽水要加冰。
海量训练数据是人工智能技术在各个领域成功应用的重要条件。例如,计算机视觉和商务经融推荐系统中的 AI 算法都依靠大规模标记良好的数据才能获得较好的推理效果。然而在医疗、银行以及一些政务领域中,行业内对数据隐私的保护越来越强,造成可用数据严重匮乏的现状。针对上述问题,华为云可信智能计算服务( TICS)专为打破银行、政企等行业的数据壁垒,实现数据安全共享,设计了多方联邦学习方案。
一、什么是逻辑回归?
回归是描述自变量和因变量之间相互依赖关系的统计分析方法。线性回归作为一种常见的回归方法,常用作线性模型(或线性关系)的拟合。
逻辑回归(logistic regression)虽然也称为回归,却不是一种模型拟合方法,而是一种简单的“二分类”算法。具有实现简单,算法高效等诸多优点。
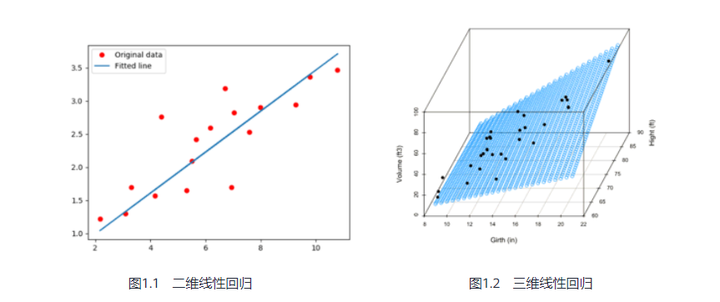
1.1 线性回归(linear regression)
图1.1、1.2分别表示二维和三维线性回归模型,图1.1的拟合直接(蓝线)可表示为 y=ax+b,所有数据点(红点)到直线的总欧式距离最短,欧式距离常用作计算目标损失函数,进而求解模型;类似的,图1.2的所有数据点到二维平面的总欧式距离最短。所以线性回归模型通常可以表示为:
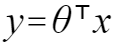
其中θ表示模型系数。
1.2 逻辑回归(LR)
LR是一种简单的有监督机器学习算法,对输入x,逻辑回归模型可以给出 y<0 or y>0 的概率,进而推断出样本为正样本还是负样本。
LR引入sigmoid函数来推断样本为正样本的概率,输入样本 x 为正样本的概率可以表示为:P(y|x) = g(y),其中 g() 为sigmoid函数,
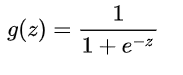
曲线图如图1.3所示,输出区间为0~1:
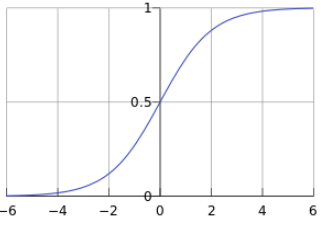
图1.3 sigmoid曲线
对于已知模型 θ 和样本 x,y=1的概率可以表示为:
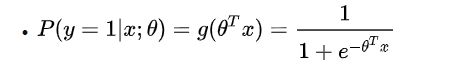
所以sigmoid尤其适用于二分类问题,当 g(y) > 0.5 时,表示 P(y=1|x) > 0.5,将其判为正样本,对应 y>0 ;反之,当 g(y) < 0.5 时,表示 P(y=1|x) < 0.5,将其判为负样本,对应 y<0。
1.3 LR损失函数
LR采用对数损失函数,对于训练集x∈S,损失函数可以表示为(参考https://zhuanlan.zhihu.com/p/44591359):
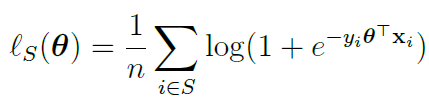
梯度下降算法是LR模型的经典解法之一,模型迭代更新的表达式如下:
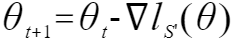
其中
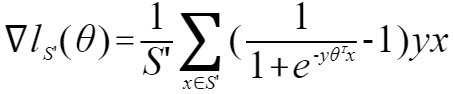
l()为目标损失函数,本质为平均对数损失函数。
- S'为批处理数据集(大小为batchsize),通过批处理方式引入随机扰动,使得模型权重更加快速逼近最优值。
- α为学习率,直接影响模型的收敛速度,学习率过大会导致loss左右震荡无法达到极值点,学习率太小会导致loss收敛速度过慢,长时间找不到极值点。
二、纵向联邦学习场景下的LR
关于纵向联邦学习的介绍已经屡见不鲜,市面上也涌现出很多优秀的产品,比如FATE、华为可信智能计算TICS等。纵向联邦可以实现多用户在不暴露己方数据的前提下,共享数据和特征,训练出精度更高的模型,对于金融和政务等众多行业具有重要意义。
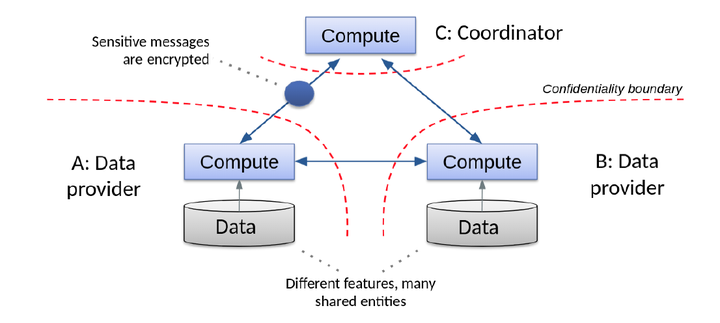
图2.1 纵向联邦LR
2.1 LR的纵向联邦实现
纵向联邦学习的参与方都是抱着共享数据、不暴露己方数据的目的加入到联邦中,所以任何敏感数据都必须经过加密才能出己方信任域(图2.1,参考https://arxiv.org/pdf/1711.10677.pdf),这就引入了同态加密算法。同态加密为密文计算提供了可行性,同时也一定程度上影响了机器学习算法的性能。常见的同态加密库包括seal、paillier等。
LR的纵向联邦流程如图2.2所示,host表示只有特征的一方,guest表示包含标签的一方。
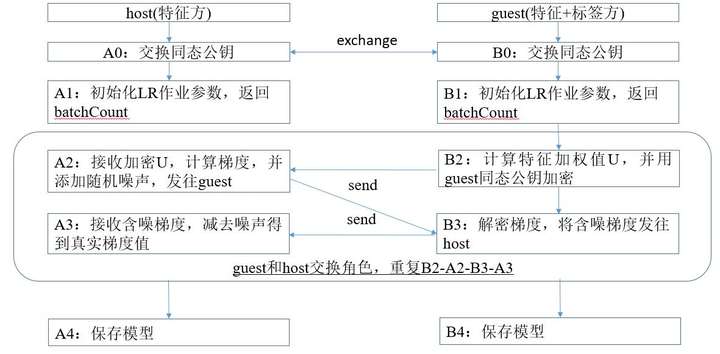
图 2.2 纵向联邦LR算法实现流程
- 在训练开始之前,作业双方需要交换同态公钥。
- 每轮epoch(迭代)的batch(一轮batchsize的计算为一个batch)循环中,包含calEncryptedU-->calEncryptedGradient-->decryptGradient-->updateLrModel四步,guest和host都需要按此顺序执行一遍( 流程图中只体现了guest作为发起方的执行流程)。
- A2步骤中梯度加随机噪声的目的是为了防止己方U泄露,造成安全问题。
由于同态加密计算只支持整数、浮点数的加法和乘法,所以将1.3中的模型迭代公式中的指数部分表示成泰勒表达式形式:
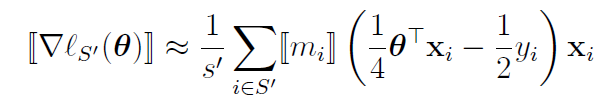
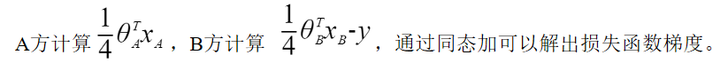
破解数据匮乏现状:纵向联邦学习场景下的逻辑回归(LR)的更多相关文章
- (数据科学学习手札24)逻辑回归分类器原理详解&Python与R实现
一.简介 逻辑回归(Logistic Regression),与它的名字恰恰相反,它是一个分类器而非回归方法,在一些文献里它也被称为logit回归.最大熵分类器(MaxEnt).对数线性分类器等:我们 ...
- SparkMLlib学习分类算法之逻辑回归算法
SparkMLlib学习分类算法之逻辑回归算法 (一),逻辑回归算法的概念(参考网址:http://blog.csdn.net/sinat_33761963/article/details/51693 ...
- [深度学习]Python/Theano实现逻辑回归网络的代码分析
2014-07-21 10:28:34 首先PO上主要Python代码(2.7), 这个代码在Deep Learning上可以找到. # allocate symbolic variables for ...
- 吴恩达深度学习:2.9逻辑回归梯度下降法(Logistic Regression Gradient descent)
1.回顾logistic回归,下式中a是逻辑回归的输出,y是样本的真值标签值 . (1)现在写出该样本的偏导数流程图.假设这个样本只有两个特征x1和x2, 为了计算z,我们需要输入参数w1.w2和b还 ...
- TensorFlow学习笔记2:逻辑回归实现手写字符识别
代码比较简单,没啥好说的,就做个记录而已.大致就是现建立graph,再通过session运行即可.需要注意的就是Variable要先初始化再使用. import tensorflow as tf fr ...
- 联邦学习(Federated Learning)
联邦学习简介 联邦学习(Federated Learning)是一种新兴的人工智能基础技术,在 2016 年由谷歌最先提出,原本用于解决安卓手机终端用户在本地更新模型的问题,其设计目标是 ...
- MindSpore联邦学习框架解决行业级难题
内容来源:华为开发者大会2021 HMS Core 6 AI技术论坛,主题演讲<MindSpore联邦学习框架解决隐私合规下的数据孤岛问题>. 演讲嘉宾:华为MindSpore联邦学习工程 ...
- 联邦学习开源框架FATE助力腾讯神盾沙箱,携手打造数据安全合作生态
近日,微众银行联邦学习FATE开源社区迎来了两位新贡献者——来自腾讯的刘洋及秦姝琦,作为云计算安全领域的专家,两位为FATE构造了新的功能点,并在Github上提交修复了相关漏洞.(Github项目地 ...
- 联邦学习(Federated Learning)
联邦学习的思想概括为:一种无需交换数据(只交换训练中间参数或结果)的分布式机器学习技术,在保护数据隐私的同时实现数据共享,解决数据孤岛问题. 本文仅介绍基本概念,详细请查看文末参考资料. 基本概念 联 ...
- 【流行前沿】联邦学习 Federated Learning with Only Positive Labels
核心问题:如果每个用户只有一类数据,如何进行联邦学习? Felix X. Yu, , Ankit Singh Rawat, Aditya Krishna Menon, and Sanjiv Kumar ...
随机推荐
- K8S - Jenkins在K8S下的持续集成
准备nfs网络存储 提前安装好nfs服务 [root@master ~]# yum -y install nfs-utils rpcbind [root@master ~]# systemctl st ...
- 2023华为杯·第二届中国研究生网络安全创新大赛初赛复盘 Writeup
A_Small_Secret 题目压缩包中有个提示和另一个压缩包On_Zen_with_Buddhism.zip,提示内容如下: 除了base64还有什么编码 MFZWIYLEMFSA==== asd ...
- nginx参数调优能提升多少性能
前言 nginx安装后一般都会进行参数优化,网上找找也有很多相关文章,但是这些参数优化对Nginx性能会有多大影响?为此我做个简单的实验测试下这些参数能提升多少性能. 声明一下,测试流程比较简单,后端 ...
- 04Java学习_DOS原理和路径详解
DOS原理和路径详解 目录 DOS原理和路径详解 DOS原理 路径详解 DOS常用命令 DOS原理 Dos:Disk Operating System 磁盘操作系统. 路径详解 相对路径:从当前目录开 ...
- DP:使用最小花费爬楼梯
数组的每个索引做为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost[i](索引从0开始). 每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯. 您需 ...
- Vite 5.0有哪些新变化?
Rollup 4 Vite 现在使用 Rollup 4,它也带来了一些重大的变化,特别是: 导入断言(assertions 属性)已被重命名为导入属性(attributes 属性). 不再支持 Aco ...
- .net中优秀依赖注入框架Autofac看一篇就够了
Autofac 是一个功能丰富的 .NET 依赖注入容器,用于管理对象的生命周期.解决依赖关系以及进行属性注入.本文将详细讲解 Autofac 的使用方法,包括多种不同的注册方式,属性注入,以及如何使 ...
- NodeJS下载安装
一.什么是NodeJS? NodeJS是一个开源,跨平台的JavaScript运行环境 二.NodeJS安装包下载 1.打开网址:Node.js (nodejs.org) 2.下载稳定版本 三.Nod ...
- Java八股面试整理(3)
21.说一说hashCode()和equals()的关系 hashCode()用于获取哈希码(散列码),eauqls()用于比较两个对象是否相等,它们应遵守如下规定: 如果两个对象相等,则它们必须有相 ...
- React 中虚拟DOM是什么,为什么需要它?
注意:本节主要讲React中的虚拟DOM,但是虚拟DOM并不是React中特有的内容. 1. React 中虚拟 DOM是什么? 虚拟DOM是对真实DOM的描述,虚拟DOM是JS对象,实际上就是 JS ...