火山引擎DataLeap的Data Catalog系统公有云实践 (下)
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
Data Catalog公有云遇到的挑战
网络和数据安全
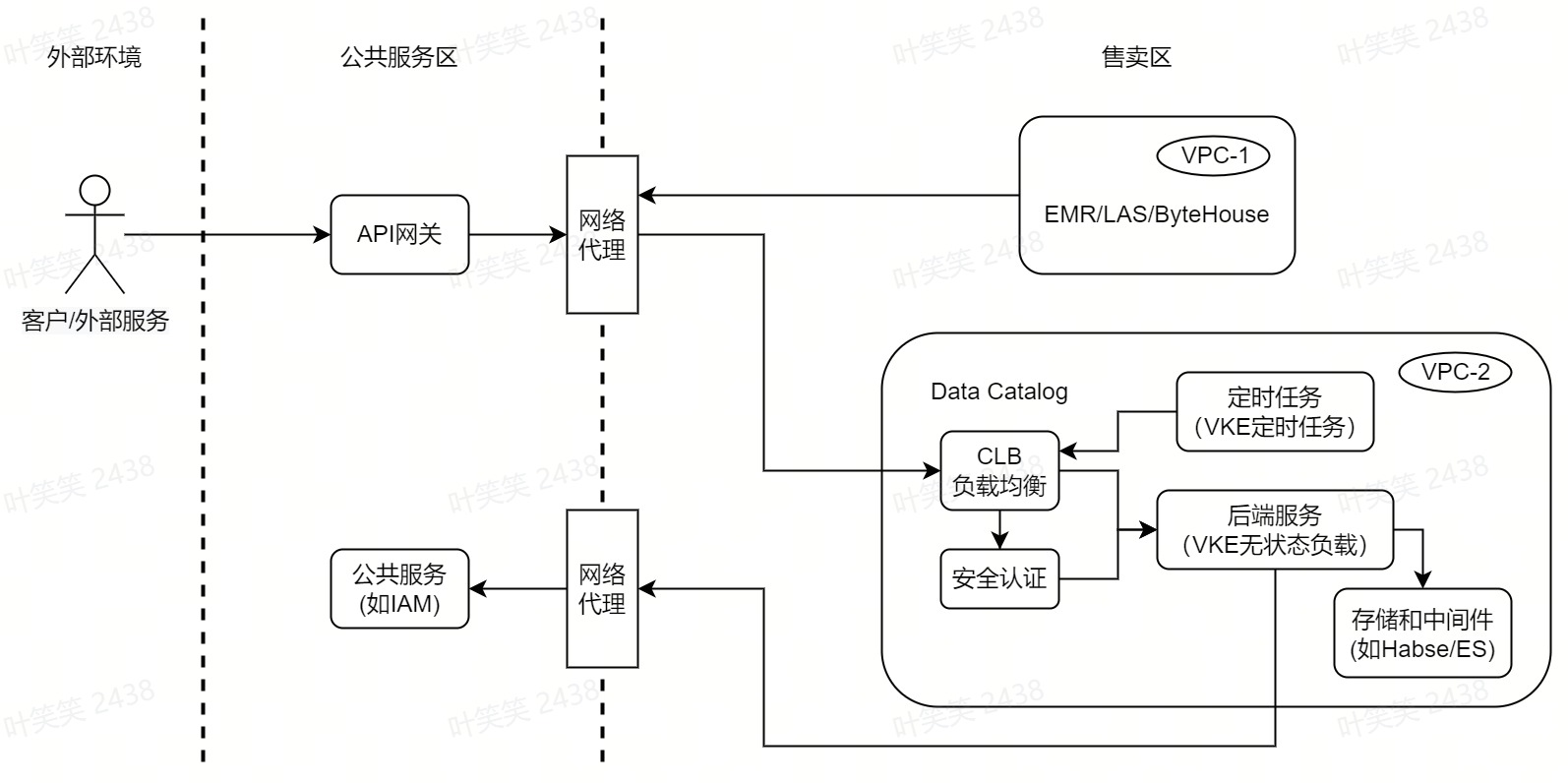
- 服务部署:为了能够在售卖区部署,经过调研我们选择火山引擎提供的容器服务(VKE)和负载均衡(CLB)来进行基础服务部署和构建,其中CLB提供四层负载均衡能力,容器服务是高性能 Kubernetes 容器集群管理服务。Data Catalog基于容器服务提供的无状态负载(Deployment)、定时任务(CronJob)、服务(Service)等云原生容器管理功能进行基本服务和调度任务部署,同时也使用火山引擎的存储和中间件,以上组件均在同一个VPC内,能够保证网络连通以及数据安全。
- 网络打通:为解决上文所说的网络隔离问题,经过调研我们使用了公司通用的网络代理服务(PLB/Shuttle),该网络代理可做到网络打通的同时保证四层网络流量的安全,从而达到我们和各依赖方如公共服务(API网关、IAM等、独立部署的云服务(EMR/LAS等)的网络连通目标。
- 数据安全:火山引擎部署环境做网络隔离,主要是保证安全性,我们虽然使用网络代理打通网络,但是仍需保证各个环节的安全性,考虑到服务间交互都是通过HTTP请求,我们对和外部交互的接口都增加了SSL和双向认证的机制,同时在安全认证方面,我们没有使用Nginx或Java原生的方案,而是借助于火山引擎内部安全服务中的ZTI团队的envoy组件来实现,同时使用sidecar模式和我们后端服务容器集成部署,既降低了服务端部署改造成本,也解耦了服务端业务逻辑和安全认证逻辑。
多租户适配
- 租户:一个客户、公司、个人开通或购买了火山引擎的云产品,火山引擎就会通知对应的服务提供者,对应云产品会感知到他的开通,这个客户就是这个云产品的一个租户,实际场景可以类比于一个公司是一个租户,不同的公司是不同的租户。
- 多租户服务:云服务要为多个租户提供服务,需要做到租户隔离,保证各租户的访问控制、数据、服务响应等各方面的使用都是隔离的,彼此互不感知互不影响的。要做到租户隔离,就需要云服务能通过逻辑或物理隔离的方式来将各租户对应数据和访问隔离开来,避免互相影响。
内外部功能一致
- 产品功能的标准化:原则上所有功能都应做到内外部一致,只允许部分功能点的实现区别。我们期望能将各功能都进行标准化,基础模块和通用能力(如元数据模型、搜索、血缘)原则上需保持内外一致,内外部依赖或需求场景差异较大的功能(如元数据接入和采集、库表管理)改造为标准化流程,将差异部分尽量减小,做到只通过配置、插件、版本控制工具等方式就能适配,减少研发和运维成本。
- 明确的一致性规划:从模块到功能点逐个对比内部外实现情况,制定长期roadmap,明确差异点的支持排期,并提高对齐内部功能的工作优先级,逐步减少差异。
- 新功能的兼容性:新功能的设计需考虑内外部一致性,包括产品的交互和研发的技术方案都需考虑外部场景并明确兼容方案,原则上对特殊场景定制化功能都需考虑通用场景适配,尽量保持多环境的兼容性。
- 统一的代码分支管理规范:原则上内外部的代码是一致的即统一的分支。具体来说,不管域内外功能都需兼容多环境并在多环境验证才能合并代码,外部如公有云在发版周期中会基于内部主分支代码(如master分支)创建一个新的release-x.x.x分支,进行回归验证和公有云上线,同时线上持续使用release-x.x.x分支以保证线上环境稳定,release-x.x.x分支需定期合回主分支。新的版本会继续基于主分支开发,并持续保持该规范。
- 明确的发版规划:根据实际情况,内部通常迭代比较敏捷发版频率较快,而外部通常要求稳定性,会定期发版(如每月一个版本),考虑到发版周期的差异,我们会以外部固定周期为标准,细粒度控制需求评估、功能开发、QA测试、回归测试等各环节所在时间段,明确封板时间,降低内外部互相影响。
- 一致性意识和自动化多环境验证:通过多轮分享和培训在技术团队内部对齐一致性意识,清楚内外部差异点FAQ等,另外,如上所说新功能技术设计方案需明确多环境兼容性。同时,引入自动化的多环境验证环节,尽早发现不兼容或不一致的问题,减少人工判断和测试的成本。
OpenAPI
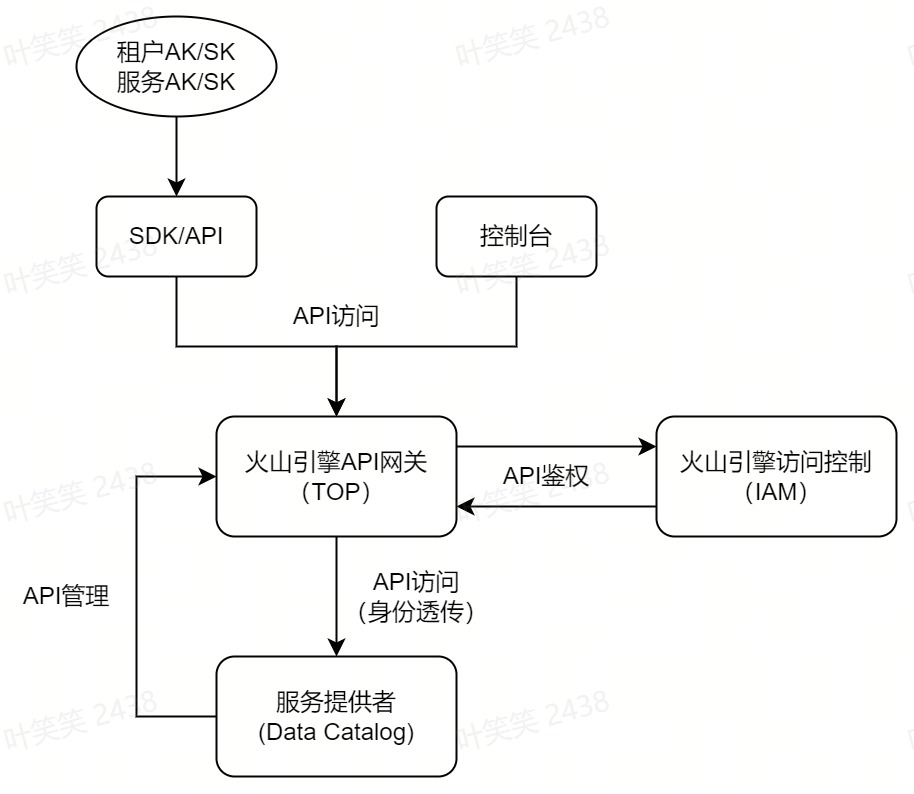
- Data Catalog借助于API网关管理OpenAPI,包括注册和开通、访问控制、限流等。
- API规范:火山引擎OpenAPI有明确的参数规范,Data Catalog也需符合该规范,但因内部OpenAPI参数格式不同,需做兼容,考虑到新API的支持成本,借助于Spring的Interceptor和Advice以及定制JSON序列化和反序列化逻辑,实现了自动的参数格式转化,降低API格式兼容的开发成本。
- 访问控制:火山引擎作为云服务提供商,使用业界规范的AKSK密钥管理规范,API使用者需创建AKSK并通过该信息来访问API才可通过访问控制,而API网关会通过IAM进行鉴权,通过后会给服务提供者也就是API注册者透传用户的身份(如租户ID,用户ID),方便API提供者使用。
- 安全认证:处理API网关提供的基础鉴权,Data Catalog也增加了更多机制来保障安全性,包括双向认证、租户开通状态检测等。
- API文档:对于每一个OpenAPI都根据火山引擎规范编写了详细的参数说明,汇总为一个正式API文档,方便用户查阅使用。
- 用户或服务通过AKSK访问API,或者通过前端控制台间接访问API。
- API网关通过IAM进行鉴权,将识别到的用户身份通过HTTP header透传给服务提供者。
- 服务提供者接收到请求并通过HTTP header获取用户身份,进行下一步处理。
总结
火山引擎DataLeap的Data Catalog系统公有云实践 (下)的更多相关文章
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 如何又快又好实现 Catalog 系统搜索能力?火山引擎 DataLeap 这样做
摘要 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理.资产.安全等全套数据中台建设,降低工作成本和数据维护成本.挖掘数据价 ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- 火山引擎 DataLeap:揭秘字节跳动数据血缘架构演进之路
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维 ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- 火山引擎DataLeap数据调度实例的 DAG 优化方案
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 实例 DAG 介绍 DataLeap 是火山引擎自研的一站式大数据中台解决方案,集数据集成.开发.运维.治理.资产管理能力 ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 字节跳动构建Data Catalog数据目录系统的实践(上)
作为数据目录产品,Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景,并服务于数据开发和数据治理的产品体系.本文介绍了字节跳动 Data ...
- 以字节跳动内部 Data Catalog 架构升级为例聊业务系统的性能优化
背景 字节跳动 Data Catalog 产品早期,是基于 LinkedIn Wherehows 进行二次改造,产品早期只支持 Hive 一种数据源.后续为了支持业务发展,做了很多修修补补的工作,系统 ...
- jQuery源代码解析(1)—— jq基础、data缓存系统
闲话 jquery 的源代码已经到了1.12.0版本号.据官网说1版本号和2版本号若无意外将不再更新,3版本号将做一个架构上大的调整.但预计能兼容IE6-8的.或许这已经是最后的样子了. 我学习jq的 ...
随机推荐
- [Python急救站]文本进度条
完游戏的朋友们,是不是看到那种加载加载进度条,感觉特别不错呢,所以今天就来看看文本进度条怎么做. 1.基本的多行文本进度条 import time scale = 10 # 变量scale表示输出进度 ...
- 初窥门径,从大模型到内容生成看AI新次元
视频云AI进化新纪元. 最近Gartner发布2024年十大战略技术趋势,AI显然成为其背后共同的主题.全民化的生成式人工智能.AI增强开发.智能应用......我们正在进入一个AI新纪元. 从Cha ...
- 轻松应对复杂集成场景!用友U8API开发适配
在企业上云的大趋势下,U8+ 全面转向互联网方向,深入融合云应用,一站式提供财务.营销.制造.采购.设计.协同.人力等领域的"端 + 云"服务,并通过软硬一体化.产业链协同的策略全 ...
- AntDesignBlazor示例——创建列表页
本示例是AntDesign Blazor的入门示例,在学习的同时分享出来,以供新手参考. 示例代码仓库:https://gitee.com/known/AntDesignDemo 1. 学习目标 使用 ...
- JavaWeb开发-HTML基础学习
1.HTML的基本语法 HTML是什么?:HTML是一种超文本标记语言,负责网页的结构,设计页面的元素内容等 超文本:超越文本限制,除了文本信息,还可以定义图片,音频,视频等 标记语言:由标签构成的语 ...
- 【VMware vSAN】主机之间网络性能测试,提示“无法运行网络性能测试。请稍后重试。”的处理过程。
vSAN集群监控,有一个主动测试功能,里面可以针对vSAN主机进行虚拟机创建测试.网络性能测试等. 官方解释: 虚拟机创建测试通常需要 20 至 40 秒时间,在超时情况下最长需要 180 秒时间.将 ...
- [CF1854D] Michael and Hotel
题目描述 Michael and Brian are stuck in a hotel with $ n $ rooms, numbered from $ 1 $ to $ n $ , and nee ...
- gridlayout
<?xml version="1.0" encoding="utf-8"?> <GridLayout xmlns:android=" ...
- SpringBoot整合JavaMail
1.发送简单邮件 导入依赖 implementation 'org.springframework.boot:spring-boot-starter-mail:3.0.2' 开启相关协议,获取密码~ ...
- FOJ有奖月赛-2015年11月 Problem A
Problem A 据说题目很水 Accept: 113 Submit: 445Time Limit: 1000 mSec Memory Limit : 32768 KB Problem ...