论文解读(SimGCL)《Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation》
Note:[ wechat:Y466551 | 可加勿骚扰,付费咨询 ]
论文信息
论文标题:Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation
论文作者:Junliang Yu, H. Yin, Xin Xia, Tong Chen, Li-zhen Cui, Quoc Viet Hung Nguyen
论文来源:SIGIR 2022
论文地址:download
论文代码:download
1 Introduction
本文是针对图对比学习在推荐系统中的应用而提出的相关方法。通常做对比学习的时候,需要对数据进行增广,得到相同数据的不同视图(view),然后进行对比学习,对于图结构也是一样,需要对用户-商品二部图进行结构扰动从而获得不同视图,然后进行对比学习最大化不同图扩充之间的节点表征一致性。
贡献:
- 通过实验阐明了为什么 CL 可以提高推荐性能,并说明了 InfoNCE 损失,而不是图的增强,是决定性的因素;
- 提出一种简单而有效的无图增强 CL 推荐方法,可以平滑地调节均匀性;
- 对三个基准数据集进行了全面的实验研究,结果表明,该方法在推荐精度和模型训练效率方面比基于图增强的方法具有明显的优势;
2 相关工作
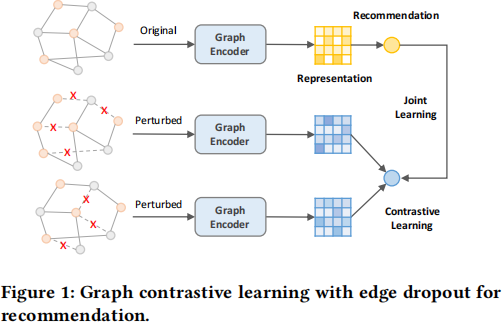
作者使用 SGL 进行了如下实验,探究图结构扰动在图对比学习中的作用。
SGL 训练目标如下:
$\mathcal{L}_{\text {joint }}=\mathcal{L}_{\text {rec }}+\lambda \mathcal{L}_{c l}$
$\mathcal{L}_{c l}=\sum_{i \in \mathcal{B}}-\log \frac{\exp \left(\mathbf{z}_{i}^{\prime \top} \mathbf{z}_{i}^{\prime \prime} / \tau\right)}{\sum_{j \in \mathcal{B}} \exp \left(\mathbf{z}_{i}^{\prime \top} \mathbf{z}_{j}^{\prime \prime} / \tau\right)}$
其中, $\mathbf{z}^{\prime}\left(\mathbf{z}^{\prime \prime}\right)$ 是从两个不同图增强中学习到的 $L_{2}$ 归一化后的节点表示。对比学习损失函数最大 化正样本之间的一致性,即来自同一节点的增强表示 $\mathbf{z}_{i}^{\prime}$ 和 $\mathbf{z}_{i}^{\prime \prime}$ ; 同时,最小化负样本之间的一致性,即两个不同节点的增强表示 $\mathbf{z}_{i}^{\prime}$ 和 $\mathbf{z}_{j}^{\prime \prime}$ 。
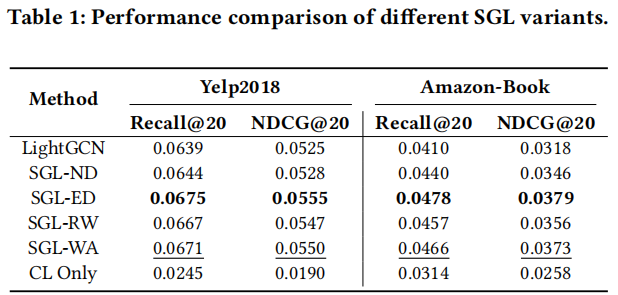
注意:ND 为 node dropout,ED 为 edge dropout,RW 为随机游走,WA 不进行数据增广。可以发现,不进行数据增广的情况下,只比增强低一点,说明其作用很小。
注意:SGL-WA :
$\mathcal{L}_{c l}=\sum_{i \in \mathcal{B}}-\log \frac{\exp (1 / \tau)}{\sum_{j \in \mathcal{B}} \exp \left(\mathbf{z}_{i}^{\top} \mathbf{z}_{j} / \tau\right)}$
3 InfoNCE 的影响
对比损失的优化有两个特性:
- alignment of features from positive pairs;
- uniformity of the normalized feature distribution on the unit hypersphere;
Note:
$\mathcal{L}_{\text {align }}(f ; \alpha) \triangleq \underset{(x, y) \sim p_{\text {pos }}}{\mathbb{E}}\left[\|f(x)-f(y)\|_{2}^{\alpha}\right], \quad \alpha>0$
$\begin{array}{l}\mathcal{L}_{\text {uniform }}(f ; t) &\triangleq \log \underset{x, y \text { i.i.d. }}{\mathbb{E}} p_{\text {data }}\left[G_{t}(u, v)\right] \\&=\log \underset{x, y \stackrel{\text { i.i.d. }}{\sim} p_{\text {data }}}{\mathbb{E}}\left[e^{-t\|f(x)-f(y)\|_{2}^{2}}\right], \quad t>0 \\\end{array}$
实验
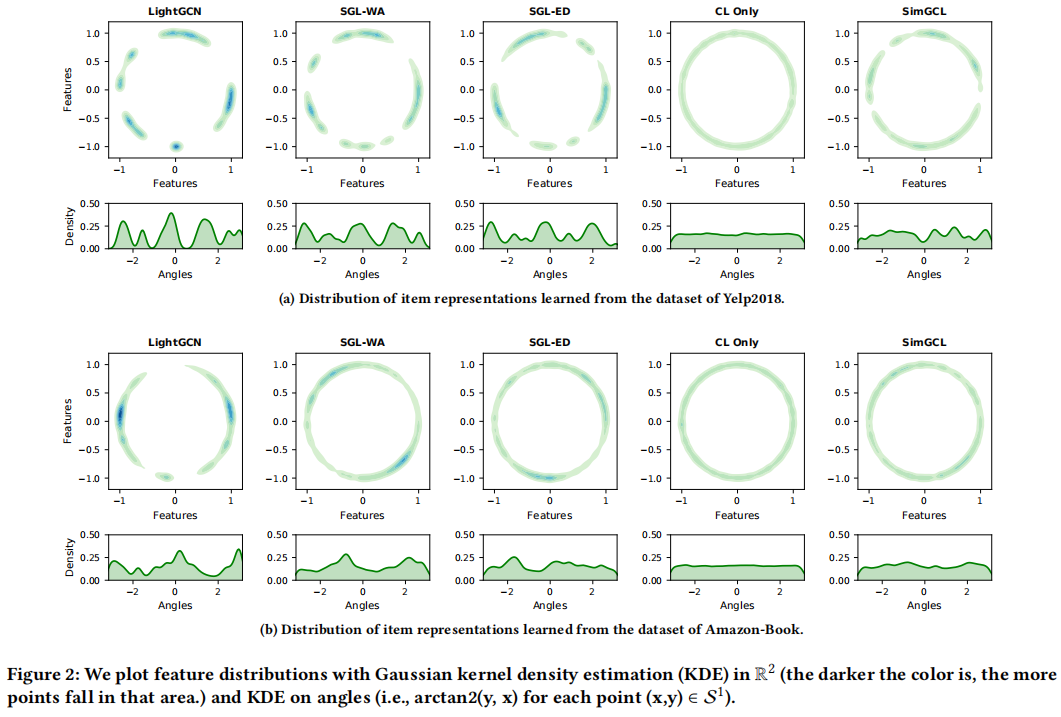
实验表明:
- LigthGCN 学习到的特征表示聚类现象更明显;
- SGL 结合对比学习的特征表示相对均匀;
- CL only 只有对比学习的特征分布均匀;
本文认为有两个原因可以解释高度聚集的特征分布:
- 消息传递机制,随着层数的增加,节点嵌入变得局部相似;
- 推荐数据中的流行度偏差,,由于推荐数据通常遵循长尾分布,当 $$ 是一个具有大量交互的流行项目时,用户嵌入将会不断更新到 $$ 的方向;
结论:即分布的均匀性是对 SGL 中的推荐性能有决定性影响的潜在因素,而不是图增强。优化 CL 损失可以看作是一种隐式的去偏倚的方法,因为一个更均匀的表示分布可以保留节点的内在特征,提高泛化能力。
4 方法
作者直接在表示中添加随机噪声,以实现有效的增强:
$\mathbf{e}_{i}^{\prime}=\mathbf{e}_{i}+\Delta_{i}^{\prime}, \quad \mathbf{e}_{i}^{\prime \prime}=\mathbf{e}_{i}+\Delta_{i}^{\prime \prime}$
约束:
- $\|\Delta\|_{2}=\epsilon $ 控制扰动在大小为 $\epsilon$ 的超球面上;
- $\Delta=\bar{\Delta} \odot \operatorname{sign}\left(\mathbf{e}_{i}\right), \bar{\Delta} \in \mathbb{R}^{d} \sim U(0,1) $ 控制扰动后的嵌入和原嵌入在同一超空间中;
图示如下:
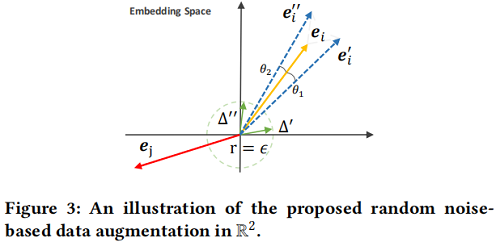
以 LightGCN 作为图编码器,在每一层增加随机噪声,可以得到最终的节点表示:
$\begin{array}{l}\mathbf{E}^{\prime}=&\frac{1}{L}\left(\left(\tilde{\mathrm{A}} \mathbf{E}^{(0)}+\Delta^{(1)}\right)+\left(\tilde{\mathrm{A}}\left(\tilde{\mathrm{A}} \mathbf{E}^{(0)}+\Delta^{(1)}\right)+\Delta^{(2)}\right)\right)+\ldots \\&\left.+\left(\tilde{\mathrm{A}}^{L} \mathbf{E}^{(0)}+\tilde{\mathrm{A}}^{L-1} \Delta^{(1)}+\ldots+\tilde{\mathrm{A}} \Delta^{(L-1)}+\Delta^{(L)}\right)\right)\end{array}$
注意,这里丢掉了最开始的输入表示 $\mathbf{E}^{(0)}$ ,因为作者实验发现,不增加初始输入会带来性能提升, 但对于 LigthGCN 会有性能下降。
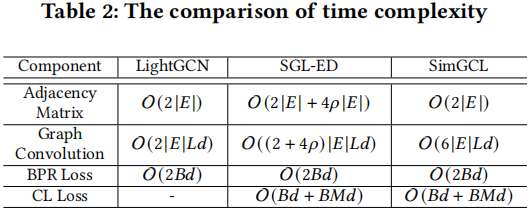
可以发现,相较于 SGL,SimGCL 的卷积复杂度会更高一些,作者也给出了如下图的理论分析。同时,作者也提到在实际实现中,由于卷积操作在GPU运算,且 SimGCL 只需要一次图构建,所以整 体上效率更高。
5 实验结果

参考:
[1] Understanding Contrastive Representation Learning through Alignment and Uniformity on the Hypersphere
论文解读(SimGCL)《Are Graph Augmentations Necessary? Simple Graph Contrastive Learning for Recommendation》的更多相关文章
- 论文解读(ClusterSCL)《ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs》
论文信息 论文标题:ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs论文作者:Yanling Wang, Jing ...
- 论文解读(LG2AR)《Learning Graph Augmentations to Learn Graph Representations》
论文信息 论文标题:Learning Graph Augmentations to Learn Graph Representations论文作者:Kaveh Hassani, Amir Hosein ...
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- 论文解读(GROC)《Towards Robust Graph Contrastive Learning》
论文信息 论文标题:Towards Robust Graph Contrastive Learning论文作者:Nikola Jovanović, Zhao Meng, Lukas Faber, Ro ...
- 论文解读(SimCLR)《A Simple Framework for Contrastive Learning of Visual Representations》
1 题目 <A Simple Framework for Contrastive Learning of Visual Representations> 作者: Ting Chen, Si ...
- 论文解读(DAGNN)《Towards Deeper Graph Neural Networks》
论文信息 论文标题:Towards Deeper Graph Neural Networks论文作者:Meng Liu, Hongyang Gao, Shuiwang Ji论文来源:2020, KDD ...
- 论文解读(MaskGAE)《MaskGAE: Masked Graph Modeling Meets Graph Autoencoders》
论文信息 论文标题:MaskGAE: Masked Graph Modeling Meets Graph Autoencoders论文作者:Jintang Li, Ruofan Wu, Wangbin ...
- 论文解读(Geom-GCN)《Geom-GCN: Geometric Graph Convolutional Networks》
Paper Information Title:Geom-GCN: Geometric Graph Convolutional NetworksAuthors:Hongbin Pei, Bingzhe ...
- 【论文解读】NIPS 2021-HSWA: Hierarchical Semantic-Visual Adaption for Zero-Shot Learning.(基于层次适应的零样本学习)
作者:陈使明 华中科技大学
- 论文解读(SUGRL)《Simple Unsupervised Graph Representation Learning》
Paper Information Title:Simple Unsupervised Graph Representation LearningAuthors: Yujie Mo.Liang Pen ...
随机推荐
- 2020-10-28:go中,好几个go程,其中一个go程panic,会产生什么问题?
福哥答案2020-10-28: 1.运行时恐慌,当panic被抛出异常后,如果我们没有在程序中添加任何保护措施的话,程序就会打印出panic的详细情况之后,终止运行.2.有panic的子协程里的def ...
- 2021-04-05:给两个长度分别为M和N的整型数组nums1和nums2,其中每个值都不大于9,再给定一个正数K。 你可以在nums1和nums2中挑选数字,要求一共挑选K个,并且要从左到右挑。返回所有可能的结果中,代表最大数字的结果。
2021-04-05:给两个长度分别为M和N的整型数组nums1和nums2,其中每个值都不大于9,再给定一个正数K. 你可以在nums1和nums2中挑选数字,要求一共挑选K个,并且要从左到右挑.返 ...
- 【Java】连接MySQL问题总结
前言 最近在学习Java的数据库相关操作,在看视频时自己找资源而产生的一些问题,在此做个总结. 正文 在刚开始学习的时候,你可能跟着老师这样写代码,虽然某些地方已经冒出了红色的波浪线,但你半信半疑的继 ...
- IntelliJ IDEA一站式配置【全】(提高开发效率)
IDEA常用设置(提高开发效率) 本人也是IDEA编译器的忠实用户了,但是有时出于各种原因,比如更换设备等等,IDEA总是需要重新安装配置.这就让我比较苦恼,因为总是记不全自己之前都修改了哪些地方(原 ...
- AcWing900.整数划分(python)
题目详情 知识点 计数类DP 分析题目,k个数是默认排好序的,也就是说,对于划分我们的考虑是无序的:例如 4 = 1+1+2 4 = 1+2+1 4 = 2+1+1 以上三种方式是没有区别的,所以在求 ...
- MassTransit实现Saga模式概览
原文地址:Saga Overview 编排一系列事件的能力是一个强大的功能,而MassTransit使这成为可能. saga是由协调器管理的长期事务.saga是由事件发起的,saga编排事件,saga ...
- defcon-quals 2023 crackme.tscript.dso wp
队友找到的引擎TorqueGameEngines/Torque3D (github.com) 将dso文件放到data/ExampleModule目录下,编辑ExampleModule.tscript ...
- K8s Pod状态与容器探针
1.pod的调度流程及常见状态 1.1.pod的调度流程 Pod创建过程如上图所示,首先用户向apiserver发送创建pod的请求,apiserver收到用于创建pod请求后,对应会对该用户身份信息 ...
- c# 如何将枚举以下拉数据源的形式返回给前端
前言: 相信各位有碰到过与我类似的问题,当表中存一些状态的字段,无非以下几种形式1.直接写死 如: 正常:1,异常:2 ,还有一种则是写在字典中,再或者就是加在枚举上,前两者对于返回下拉数据源来说比较 ...
- tvm-多线程代码生成和运行
本文链接 https://www.cnblogs.com/wanger-sjtu/p/16818492.html 调用链 tvm搜索算子在需要多线程运行的算子,是在codegen阶段时插入TVMBac ...