大语言模型基础-Transformer模型详解和训练
一、Transformer概述
Transformer是由谷歌在17年提出并应用于神经机器翻译的seq2seq模型,其结构完全通过自注意力机制完成对源语言序列和目标语言序列的全局依赖建模。
Transformer由编码器和解码器构成。图2.1展示了该结构,其左侧和右侧分别对应着编码器(Encoder)和解码器(Decoder)结构,它们均由若干个基本的 Transformer Encoder/Decoder Block(N×表示N次堆叠)。
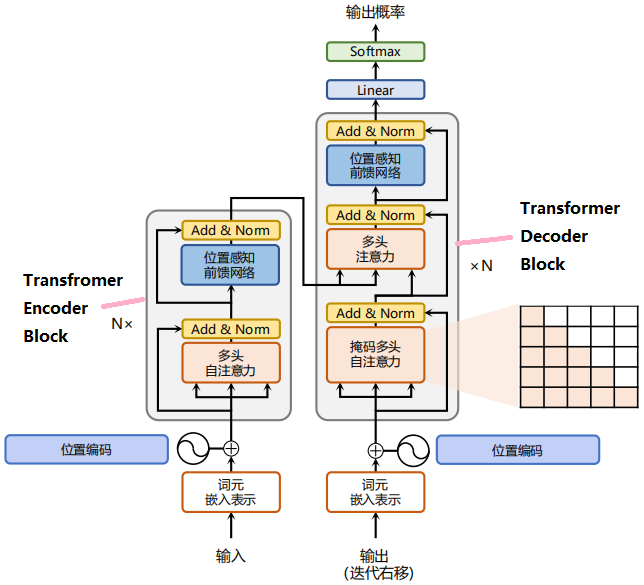
二、Transformer结构与实现
2.1、嵌入表示层
对于输入文本序列,首先通过输入嵌入层(Input Embedding)将每个单词转换为其相对应的向量表示。通常直接对每个单词创建一个向量表示。
注意:在翻译问题中,有两个词汇表,分别对应源语言和目标语言。
由于Transfomer中没有任何信息能表示单词间的相对位置关系,故需在词嵌入中加入位置编码(Positional Encoding)。
具体来说,序列中每一个单词所在的位置都对应一个向量。这一向量会与单词表示对应相加并送入到后续模块中做进一步处理。
在训练的过程当中,模型会自动地学习到如何利用这部分位置信息。
2.1.1、词元嵌入层
初始化词汇表(对词汇表进行压缩分词,得到词元list)
self.embedding = nn.Embedding(vocab_size, num_hiddens)
2.1.2、位置编码
为了使用序列的顺序信息,通过在输入表示中添加位置编码(positional encoding)来注入绝对的或相对的位置信息。位置编码可以通过学习得到也可以直接固定得到。
接下来描述的是基于正弦函数和余弦函数的固定位置编码。
2.1、多头自注意力(Multi-Head-self-Attention)
2.2.1、自注意力机制
1) 缩放点积注意力(scaled dot-product attention)
假设有查询向量(query) $ \mathbf{q} \in \mathbb{R}^{1 \times d} $ 和 键向量(key) $ \mathbf{k} \in \mathbb{R}^{1 \times d} $,查询向量和键向量点积的结果即为注意力得分。
\]
将缩放点积注意力推广到批量矩阵形势,其公式为:
\]
其中,\(\mathbf Q\in\mathbb R^{m\times d}\)、\(\mathbf K \in\mathbb R^{n\times d}\)、\(\mathbf V\in\mathbb R^{n\times d}\)。
考虑到在\(d\)过大时,点积值较大会使得后续Softmax操作溢出导致梯度爆炸,不利于模型优化。故将注意力得分除以\(\sqrt{d}\)进行缩放。
注:当\(m=1\)时,就是传统的注意力机制(1个\(q\), 多个\(k\),\(v\))。
import math
import torch
from torch import nn
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
# 设置transpose_b=True为了交换keys的最后两个维度
scores = torch.bmm(queries, keys.transpose(1,2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
为批量处理数据或在自回归处理时避免信息泄露等情况,在Token序列中填充[mask]Token,从而使一些值不纳入注意力汇聚计算。这里可指定一个有效序列长度(即Token个数), 以便在计算softmax时过滤掉超出指定范围的位置。
注:该缩放点积注意力的实现使用了dropout进行正则化。
masked_softmax函数实现了掩码\(softmax\)操作(masked softmax operation), 其中任何超出有效长度的位置都被掩蔽并置为\(0\)(将掩码位置的注意力系数变为无穷小\(-inf\),\(Softmax\)后的值为一个接近\(0\)的值)
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e9)
return nn.functional.softmax(X.reshape(shape), dim=-1)
def sequence_mask(X, valid_len, value=0):
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1)
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
X[~mask] = value
return X
2)自注意力
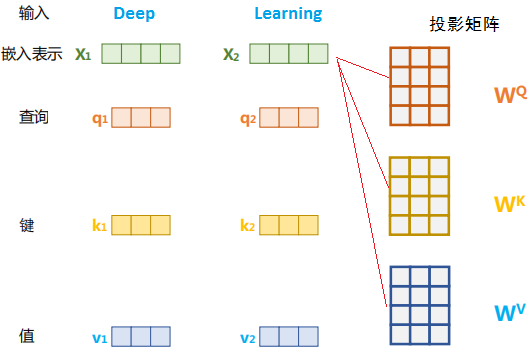
当n=m时,且\(\mathbf{Q}\)、\(\mathbf{K}\)、\(\mathbf{V}\)均源于输入\(\mathbf{X} \in\mathbb R^{n\times d}\)经过不同的线性变换时,缩放点积注意力即推广为自注意力。
这时,每个查询都会关注所有的键值对并生成一个注意力输出。 由于查询、键和值来自同一组输,故称为Self-Attention。
2.2.2、多头自注意力

class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
为了能够使多个头并行计算, 上面的MultiHeadAttention类将使用下面定义的两个转置函数。 具体来说,transpose_output函数反转了transpose_qkv函数的操作。
```python
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.transpose(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.transpose(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens, num_hiddens, num_heads, 0.5)
print(attention)
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
2.3、前馈网络
位置感知的前馈网络对序列中的所有位置的表示进行变换时使用的是同一个2层全连接网络,故称其为positionwise的前馈网络。
\]
在下面的实现中,输入X的形状(批量大小,时间步数或序列长度,隐单元数或特征维度)将被一个两层的感知机转换成形状为(批量大小,时间步数,ffn_num_outputs)的输出张量。
class PositionWiseFFN(nn.Module):
"""基于位置的前馈网络"""
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,
**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self, X):
return self.dense2(self.relu(self.dense1(X)))
2.4、残差连接和层规一化
add&norm组件是由残差连接和紧随其后的层规一化组成的,它被用来进一步提升训练的稳定性。
1)残差连接
残差连接引入输入直接到输出的通路,便于梯度回传从而缓解在优化过程中由于网络过深引起的梯度消失问题。
\]
2)层归一化
层归一化(Layer Normalization)是基于特征维度进行规范化,将数据进行标准化(乘以缩放系数、加上平移系数,保留其非线性能力。
\]
层归一化可以有效地缓解优化过程中潜在的不稳定、收敛速度慢等问题。
以下代码对比不同维度的层规范化和批量规范化的效果。
ln = nn.LayerNorm(2)
bn = nn.BatchNorm1d(2)
X = torch.tensor([[1, 2], [2, 3]], dtype=torch.float32)
# 在训练模式下计算X的均值和方差
print('layer norm:', ln(X), '\nbatch norm:', bn(X))
层归一化实现
class NormLayer(nn.Module):
def __init__(self, d_model, eps = 1e-6):
super().__init__()
self.size = d_model
# 层归一化包含两个可以学习的参数
self.alpha = nn.Parameter(torch.ones(self.size))
self.bias = nn.Parameter(torch.zeros(self.size))
self.eps = eps
def forward(self, x):
norm = self.alpha * (x - x.mean(dim=-1, keepdim=True)) \
/ (x.std(dim=-1, keepdim=True) + self.eps) + self.bias
return norm
使用残差连接和层规一化来实现AddNorm类
class AddNorm(nn.Module):
"""残差连接后进行层规范化"""
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y) + X)
2.5、编码器
有了组成Transformer编码器的基础组件,现在可以先实现编码器中的一个层。下面的EncoderBlock类包含两个子层:多头自注意力和基于位置的前馈网络,这两个子层都使用了残差连接和紧随的层规范化。
class EncoderBlock(nn.Module):
"""Transformer编码器块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout,
use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(
ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_lens):
Y = self.addnorm1(X, self.attention(X, X, X, valid_lens))
return self.addnorm2(Y, self.ffn(Y))
下面实现的Transformer编码器的代码中,堆叠了num_layers个EncoderBlock类的实例。由于这里使用的是值范围在-1和1之间的固定位置编码,因此通过学习得到的输入的嵌入表示的值需要先乘以嵌入维度的平方根进行重新缩放,然后再与位置编码相加。
class TransformerEncoder(Encoder):
"""Transformer编码器"""
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, dropout, use_bias))
def forward(self, X, valid_lens, *args):
# 因为位置编码值在-1和1之间,
# 因此嵌入值乘以嵌入维度的平方根进行缩放,
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_lens)
self.attention_weights[
i] = blk.attention.attention.attention_weights
return X
2.6、解码器
1) 掩码多头注意力
解码器的每个Transformer块的第一个自注意力子层额外增加了注意力掩码,对应图中的掩码多头注意力(Masked Multi-Head Attention)部分。
因为在翻译的过程中,编码器用于编码已知的源语言序列的信息,因而它只需要考虑如何融合上下文语义信息即可。而解码端则负责生成目标语言序列,这一自回归的过程意味着,在生成每一个单词时,仅有当前单词之前的目标语言序列是可观测的。
增加的Mask是用来避免模型在训练阶段直接看到后续的文本序列(信息泄露)进而无法得到有效地训练。
2) 交叉注意力
解码器端还增加了一个多头注意力(Multi-Head Attention)模块,使用交叉注意力(Cross-attention)方法,同时接收来自编码器端的输出以及当前 Transformer 块的前一个掩码注意力层的输出。
Query是通过解码器前一层的输出进行投影的,而Key和Value是使用编码器的输出进行投影的。它的作用是在翻译的过程当中,为了生成合理的目标语言序列需要观测待翻译的源语言序列是什么。
基于上述的编码器和解码器结构,待翻译的源语言文本,首先经过编码器端的每个Transformer块对其上下文语义的层层抽象,最终输出每一个源语言单词上下文相关的表示。
解码器端以自回归的方式生成目标语言文本,即在每个时间步t,根据编码器端输出的源语言文本表示,以及前 t -1 个时刻生成的目标语言文本,生成当前时刻的目标语言单词
class DecoderBlock(nn.Module):
"""解码器中第i个块"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.attention2 = MultiHeadAttention(
key_size, query_size, value_size, num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens,
num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
enc_outputs, enc_valid_lens = state[0], state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
state[2][self.i] = key_values
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(
1, num_steps + 1, device=X.device).repeat(batch_size, 1)
else:
dec_valid_lens = None
# 自注意力
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X, X2)
# 编码器-解码器注意力。
# enc_outputs的开头:(batch_size,num_steps,num_hiddens)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y, Y2)
return self.addnorm3(Z, self.ffn(Z)), state
2.7、Transformer
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
三、Transformer训练
损失
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction='none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train()
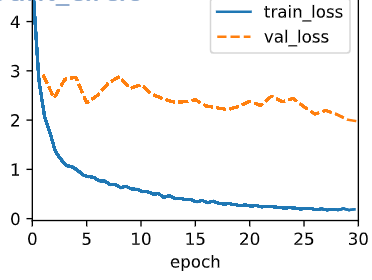
animator = d2l.Animator(xlabel='epoch', ylabel='loss',
xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad()
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0],
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len)
l = loss(Y_hat, Y, Y_valid_len)
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1)
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
训练语料为句子对
import torch
from torch import nn
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_hiddens, num_heads = 64, 4
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(
len(src_vocab), num_hiddens, ffn_num_hiddens, num_heads, num_layers,
dropout)
decoder = TransformerDecoder(
len(tgt_vocab), num_hiddens, ffn_num_hiddens, num_heads, num_layers,
dropout)
net = EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
# Test
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
参考链接
【1】大规模语言模型:从理论到实践, 第二章
【2】动手学深度学习 https://zh.d2l.ai/chapter_attention-mechanisms/transformer.html#id7
【3】NoteBook: https://colab.research.google.com/github/d2l-ai/d2l-pytorch-colab/blob/master/chapter_attention-mechanisms-and-transformers/transformer.ipynb#scrollTo=74f2da96
后续Todo
1、分词器
2、GPT系列
3、Llama2系列:原理、微调、预训练、SFT、RLHF
4、BERT系列
5、LLM训练推理加速
大语言模型基础-Transformer模型详解和训练的更多相关文章
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
- Transformer模型详解
2013年----word Embedding 2017年----Transformer 2018年----ELMo.Transformer-decoder.GPT-1.BERT 2019年----T ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- Java基础——IO模型详解
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- (转)总结之:CentOS 6.5 MySQL数据库的基础以及深入详解
总结之:CentOS 6.5 MySQL数据库的基础以及深入详解 原文:http://tanxw.blog.51cto.com/4309543/1395539 前言 早期MySQL AB公司在2009 ...
- css 06-CSS盒模型详解
06-CSS盒模型详解 #盒子模型 #前言 盒子模型,英文即box model.无论是div.span.还是a都是盒子. 但是,图片.表单元素一律看作是文本,它们并不是盒子.这个很好理解,比如说,一张 ...
- 图解机器学习 | LightGBM模型详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/34 本文地址:http://www.showmeai.tech/article-det ...
- 基础拾遗------webservice详解
基础拾遗 基础拾遗------特性详解 基础拾遗------webservice详解 基础拾遗------redis详解 基础拾遗------反射详解 基础拾遗------委托详解 基础拾遗----- ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
随机推荐
- 自己动手实现rpc框架(二) 实现集群间rpc通信
自己动手实现rpc框架(二) 实现集群间rpc通信 1. 集群间rpc通信 上一篇博客中MyRpc框架实现了基本的点对点rpc通信功能.而在这篇博客中我们需要实现MyRpc的集群间rpc通信功能. 自 ...
- Unity UGUI的Text(文本)组件的介绍及使用
UGUI的Text(文本)组件的介绍及使用 什么是UGUI的Text(文本)组件? UGUI(Unity Graphic User Interface)是Unity引擎的一套用户界面系统,而Text( ...
- [渗透测试]—4.2 Web应用安全漏洞
在本节中,我们将学习OWASP(开放网络应用安全项目)发布的十大Web应用安全漏洞.OWASP十大安全漏洞是对Web应用安全风险进行评估的标准,帮助开发者和安全工程师了解并防范常见的安全威胁. 1. ...
- 2023-07-11:给定正整数 n, 返回在 [1, n] 范围内具有 至少 1 位 重复数字的正整数的个数。 输入:n = 100。 输出:10。
2023-07-11:给定正整数 n, 返回在 [1, n] 范围内具有 至少 1 位 重复数字的正整数的个数. 输入:n = 100. 输出:10. 答案2023-07-11: 函数的主要思路如下: ...
- Kubernetes亲和性学习笔记
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本文是欣宸在学习Kubernetes调度器的 ...
- chrome事件循环的自问自答
chrome事件循环的自问自答 目录 1. 宏任务有哪些? 2. 微任务有哪些? 3. dom渲染是事件循环的一部分么? 4. requestAnimationFrame的回调是宏任务还是微任务? 5 ...
- Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/fs/FSDataInputStream
伪 分布模式下启动spark报错 从spark1.4以后,所有spark的编译都是没有将hadoop的classpath编译进去的,所以必须在spark-env.sh中指定hadoop中的所有jar包 ...
- Go语言中指针详解
指针在 Go 语言中是一个重要的特性,它允许你引用和操作变量的内存地址.下面是指针的主要作用和相关示例代码: 1. 引用传递 在 Go 中,所有的变量传递都是值传递,即复制变量的值.如果你想在一个函数 ...
- 王道oj/problem10
地址:http://oj.lgwenda.com/problem/10 思路:首先创建字符串赋初值,其次用gets()输入字符串[fgets()相对于gets()会多识别"\n", ...
- asp.net core之异常处理
在开发过程中,处理错误是一个重要的方面.ASP.NET Core提供了多种方式来处理错误,以确保应用程序的稳定性和可靠性. TryCatch TryCatch是最常见也是最基础的一种异常处理方式,只需 ...