集成学习与随机森林(二)Bagging与Pasting
Bagging 与Pasting
我们之前提到过,其中一个获取一组不同分类器的方法是使用完全不同的训练算法。另一个方法是为每个预测器使用同样的训练算法,但是在训练集的不同的随机子集上进行训练。在数据抽样时,如果是从数据中重复抽样(有放回),这种方法就叫bagging(bootstrap aggregating 的简称,引导聚合)。当抽样是数据不放回采样时,这个称为pasting。
换句话说,bagging与pasting都允许训练数据条目被多个预测器多次采样,但是仅有bagging允许训练数据条目被同一个预测器多次采样。在pasting中,每个预测器仅能对同一条训练数据条目采样一次。Bagging的采样与训练的过程如下图所示:
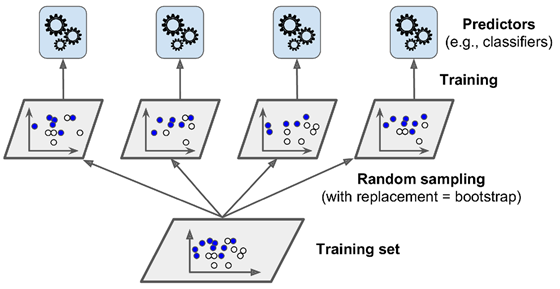
在所有预测器都训练好后,集成器可以对一条新数据做预测,它会简单地聚集所有预测器的预测值。这个聚集方法通常在分类问题中是一个统计模型(也就是说,使用出现最频繁的预测,与投票分类器中的硬投票类似),而在回归问题中是一个平均值。每个单独预测器的bias(偏差值)相对于他们在原始训练集上训练的bias会更高,不过集成会同时减少bias与variance(方差)。一般来说,集成的结果与单个模型,两者的bias值较为接近,但是集成的variance会更低。
在上图中我们也可以看到,模型可以并行进行训练,使用不同的CPU核或是不同的服务器。类似的,预测也可以并行完成。这也是为什么当今bagging与pasting如此令人受欢迎的原因之一:它们的扩展性非常好。
Sk-learn中的Bagging与Pasting
Sk-learn提供了一个简单的API用于bagging与pasting,BaggingClassifier类(或BaggingRegressor类做回归任务)。下面的代码训练一个由500棵决策树组成的集成:每个均在100条随机采样的训练数据条目上进行训练,且数据采样有放回(也就是bagging的例子,如果要用pasting,指定bootstrap=False即可)。n_jobs 参数指定sk-learn在训练与预测时使用的CPU核数(-1表示使用所有可用资源):
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
max_samples=100, bootstrap=True, n_jobs=-1) bag_clf.fit(X_train, y_train)
y_pred = bag_clf.predict(X_test)
在BaggingClassifier中,如果基于的基本分类器是可以估计类别概率的话(例如它包含predict_proba() 方法),则BaggingClassifier 会自动执行软投票(soft voting),而不是硬投票。在上面的例子中,基本分类器是决策树,所以它执行的是软投票。
下图对比了单个决策树的决策边界与bagging集成500棵树(上面的代码)的决策边界,两者均在moon数据集上进行训练。我们可以看到,集成预测的泛化性能会更好:集成与单个决策树的bias差不多,但是集成的variance更小。
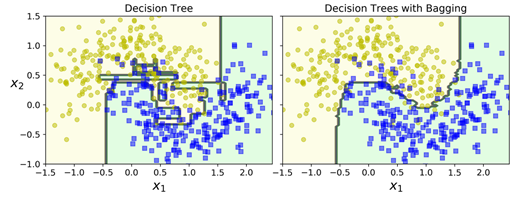
Bootstraping在每个模型使用的训练子集中引入了更多的多样性,所以bagging最终的bias会稍高于pasting一些;但是额外的多样性也意味着最终模型之间的相关性会更小,所以集成的variance会减少。总之,bagging一般相对于pasting会产生更好的模型,这也是为什么我们一般倾向于使用bagging。不够如果有足够的时间和CPU的话,我们可以使用交叉验证来评估bagging与pasting的性能,并选择其中表现最好的那个。
Out-of-Bag评估
使用bagging时,有些数据条目可能会被任一模型采样多次,而其他数据条目可能从来都不会被采样。默认情况下,BaggingClassifier会以有放回(bootstrap=True)的方式采样m条训练数据,这里m为训练集的大小。也就是说,对每个模型来说,平均大约仅有63%的训练数据条目会被采样到。剩下大约37% 的(没有被采样的)训练数据条目称为out-of-bag(oob)实例。
由于模型在训练中并不会看到oob实例,所以可以使用这些实例对模型进行评估,而不需要使用额外的验证集。我们可以通过取每个模型的oob评估的平均,作为集成的评估。
在sk-learn 中,我们在创建BagginClassifier时可以设置 oob_score=True,这样可以在训练结束后
启用一个自动的oob评估。下面的代码是展示的这个例子,评估结果分数可以通过oob_score_变量获取:
bag_clf = BaggingClassifier(
DecisionTreeClassifier(), n_estimators=500,
bootstrap=True, n_jobs=-1, oob_score=True
) bag_clf.fit(X_train, y_train)
bag_clf.oob_score_
>0.8986666666666666
根据oob的评估结果,这个BaggingClassfier可能会在测试集上达到89.8%的准确率,下面我们验证一下:
from sklearn.metrics import accuracy_score y_pred = bag_clf.predict(X_test)
accuracy_score(y_test, y_pred)
>0.904
在测试集上的准确度为90.4%,结果比较接近。
对每条训练集的oob决策函数也可以通过oob_decision_funcsion_ 变量获取。在上面的这个例子中(由于base estimator 有 predict_proba() 方法),决策函数会对每条训练数据返回它属于某个类别的概率。例如,oob 评估第一条训练数据有58.6%的概率属于正类,41.4%的概率属于负类。
bag_clf.oob_decision_function_
>array([[0.41361257, 0.58638743],
[0.37016575, 0.62983425],
[1. , 0. ],
[0. , 1. ],
…
集成学习与随机森林(二)Bagging与Pasting的更多相关文章
- 大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2)
大白话5分钟带你走进人工智能-第二十九节集成学习之随机森林随机方式 ,out of bag data及代码(2) 上一节中我们讲解了随机森林的基本概念,本节的话我们讲解随机森 ...
- bagging与boosting集成学习、随机森林
主要内容: 一.bagging.boosting集成学习 二.随机森林 一.bagging.boosting集成学习 1.bagging: 从原始样本集中独立地进行k轮抽取,生成训练集.每轮从原始样本 ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 机器学习之——集成算法,随机森林,Bootsing,Adaboost,Staking,GBDT,XGboost
集成学习 集成算法 随机森林(前身是bagging或者随机抽样)(并行算法) 提升算法(Boosting算法) GBDT(迭代决策树) (串行算法) Adaboost (串行算法) Stacking ...
- 2. 集成学习(Ensemble Learning)Bagging
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 集成学习算法汇总----Boosting和Bagging(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习:集成学习(OOB 和 关于 Bagging 的更多讨论)
一.oob(Out - of - Bag) 定义:放回取样导致一部分样本很有可能没有取到,这部分样本平均大约有 37% ,把这部分没有取到的样本称为 oob 数据集: 根据这种情况,不对数据集进行 t ...
- 集成学习算法总结----Boosting和Bagging
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 集成学习算法总结----Boosting和Bagging(转)
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 【机器学习实战】第7章 集成方法(随机森林和 AdaBoost)
第7章 集成方法 ensemble method 集成方法: ensemble method(元算法: meta algorithm) 概述 概念:是对其他算法进行组合的一种形式. 通俗来说: 当做重 ...
随机推荐
- JavaScript之变量解构赋值的使用
引言 解构赋值是ES6中引入的一种能快速方便的进行变量赋值的方法,其主要也就是分为解构和赋值两部分内容.解构者,也就是匹配结构,然后分解结构进行赋值. 数组的解构赋值 使用 const arr = [ ...
- Educational Codeforces Round 160 (Rated for Div. 2)
A 直接模拟,注意细节 #include<bits/stdc++.h> #define ll long long using namespace std; ll p[15] = {1}; ...
- 超轻量级的c#版基于文件的日志记录工具,可定制输出格式,可指定日志文件
这是我自己个人编写的日志记录,主要使用在只需要记录日志,偶尔到文件中查看一下日志记录的情况.我自己写的一些服务之类的是使用了这个的,代码很少,使用很简单. 第一步 搜索和安装我的Nuget包 搜索和安 ...
- nginx与location规则
========================================================================= 2018年3月28日 记录: location = ...
- Threading Programming Guide:One
苹果支持的产生线程的方式 Operation Object 使用OperationQueue,具体可以参考:Concurrency Programming Guide GCD 使用诸如dispatch ...
- 几行命令用minikube快速搭建可测试的kubernetes单节点环境
几行命令用minikube快速搭建可测试的kubernetes单节点环境 需要docker环境,https://www.cnblogs.com/xiaofei12/p/17544579.html,网速 ...
- 现代农业|AIRIOT智慧农业管理解决方案
智慧农业是现代化技术在农业领域的应用和成果,其中物联网技术在促生产.保产量和降本增效方面起到了至关重要的作用.运用传感技术和软件平台系统对农业生产进行智能化平台化管理,解决掉传统农业问题的诸多痛点 ...
- 我对asp.net管道模型的理解
参考:http://www.tracefact.net/tech/001.htmlhttps://www.xuebuyuan.com/zh-hant/470245.html我们的web程序被iis启动 ...
- 如何启动?win11下的Linux子系统【4种方法】
实验室的开发环境在Linux操作系统下,时不时就需要打开Linux环境去操作,而且需要本地编译或者远程SSH.这时候window和Linux切换很不方便.本科的做法就是window+虚拟机的Linux ...
- Jenkins通过脚本进行自动发布
编写以下脚本: ------------------------------------------------------------------------------------- #!/bin ...