请注意,你的 Pulsar 集群可能有删除数据的风险
在上一篇 Pulsar3.0新功能介绍中提到,在升级到 3.0 的过程中碰到一个致命的问题,就是升级之后 topic 被删除了。
正好最近社区也补充了相关细节,本次也接着这个机会再次复盘一下,毕竟这是一个非常致命的 Bug。
现象
先来回顾下当时的情况:升级当晚没有出现啥问题,各个流量指标、生产者、消费者数量都是在正常范围内波动。
事后才知道,因为只是删除了很少一部分的 topic,所以从监控中反应不出来。
早上上班后陆续有部分业务反馈应用连不上 topic,提示 topic nof found.
org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'Producer': Invocation of init method failed; nested exception is org.apache.pulsar.client.api.PulsarClientException$TopicDoesNotExistException: Topic Not Found.
因为只是部分应用在反馈,所以起初怀疑是 broker 升级之后导致老版本的 pulsar-client 存在兼容性问题。
所以我就拿了平时测试用的 topic 再配合多个老版本的 sdk 进行测试,发现没有问题。
直到这一步还好,至少证明是小范故障。
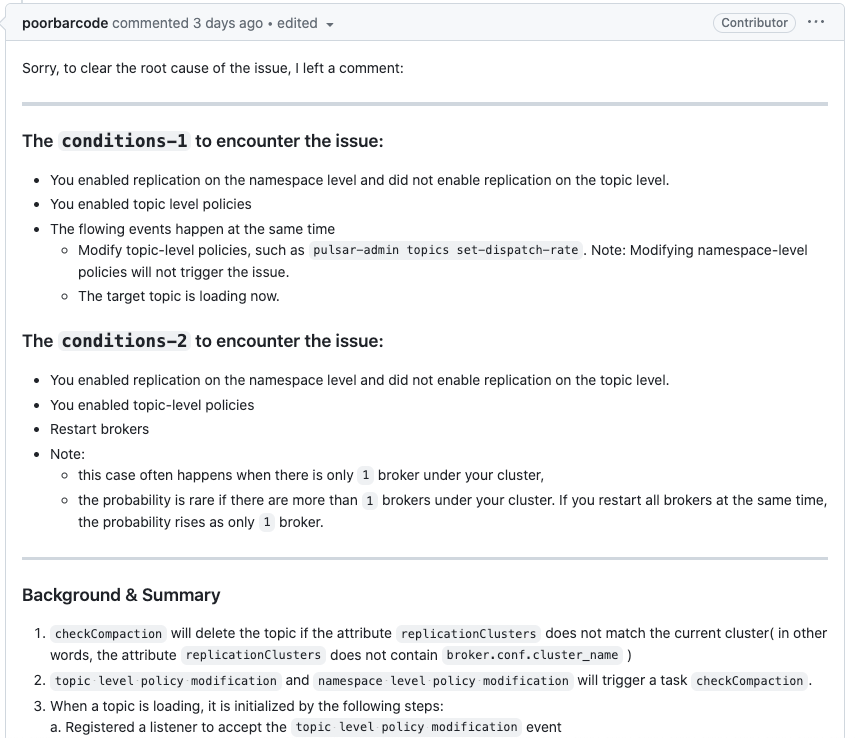
因为提示的是 topic 不存在,所以就准备查一下 topic 的元数据是否正常。
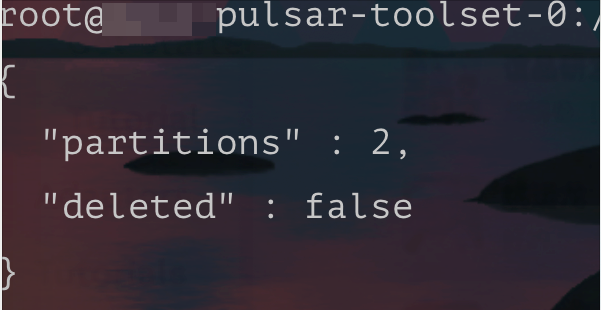
查询后发现元数据是存在的。
之后我便想看看提示了 topic 不存在的 topic 的归属,然后再看看那个 broker 中是否有异常日志。

发现查看归属的接口也是提示 topic 不存在,此时我便怀疑是 topic 的负载出现了问题,导致这些 topic 没有绑定到具体的 broker。
于是便重启了 broker,结果依然没有解决问题。
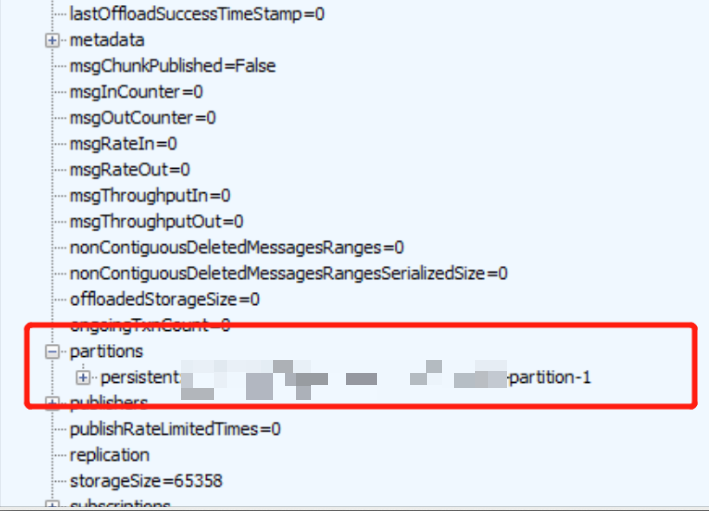
之后我们查询了 topic 的 internal state 发现元数据中会少一个分区。
紧急恢复
我们尝试将这个分区数恢复后,发现这个 topic 就可以正常连接了。
于是再挑选了几个异常的 topic 发现都是同样的问题,恢复分区数之后也可以正常连接了。
所以我写了一个工具遍历了所有的 topic,检测分区数是否正常,不正常时便修复。
void checkPartition() {
String namespace = "tenant/ns";
List<String> topicList = pulsarAdmin.topics().getPartitionedTopicList(namespace);
for (String topic : topicList) {
PartitionedTopicStats stats = pulsarAdmin.topics().getPartitionedStats(topic, true);
int partitions = stats.getMetadata().partitions;
int size = stats.getPartitions().size();
if (partitions != size) {
log.info("topic={},partitions={},size={}", topic, partitions, size);
pulsarAdmin.topics().updatePartitionedTopic(topic, partitions);
}
}
}
排查
修复好所有 topic 之后便开始排查根因,因为看到的是元数据不一致所以怀疑是 zk 里的数据和 broker 内存中的数据不同导致的这个问题。
但我们查看了 zookeeper 中的数据发现一切又是正常的,所以只能转变思路。
之后我们通过有问题的 topic 在日志中找到了一个关键日志:

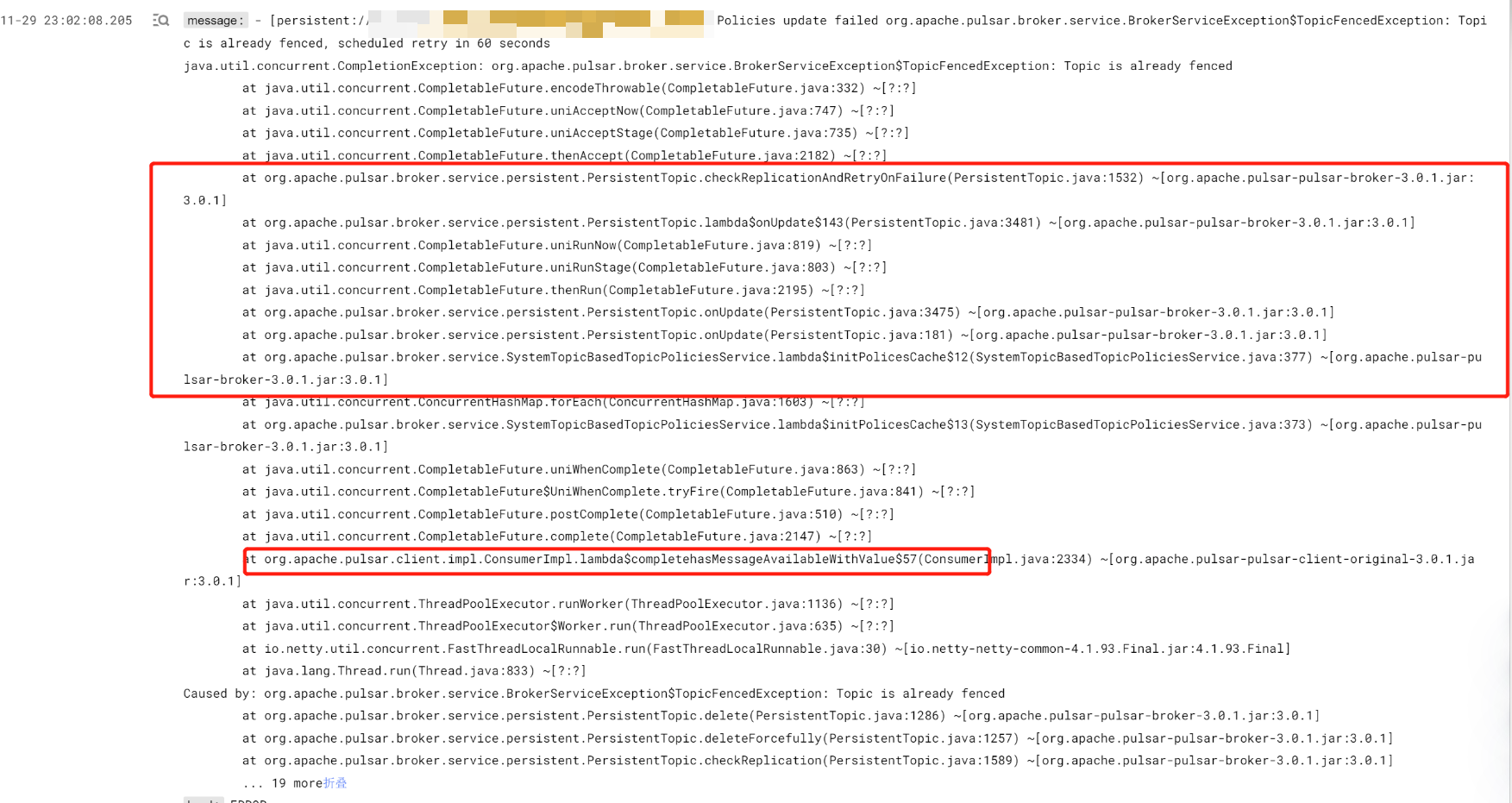
以及具体的堆栈。
此时具体的原因已经很明显了,元数据这些自然是没问题;根本原因是 topic 被删除了,但被删除的 topic 只是某个分区,所以我们在查询 internalState 时才发发现少一个 topic。
通过这个删除日志定位到具体的删除代码:
org.apache.pulsar.broker.service.persistent.PersistentTopic#checkReplication
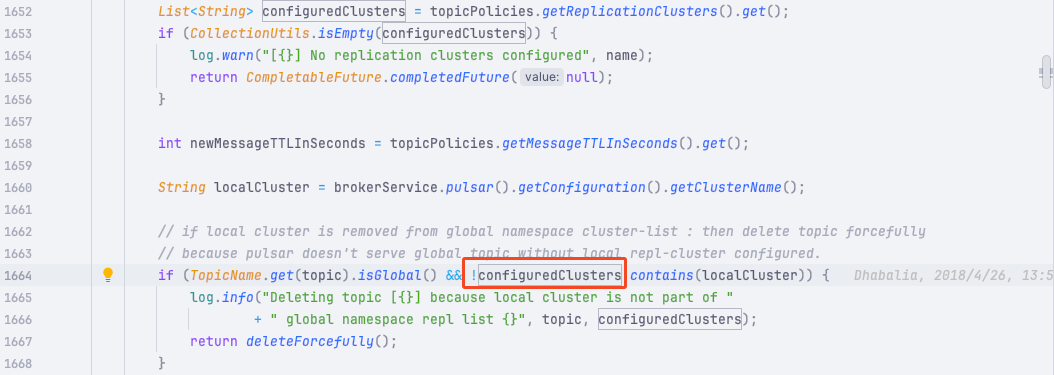
原来是这里的 configuredClusters 值为空才导致的 topic 调用了 deleteForcefully()被删除。
而这个值是从 topic 的 Policy 中获取的。
复现问题
通过上图中的堆栈跟踪,怀疑是重启 broker 导致的 topic unload ,同时 broker 又在构建 topic 导致了对 topicPolicy 的读写。
最终导致 topicPolicy 为空。
只要写个单测可以复现这个问题就好办了:
@Test
public void testCreateTopicAndUpdatePolicyConcurrent() throws Exception {
final int topicNum = 100;
final int partition = 10;
// (1) Init topic
admin.namespaces().createNamespace("public/retention");
final String topicName = "persistent://public/retention/policy_with_broker_restart";
for (int i = 0; i < topicNum; i++) {
final String shadowTopicNames = topicName + "_" + i;
admin.topics().createPartitionedTopic(shadowTopicNames, partition);
}
// (2) Set Policy
for (int i = 90; i < 100; i++) {
final String shadowTopicNames = topicName + "_" + i;
CompletableFuture.runAsync(() -> {
while (true) {
PublishRate publishRate = new PublishRate();
publishRate.publishThrottlingRateInMsg = 100;
try {
admin.topicPolicies().setPublishRate(shadowTopicNames, publishRate);
} catch (PulsarAdminException e) {
}
}
});
}
for (int i = 90; i < 100; i++) {
final String shadowTopicNames = topicName + "_" + i;
CompletableFuture.runAsync(() -> {
while (true) {
try {
admin.lookups().lookupPartitionedTopic(shadowTopicNames);
} catch (Exception e) {
}
}
});
}
admin.namespaces().unload("public/retention");
admin.namespaces().unload("public/retention");
admin.namespaces().unload("public/retention");
Thread.sleep(1000* 5);
for (int i = 0; i < topicNum; i++) {
final String shadowTopicNames = topicName + "_" + i;
log.info("check topic: {}", shadowTopicNames);
PartitionedTopicStats partitionedStats = admin.topics().getPartitionedStats(shadowTopicNames, true);
Assert.assertEquals(partitionedStats.getPartitions().size(), partition);
}
}
同时还得查询元数据有耗时才能复现:

只能手动 sleep 模拟这个耗时
具体也可以参考这个 issue
https://github.com/apache/pulsar/issues/21653#issuecomment-1842962452
此时就会发现有 topic 被删除了,而且是随机删除的,因为出现并发的几率本身也是随机的。
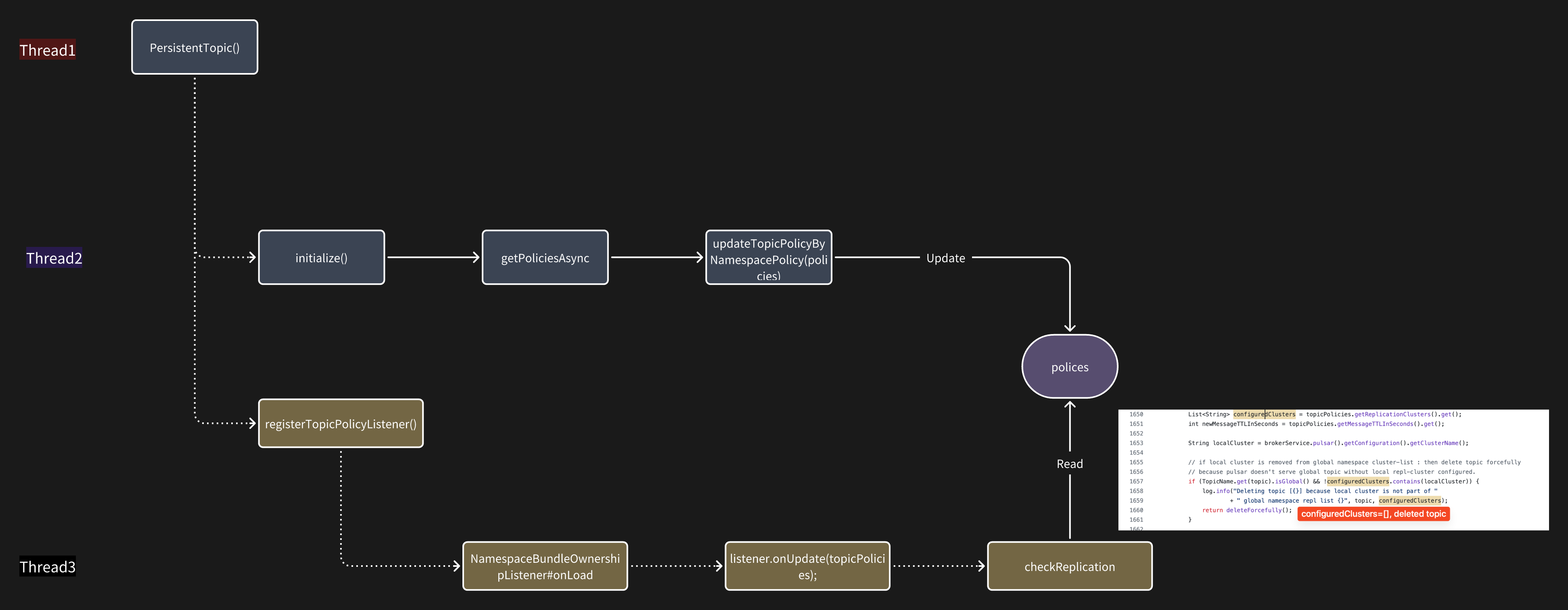
这里画了一个流程图就比较清晰了,在 broker 重启的时候会有两个线程同时topicPolicy 进行操作。
在 thread3 读取 topicPolicy 进行判断时,thread2 可能还没有把数据准备好,所以就导致了 topic 被删除。
修复
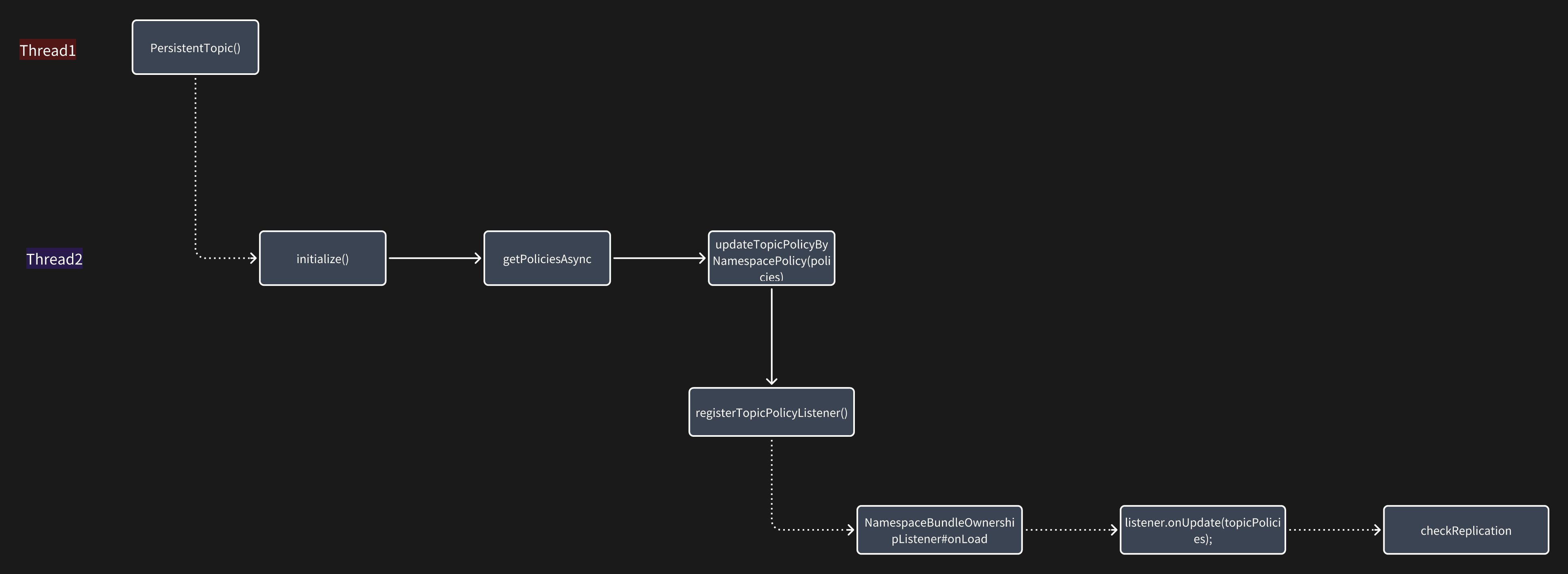
既然知道了问题原因就好修复了,我们只需要把 thread3 和 thread2 修改为串行执行就好了。
这也是处理并发最简单高效的方法,就是直接避免并发;加锁、队列啥的虽然也可以解决,但代码复杂度也高了很多,所以能不并发就尽量不要并发。
但要把这个修复推送到社区上游主分支最好是要加上单测,这样即便是后续有其他的改动也能保证这个 bug 不会再次出现。
之后在社区大佬的帮助下完善了单测,最终合并了这个修复。
再次证明写单测往往比代码更复杂,也更花费时间。
PR:https://github.com/apache/pulsar/pull/21704
使用修复镜像
因为社区合并代码再发版的周期较长,而我们又急于修复该问题;不然都不敢重启 broker,因为每重启一次都可能会导致不知道哪个 topic 就被删除了。
所以我们自己在本地构建了一个修复的镜像,准备在线上进行替换。
此时坑又来了,我们满怀信心的替换了一个镜像再观察日志发现居然还有删除的日志。
冷静下来一分析,原来是当前替换进行的 broker 没有问题了,但它处理的 topic 被转移到了其他 broker 中,而其他的 broker 并没有替换为我们最新的镜像。
所以导致 topic 在其他 broker 中依然被删除了。
除非我们停机,将所有的镜像都替换之后再一起重启。
但这样的成本太高了,最好是可以平滑发布。
最终我们想到一个办法,使用 arthas 去关闭了一个 broker 的一个选项,之后就不会执行出现 bug 的那段代码了。
curl -O https://arthas.aliyun.com/arthas-boot.jar && java -jar arthas-boot.jar 1 -c "vmtool -x 3 --action getInstances --className org.apache.pulsar.broker.ServiceConfiguration --express 'instances[0].setTopicLevelPoliciesEnabled(false)'"
我也将操作方法贴到了对于 issue 的评论区。
https://github.com/apache/pulsar/issues/21653#issuecomment-1857548997
如果不幸碰到了这个 bug,可以参考修复。
总结
删除的这些 topic 的同时它的订阅者也被删除了,所以我们还需要修复订阅者:
String topicName = "persistent://tenant/ns/topicName";
pulsarTopicService.createSubscription(topicName, "subName", MessageId.latest);
之所以说这个 bug 非常致命,是因为这样会导致 topic 的数据丢失,同时这些 topic 上的数据也会被删除。
后续 https://github.com/apache/pulsar/pull/21704#issuecomment-1878315926社区也补充了一些场景。
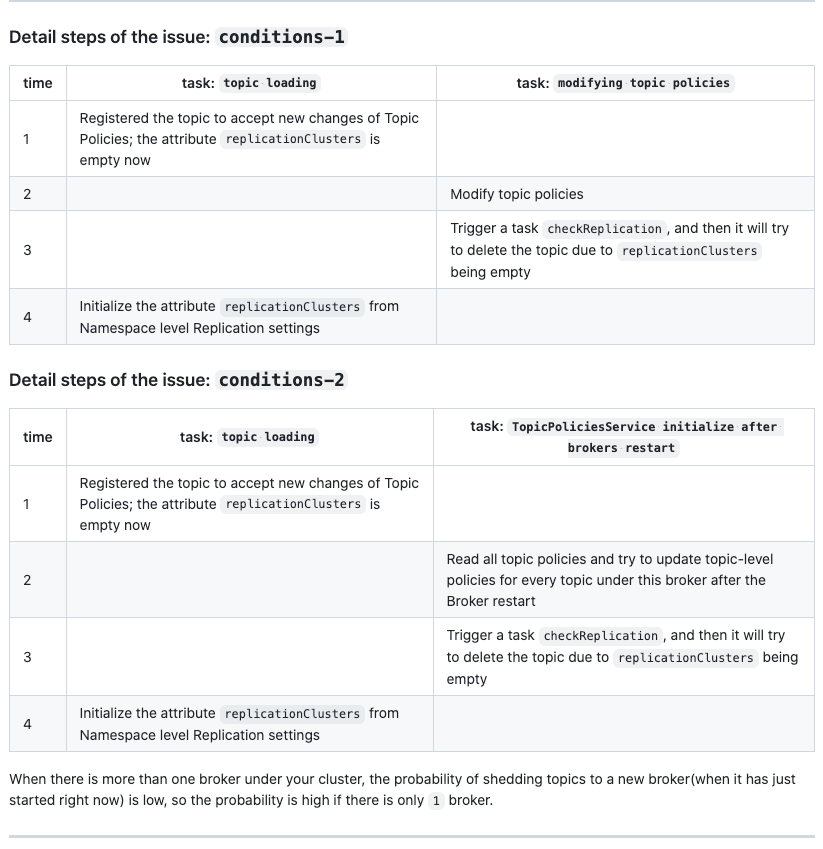
其实场景 2 更容易出现复现,毕竟更容易出现并发;也就是我们碰到的场景
说来也奇怪,结合社区的 issue 和其他大佬的反馈,这个问题只有我们碰到了,估计也是这个问题的触发条件也比较苛刻:
- 开启
systemTopic/topicLevelPolices
systemTopicEnabled: "true"
topicLevelPoliciesEnabled: "true" - 设置足够多的 topicPolicies
- 重启 broker
- 重启过程中从 zk 中获取数据出现耗时
符合以上条件的集群就需要注意了。
其实这个问题在这个 PR 就已经引入了
https://github.com/apache/pulsar/pull/11021
所以已经存在蛮久了,后续我们也将检测元数据作为升级流程之一了,确保升级后数据依然是完整的。
相关的 issue 和 PR:
https://github.com/apache/pulsar/issues/21653
https://github.com/apache/pulsar/pull/21704
请注意,你的 Pulsar 集群可能有删除数据的风险的更多相关文章
- pulsar集群搭建——生产环境
pulsar集群搭建 前置条件,需要JDK环境 192.168.1.1 192.168.1.2 192.168.1.3 写入hosts 所有机器都需要执行 $ cat >>/etc/hos ...
- hbase集群写不进去数据的问题追踪过程
hbase从集群中有8台regionserver服务器,已稳定运行了5个多月,8月15号,发现集群中4个datanode进程死了,经查原因是内存 outofMemory了(因为这几台机器上部署了spa ...
- 对 Pulsar 集群的压测与优化
前言 这段时间在做 MQ(Pulsar)相关的治理工作,其中一个部分内容关于消息队列的升级,比如: 一键创建一个测试集群. 运行一批测试用例,覆盖我们线上使用到的功能,并输出测试报告. 模拟压测,输出 ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- Kafka 集群在马蜂窝大数据平台的优化与应用扩展
马蜂窝技术原创文章,更多干货请订阅公众号:mfwtech Kafka 是当下热门的消息队列中间件,它可以实时地处理海量数据,具备高吞吐.低延时等特性及可靠的消息异步传递机制,可以很好地解决不同系统间数 ...
- 【集群实战】Rsync数据同步工具
1. Rsync介绍 1.1 什么是Rsync? Rsync是一款开源的,快速的,多功能的,可实现全量及增量的本地或远程数据同步备份的优秀工具.Rsync软件适用于unix/linux/windows ...
- 工具推荐-使用RedisInsight工具对Redis集群CURD操作及数据可视化和性能监控
关注「WeiyiGeek」公众号 设为「特别关注」每天带你玩转网络安全运维.应用开发.物联网IOT学习! 希望各位看友[关注.点赞.评论.收藏.投币],助力每一个梦想. 本章目录 目录 0x00 快速 ...
- Moebius集群:SQL Server一站式数据平台
一.Moebius集群的架构及原理 1.无共享磁盘架构 Moebius集群采用无共享磁盘架构设计,各个机器可以不连接一个共享的设备,数据可以存储在每个机器自己的存储介质中.这样每个机器就不需要硬件上的 ...
- redis cluster集群动态伸缩--删除主从节点
目标:从集群中剔除一组主从(5007,5008) 经过上一节增加5007,5008主从服务节点后,目前集群的情况是这样的: b3363a81c3c59d57143cd3323481259c044e66 ...
- cdh集群hive升级,数据不丢失
1.下载hive-1.2.1安装包 http://archive.apache.org/dist/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz 2.将安装包 ...
随机推荐
- 基于go语言gin框架的web项目骨架
该骨架每个组件之间可单独使用,组件之间松耦合,高内聚,组件的实现基于其他三方依赖包的封装. 目前该骨架实现了大多数的组件,比如事件,中间件,日志,配置,参数验证,命令行,定时任务等功能,目前可以满足大 ...
- MySQL 的 InnoDB 存储引擎简介
MySQL 是世界上最流行的开源关系型数据库管理系统之一,而其中的存储引擎则是其关键组成部分之一.InnoDB 存储引擎在 MySQL 中扮演了重要角色,提供了许多高级功能和性能优化,适用于各种应用程 ...
- 教育法学第七章单元测试MOOC
第七章单元测试 返回 本次得分为:100.00/100.00, 本次测试的提交时间为:2020-09-06, 如果你认为本次测试成绩不理想,你可以选择 再做一次 . 1 单选(5分) 父母对未成年子女 ...
- 分布式应用开发的核心技术系列之——基于TCP/IP的原始消息设计
本文由葡萄城技术团队原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言 本文的内容主要围绕以下几个部分: TCP/IP的简单介绍. 消息的介绍 ...
- 虹科案例 | 丝芙兰xDomo:全球美妆巨头商业智能新玩法
全球美妆行业的佼佼者丝芙兰,其走向成功绝非仅依靠品牌知名度和营销手段.身为数据驱动型企业,2018年以来,丝芙兰就率先在行业内采用虹科提供的Domo商业智能进行数据分析和决策,并首先享受了运营优化.效 ...
- Unity 在Preferences或Project Setting窗口创建自定义配置
官方文档链接 https://docs.unity3d.com/2020.3/Documentation/ScriptReference/SettingsProvider.html 一直不习惯使用Un ...
- 20.1 OpenSSL 字符BASE64压缩算法
OpenSSL 是一种开源的加密库,提供了一组用于加密和解密数据.验证数字证书以及实现各种安全协议的函数和工具.它可以用于创建和管理公钥和私钥.数字证书和其他安全凭据,还支持SSL/TLS.SSH.S ...
- codeforces #865 div1A
A. Ian and Array Sorting 思路:首先我们可以从前往后做一遍,把除了最后一个元素其他所有数都变成和第一个数一样的数,然后假如前n-1个数个数为偶数,这样我们分组进行操作,一定可以 ...
- php开发之文件上传的实现
前言 php是网络安全学习里必不可少的一环,简单理解php的开发环节能更好的帮助我们去学习php以及其他语言的web漏洞原理 正文 在正常的开发中,文件的功能是必不可少,比如我们在论坛的头像想更改时就 ...
- Python将一个正整数分解质因数。例如:输入90,打印出90=2*3*3*5。
def SlowSnail(n): while n != 1: # 循环保证递归 for index in range(2, n + 1): if n % index == 0: n //= inde ...