手把手教你搭建mongodb分片集群
本章用的自己的电脑win10 系统 因为工作上的环境也是win的 就没在虚拟机上玩 (ps: 其实上面环境都大同小异)
在MongoDB(版本 6.xx)中,分片是指将collection分散存储到不同的Server中,每个Server只存储collection的一部分,服务分片的所有服务器组成分片集群。分片集群(Sharded Clustered)的服务器分为三中类型:Router(mongos),Config Server 和 Shard(Replica Set 或 Standalone mongod)。使用分片集群,不需要使用强大的计算机,就能存储更多的数据,处理更大的负载。分布式数据库系统的设计目的是:水平分片,将负载分配到多台Server,减少单机查询的负载。
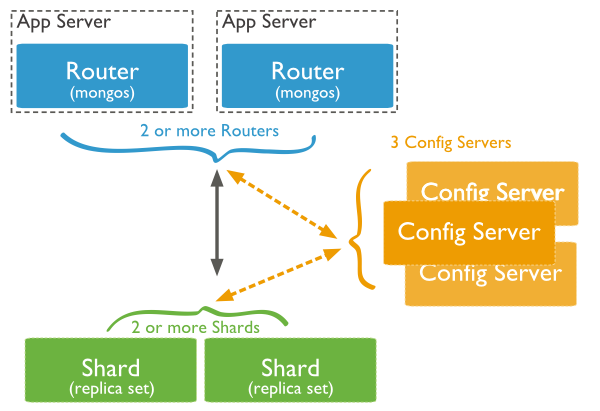
一,配置服务器
config server 存储分片的元数据,元数据包括每个分片的块(chunk)列表和每个chunk包含数据的范围。路由服务区(Router)从config server上获取分片的元数据,使用元数据将读写操作路由到正确的分片上。
The metadata includes the list of chunks on every shard and the ranges that define the chunks. The mongos instances cache this data and use it to route read and write operations to the correct shards.
config server的读写操作是非常少的,config server将分片的元数据存储在config 数据库中,只有当分片的元数据变化时,比如 chunk migration,chunk split,才会修改config server中的数据。只有在mongos 第一次启动或重启时,或者分片的元数据变化时,mongos才会读取config server中的数据。mongos在读取分片的元数据之后,会缓存在本地。
Config servers store the cluster’s metadata in the config database. The mongos instances cache this data and use it to route reads and writes to shards. MongoDB only writes data to the config servers when the metadata changes, such as
- after a chunk migration, or
- after a chunk split.
MongoDB reads data from the config server in the following cases:
- A new mongos starts for the first time, or an existing mongos restarts.
- After change in the cluster metadata, such as after a chunk migration.
实际上,config server是mongod,只不过设置 --configsvr 选项。
--configsvr 指定mongod作为一个config server
二,mongos 路由服务器
mongos 为MongoDB提供路由服务,处理从application layer发送的查询请求,定位数据所在的分片,对分片上的查询结果进行combine,以完成分布式数据查询。从Application来看,mongos担当的角色是一个MongoDB Instance,隐藏了从分片上query和combine数据的复杂过程。
mongos 的重要参数
--config <filename>, -f <filename> 指定mongos 运行的参数
--configdb 指定config server列表,格式是:config-svr:port,config-svr:port
--chunkSize 指定data block的大小,单位是MB,默认值是64
--port 指定mongos 监听的TCP的端口号,默认值是27017
--logpath 指定mongos 记录日志的路径,默认情况下,MongoDB将现存的日志文件重命名,而不是重写。By default, MongoDB will move any existing log file rather than overwrite it. To instead append to the log file, set the --logappend option.
搭建mongodb分片集群前提:
1 能够知道mongodb基本的使用
2 知道mongodb的副本集,并且能够搭建
3 知道一些基本的参数
(不清楚的上一篇中有一些说明,或者mongodb 官网上充电)
下面就开始了
1 提前准备好文件夹(我分的层级比较细,也可以不用和我一样的)
mongodb的分片集我本次就用的2个分片
分片服务器:
Shard1: (一主二从)
Shard2:(一主二从)
路由服务器:
router: 单个(这个也是可以搭多个的)
配置服务器:
service: (一主二从)


这些log文件要提前创建好

c1文件夹下创建一个文件以.conf
bind_ip=0.0.0.0
port=28017
dbpath=D:\mongoDB\zone\config\c1
logpath=D:\mongoDB\zone\config\log\config28017.log
logappend=true
replSet=config
configsvr=true
oplogSize=1024
c2文件夹下创建一个文件以.conf
bind_ip=0.0.0.0
port=28018
dbpath=D:\mongoDB\zone\config\c2
logpath=D:\mongoDB\zone\config\log\config28018.log
logappend=true
replSet=config
configsvr=true
oplogSize=1024
c3文件夹下创建一个文件以.conf
bind_ip=0.0.0.0
port=28019
dbpath=D:\mongoDB\zone\config\c3
logpath=D:\mongoDB\zone\config\log\config28019.log
logappend=true
replSet=config
configsvr=true
oplogSize=1024
Shard1:


(log文件要提前创建好)
在data0-1 data0-2 data0-3中新建 .conf 文件
data0-1
#mongodb端口
port=27018
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\zone\ser1\log\mongodb27018.log
# 数据文件的目录
dbpath=D:\mongoDB\zone\ser1\data0-1
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace1
data0-2
#mongodb端口
port=27019
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\zone\ser1\log\mongodb27019.log
# 数据文件的目录
dbpath=D:\mongoDB\zone\ser1\data0-2
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace1
data0-3
#mongodb端口
port=27020
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\zone\ser1\log\mongodb27020.log
# 数据文件的目录
dbpath=D:\mongoDB\zone\ser1\data0-3
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace1
Shard2:
这个分片也按照 Shard1 做就新了 区分好端口 和日志文件 replSet=myreplace1 这个是分片的名称 要区分开来
#mongodb端口
port=27021
#绑定ip,只有这个ip才可以访问上mongodb
bind_ip=0.0.0.0
# 日志文件的路径
logpath=D:\mongoDB\zone\ser2\log\mongodb27021.log
# 数据文件的目录
dbpath=D:\mongoDB\zone\ser2\data1-1
#日志以追加的方式存在
logappend=true
# fork=true linux以后台方式启动,在window上没有用
# 此参数较大比较好,单位是 MB,默认是磁盘可用空间的 5%
oplogSize=1024
# 复制集的名称,同一个复制集的名称必须要相同
replSet=myreplace2
其他的省略。。。
router 没什么好说的 同样需要配置文件和日志文件

bind_ip=0.0.0.0
port=27017
# mongos.log 需要提前在 los 中建好
logpath=D:\mongoDB\zone\router\los\mongos.log
logappend=true
configdb=config/127.0.0.1:28017,127.0.0.1:28018,127.0.0.1:28019
到这里准备工作就完成了,下面就是准备启动了(其实可以用批处理文件启动 我就不用了)
我这边是按照自己目录来的
Shard1
mongod.exe --shardsvr --config "D:\mongoDB\zone\ser1\data0-1\27018.conf"
mongod.exe --shardsvr --config "D:\mongoDB\zone\ser1\data0-2\27019.conf"
mongod.exe --shardsvr --config "D:\mongoDB\zone\ser1\data0-3\27020.conf"
Shard2
mongod.exe --shardsvr --config "D:\mongoDB\zone\ser2\data1-1\27021.conf"
mongod.exe --shardsvr --config "D:\mongoDB\zone\ser2\data1-2\27022.conf"
mongod.exe --shardsvr --config "D:\mongoDB\zone\ser2\data1-3\27023.conf"
config:
mongod.exe --config "D:\mongoDB\zone\config\c1\28017.conf"
mongod.exe --config "D:\mongoDB\zone\config\c2\28018.conf"
mongod.exe --config "D:\mongoDB\zone\config\c3\28019.conf"
mongosh.exe --port 27018 连接到Shard1分片的任意服务器 初始化
use admin
rs.initiate({
_id : "myreplace1",
members : [
{_id : 0,host : "192.168.12.1:27018","priority":10},
{_id : 1,host : "192.168.12.1:27019"},
{_id : 2,host : "192.168.12.1:27020"}]
});
mongosh.exe --port 27021 连接到Shard2分片的任意服务器 初始化
rs.initiate({
_id : "myreplace2",
members : [
{_id : 0,host : "192.168.12.1:27021","priority":10},
{_id : 1,host : "192.168.12.1:27022"},
{_id : 2,host : "192.168.12.1:27023"}]
});
mongosh.exe --port 28017 连接到config分片的任意服务器 初始化
rs.initiate({
_id : "config",
members : [
{_id : 0,host : "192.168.12.1:28017","priority":10},
{_id : 1,host : "192.168.12.1:28018"},
{_id : 2,host : "192.168.12.1:28019"}]
});
启动router 服务
mongos.exe --config "D:\mongoDB\zone\router\27017.conf"
连接到 mongos
mongosh.exe --port 27017
use admin
-- 创建需要分片的库
sh.enableSharding("test9527")
use test9527
db.createCollection("user");
-- 创建mongodb的索引 以哈希散列
db.user.createIndex({_id:"hashed"})
use admin
sh.shardCollection("test9527.user",{_id:"hashed"})
use test9527
-- 向 user文档中插入多条数据
db.user.insert({name:"xxs",age:21});

插入了15条数据
切换到Shard1分片

切换到Shard2分片

加起来刚刚好15条 ,打完收工!!!
手把手教你搭建mongodb分片集群的更多相关文章
- 搭建MongoDB分片集群
在部门服务器搭建MongoDB分片集群,记录整个操作过程,朋友们也可以参考. 计划如下: 用5台机器搭建,IP分别为:192.168.58.5.192.168.58.6.192.168.58.8.19 ...
- Windows 搭建MongoDB分片集群(二)
在本篇博客中我们主要讲描述分片集群的搭建过程.配置分片集群主要有两个步骤,第一启动所有需要的mongod和mongos进程.第二步就是启动一个mongos与集群通信.下面我们一步步来描述集群的搭建过程 ...
- Windows 搭建MongoDB分片集群(一)
一.角色说明 要构建一个MongoDB分片集群,需要三个角色: shard server 即存储实际数据得分片,每个shard 可以是一个Mongod实例,也可以是一组mongod实例构成得Repl ...
- 手把手教你搭建一个 Elasticsearch 集群
为何要搭建 Elasticsearch 集群 凡事都要讲究个为什么.在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢? 高可用性 Elasticsearch 作为一个搜索引擎, ...
- 手把手教你搭建一个Elasticsearch集群
一.为何要搭建 Elasticsearch 集群 凡事都要讲究个为什么.在搭建集群之前,我们首先先问一句,为什么我们需要搭建集群?它有什么优势呢? (1)高可用性 Elasticsearch 作为一个 ...
- MongoDB 分片集群实战
背景 在如今的互联网环境下,海量数据已随处可见并且还在不断增长,对于如何存储处理海量数据,比较常见的方法有两种: 垂直扩展:通过增加单台服务器的配置,例如使用更强悍的 CPU.更大的内存.更大容量的磁 ...
- MongoDB分片集群原理、搭建及测试详解
随着技术的发展,目前数据库系统对于海量数据的存储和高效访问海量数据要求越来越高,MongoDB分片机制就是为了解决海量数据的存储和高效海量数据访问而生. MongoDB分片集群由mongos路由进程( ...
- 网易云MongoDB分片集群(Sharding)服务已上线
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MongoDB sharding cluster(分片集群)是MongoDB提供的数据在线水平扩展方案,包括 ...
- 分布式文档存储数据库之MongoDB分片集群
前文我们聊到了mongodb的副本集以及配置副本集,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/13953598.html:今天我们来聊下mongodb的分片 ...
- mongodb分片集群
第一章 1.mongodb 分片集群解释和目的 一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合.复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础. 第二章 1. ...
随机推荐
- loguru 简单使用
使用Python自带的 logging 来记录日志会比较麻烦,查了下 大家都在用 loguru,看了下文档,发现是挺好用的,记录下笔记 安装 pip install loguru 简单使用 f ...
- k8s 深入篇———— docker 是什么[一]
前言 简单的整理一下一些基本概念. 正文 简单运行一个容器: 创建一个容器: docker run -it busybox /bin/bash 然后看下进程: ps -ef 做了一个障眼法,使用的是p ...
- 给picgo上传的图片加个水印
之前给大家介绍了picgo和免费的图床神器.我们本可以开开心心的进行markdown写作了. 但是总是会有那么一些爬虫网站过来爬你的文章,还把你的文章标明是他们的原著.咋办呢?这里有一个好的办法就是把 ...
- 第五課-Channel Study TCP Listener & Web Service Listener
示例描述: 我们将研究如何获取相当常见的HL7 v2消息并将其映射到自定义Web Service接口服务.在许多实际情况下,当我们要连接到HIE,EMPI,数据仓库或数据存储库时,必须这样做.此用例说 ...
- 力扣520(java)-检测大写字母(简单)
题目: 我们定义,在以下情况时,单词的大写用法是正确的: 1.全部字母都是大写,比如 "USA" .2.单词中所有字母都不是大写,比如 "leetcode" . ...
- 比Bloom Filter节省25%空间!Ribbon Filter在Lindorm中的应用
简介: 本文研究了一种新的过滤器Ribbon Filter,并将其集成到Lindorm中 作者:箫苏 朝戈 正研 1 前言 Lindorm是一个低成本高吞吐的多模数据库,目前,Lindorm是阿里内部 ...
- 持续定义Saas模式云数据仓库+BI
云数据仓库概述 今天和大家一起探讨一下我们Saas模式下云数据仓库加上商业智能BI能有什么新的东西出来.我们先来看一下云数据仓库的一些概述.预测到2025年, 全球数据增长至175ZB, 中国数据量增 ...
- 如何迁移 Flink 任务到实时计算
简介: 本文由阿里巴巴技术专家景丽宁(砚田)分享,主要介绍如何迁移Flink任务到实时计算 Flink 中来. 通常用户在线下主要使用 Flink run,这会造成一些问题,比如:同一个配置因版本而变 ...
- 喜马拉雅 Apache RocketMQ 消息治理实践
简介:本文通过喜马拉雅的RocketMQ治理实践分享,让大家了解使用消息中间件过程中可能遇到的问题,避免实战中踩坑. 作者:曹融,来自喜马拉雅,从事微服务和消息相关中间件开发. 本文通过喜马拉雅 ...
- MySQL 深潜 - 一文详解 MySQL Data Dictionary
简介: 在 MySQL 8.0 之前,Server 层和存储引擎(比如 InnoDB)会各自保留一份元数据(schema name, table definition 等),不仅在信息存储上有着重复 ...