rasa train nlu详解:1.2-_train_graph()函数
本文使用《使用ResponseSelector实现校园招聘FAQ机器人》中的例子,主要详解介绍_train_graph()函数中变量的具体值。
一.rasa/model_training.py/_train_graph()函数
_train_graph()函数实现,如下所示:
def _train_graph(
file_importer: TrainingDataImporter,
training_type: TrainingType,
output_path: Text,
fixed_model_name: Text,
model_to_finetune: Optional[Union[Text, Path]] = None,
force_full_training: bool = False,
dry_run: bool = False,
**kwargs: Any,
) -> TrainingResult:
if model_to_finetune: # 如果有模型微调
model_to_finetune = rasa.model.get_model_for_finetuning(model_to_finetune) # 获取模型微调
if not model_to_finetune: # 如果没有模型微调
rasa.shared.utils.cli.print_error_and_exit( # 打印错误并退出
f"No model for finetuning found. Please make sure to either " # 没有找到微调模型。请确保
f"specify a path to a previous model or to have a finetunable " # 要么指定一个以前模型的路径,要么有一个可微调的
f"model within the directory '{output_path}'." # 在目录'{output_path}'中的模型。
)
rasa.shared.utils.common.mark_as_experimental_feature( # 标记为实验性功能
"Incremental Training feature" # 增量训练功能
)
is_finetuning = model_to_finetune is not None # 如果有模型微调
config = file_importer.get_config() # 获取配置
recipe = Recipe.recipe_for_name(config.get("recipe")) # 获取配方
config, _missing_keys, _configured_keys = recipe.auto_configure( # 自动配置
file_importer.get_config_file_for_auto_config(), # 获取自动配置的配置文件
config, # 配置
training_type, # 训练类型
)
model_configuration = recipe.graph_config_for_recipe( # 配方的graph配置
config, # 配置
kwargs, # 关键字参数
training_type=training_type, # 训练类型
is_finetuning=is_finetuning, # 是否微调
)
rasa.engine.validation.validate(model_configuration) # 验证
tempdir_name = rasa.utils.common.get_temp_dir_name() # 获取临时目录名称
# Use `TempDirectoryPath` instead of `tempfile.TemporaryDirectory` as this leads to errors on Windows when the context manager tries to delete an already deleted temporary directory (e.g. https://bugs.python.org/issue29982)
# 翻译:使用TempDirectoryPath而不是tempfile.TemporaryDirectory,因为当上下文管理器尝试删除已删除的临时目录时,这会导致Windows上的错误(例如https://bugs.python.org/issue29982)
with rasa.utils.common.TempDirectoryPath(tempdir_name) as temp_model_dir: # 临时模型目录
model_storage = _create_model_storage( # 创建模型存储
is_finetuning, model_to_finetune, Path(temp_model_dir) # 是否微调,模型微调,临时模型目录
)
cache = LocalTrainingCache() # 本地训练缓存
trainer = GraphTrainer(model_storage, cache, DaskGraphRunner) # Graph训练器
if dry_run: # dry运行
fingerprint_status = trainer.fingerprint( # fingerprint状态
model_configuration.train_schema, file_importer # 模型配置的训练模式,文件导入器
)
return _dry_run_result(fingerprint_status, force_full_training) # 返回dry运行结果
model_name = _determine_model_name(fixed_model_name, training_type) # 确定模型名称
full_model_path = Path(output_path, model_name) # 完整的模型路径
with telemetry.track_model_training( # 跟踪模型训练
file_importer, model_type=training_type.model_type # 文件导入器,模型类型
):
trainer.train( # 训练
model_configuration, # 模型配置
file_importer, # 文件导入器
full_model_path, # 完整的模型路径
force_retraining=force_full_training, # 强制重新训练
is_finetuning=is_finetuning, # 是否微调
)
rasa.shared.utils.cli.print_success( # 打印成功
f"Your Rasa model is trained and saved at '{full_model_path}'." # Rasa模型已经训练并保存在'{full_model_path}'。
)
return TrainingResult(str(full_model_path), 0) # 训练结果
1.传递来的形参数据

2._train_graph()函数组成
该函数主要由3个方法组成,如下所示:
- model_configuration = recipe.graph_config_for_recipe(*)
- trainer = GraphTrainer(model_storage, cache, DaskGraphRunner)
- trainer.train(model_configuration, file_importer, full_model_path, force_retraining, is_finetuning)
二._train_graph()函数中的方法
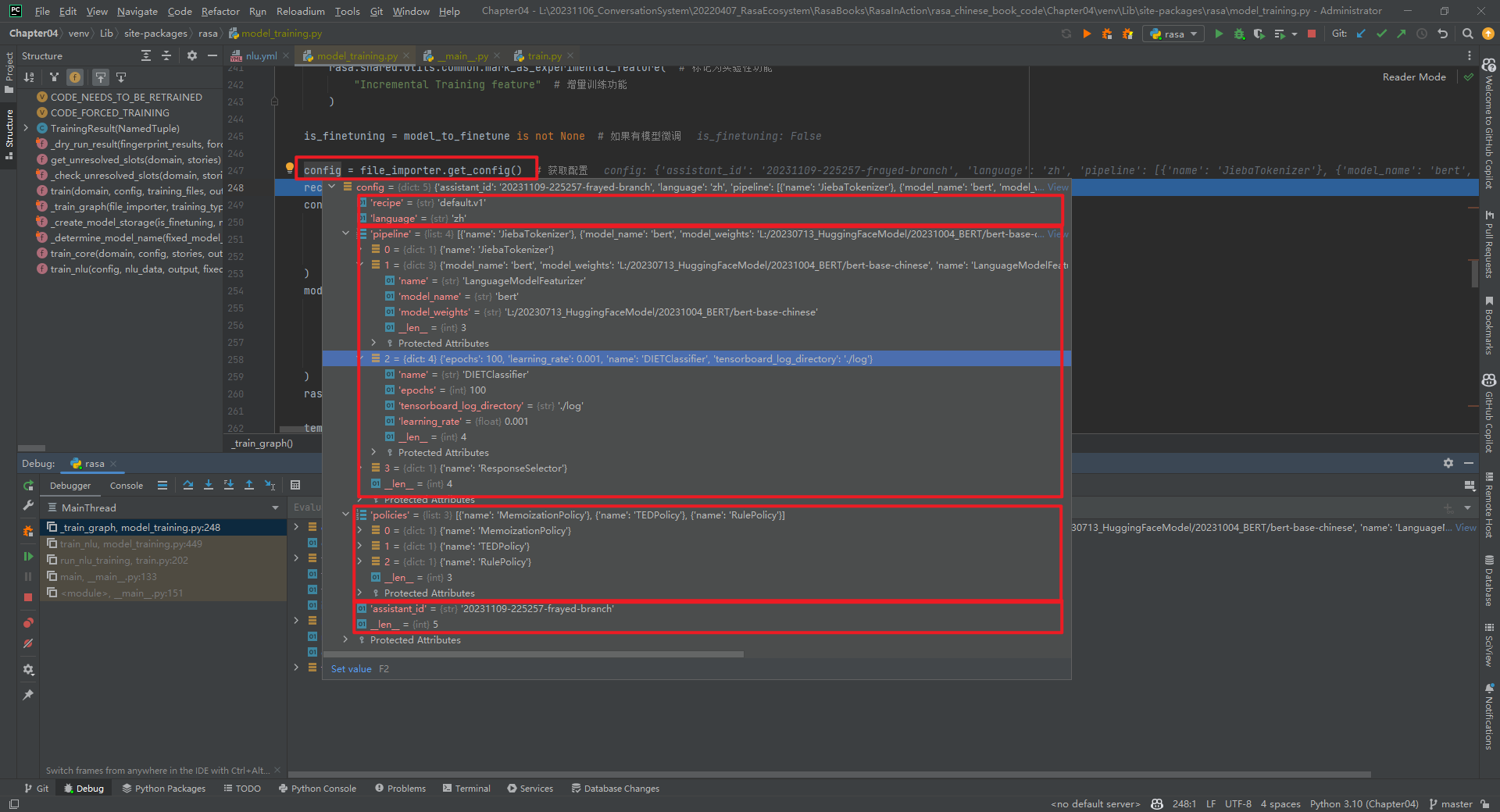
1.file_importer.get_config()
将config.yml文件转化为dict类型,如下所示:
2.Recipe.recipe_for_name(config.get("recipe"))

(1)ENTITY_EXTRACTOR = ComponentType.ENTITY_EXTRACTOR
实体抽取器。
(2)INTENT_CLASSIFIER = ComponentType.INTENT_CLASSIFIER
意图分类器。
(3)MESSAGE_FEATURIZER = ComponentType.MESSAGE_FEATURIZER
消息特征化。
(4)MESSAGE_TOKENIZER = ComponentType.MESSAGE_TOKENIZER
消息Tokenizer。
(5)MODEL_LOADER = ComponentType.MODEL_LOADER
模型加载器。
(6)POLICY_WITHOUT_END_TO_END_SUPPORT = ComponentType.POLICY_WITHOUT_END_TO_END_SUPPORT
非端到端策略支持。
(7)POLICY_WITH_END_TO_END_SUPPORT = ComponentType.POLICY_WITH_END_TO_END_SUPPORT
端到端策略支持。
3.model_configuration = recipe.graph_config_for_recipe(*)
model_configuration.train_schema和model_configuration.predict_schema的数据类型都是GraphSchema类对象,分别表示在训练和预测时所需要的SchemaNode,以及SchemaNode在GraphSchema中的依赖关系。
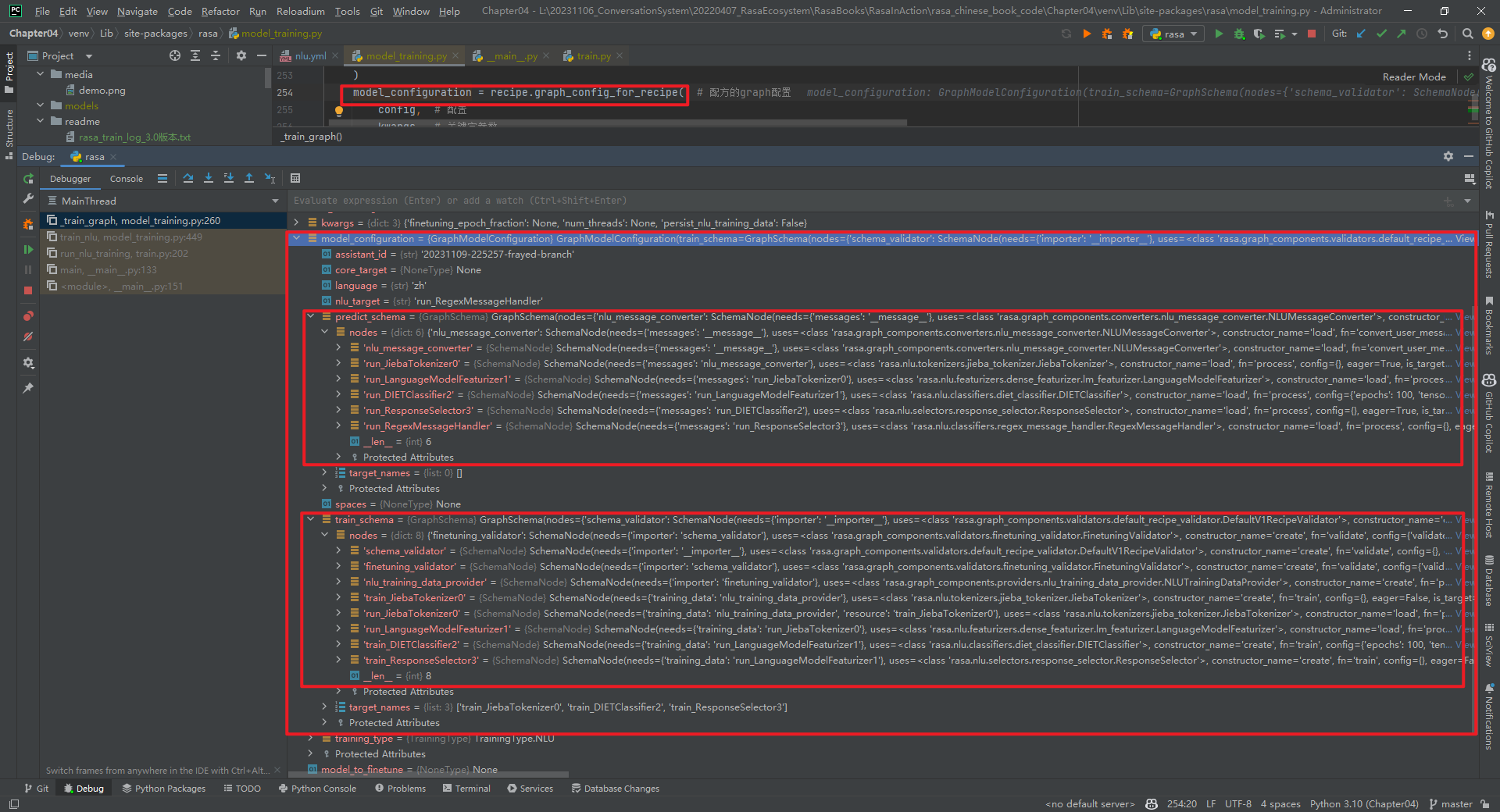
(1)model_configuration.train_schema
- schema_validator:rasa.graph_components.validators.default_recipe_validator.DefaultV1RecipeValidator类中的validate方法
- finetuning_validator:rasa.graph_components.validators.finetuning_validator.FinetuningValidator类中的validate方法
- nlu_training_data_provider:rasa.graph_components.providers.nlu_training_data_provider.NLUTrainingDataProvider类中的provide方法
- train_JiebaTokenizer0:rasa.nlu.tokenizers.jieba_tokenizer.JiebaTokenizer类中的train方法
- run_JiebaTokenizer0:rasa.nlu.tokenizers.jieba_tokenizer.JiebaTokenizer类中的process_training_data方法
- run_LanguageModelFeaturizer1:rasa.nlu.featurizers.dense_featurizer.lm_featurizer.LanguageModelFeaturizer类中的process_training_data方法
- train_DIETClassifier2:rasa.nlu.classifiers.diet_classifier.DIETClassifier类中的train方法
- train_ResponseSelector3:rasa.nlu.selectors.response_selector.ResponseSelector类中的train方法
说明:ResponseSelector类继承自DIETClassifier类。
(2)model_configuration.predict_schema
- nlu_message_converter:rasa.graph_components.converters.nlu_message_converter.NLUMessageConverter类中的convert_user_message方法
- run_JiebaTokenizer0:rasa.nlu.tokenizers.jieba_tokenizer.JiebaTokenizer类中的process方法
- run_LanguageModelFeaturizer1:rasa.nlu.featurizers.dense_featurizer.lm_featurizer.LanguageModelFeaturizer类中的process方法
- run_DIETClassifier2:rasa.nlu.classifiers.diet_classifier.DIETClassifier类中的process方法
- run_ResponseSelector3:rasa.nlu.selectors.response_selector.ResponseSelector类中的process方法
- run_RegexMessageHandler:rasa.nlu.classifiers.regex_message_handler.RegexMessageHandler类中的process方法
4.tempdir_name
'C:\Users\ADMINI~1\AppData\Local\Temp\tmpg0v179ea'
5.trainer = GraphTrainer(*)和trainer.train(*)
这里执行的代码是rasa/engine/training/graph_trainer.py中GraphTrainer类的train()方法,实现功能为训练和打包模型并返回预测graph运行程序。
6.Rasa中GraphComponent的子类

参考文献:
[1]https://github.com/RasaHQ/rasa
[2]rasa 3.2.10 NLU模块的训练:https://zhuanlan.zhihu.com/p/574935615
[3]rasa.engine.graph:https://rasa.com/docs/rasa/next/reference/rasa/engine/graph/
rasa train nlu详解:1.2-_train_graph()函数的更多相关文章
- SQL 中详解round(),floor(),ceiling()函数的用法和区别?
SQL 中详解round(),floor(),ceiling()函数的用法和区别? 原创 2013年06月09日 14:00:21 摘自:http://blog.csdn.net/yueliang ...
- 第7.25节 Python案例详解:使用property函数定义与实例变量同名的属性会怎样?
第7.25节 Python案例详解:使用property函数定义与实例变量同名的属性会怎样? 一. 案例说明 我们上节提到了,使用property函数定义的属性不要与类内已经定义的普通实例变量重 ...
- 第7.24节 Python案例详解:使用property函数定义属性简化属性访问代码实现
第7.24节 Python案例详解:使用property函数定义属性简化属性访问代码实现 一. 案例说明 本节将通过一个案例介绍怎么使用property定义快捷的属性访问.案例中使用Rectan ...
- 详解wait和waitpid函数
#include <sys/types.h> /* 提供类型pid_t的定义 */ #include <sys/wait.h> pid_t wait(int *status) ...
- Linux 信号详解一(signal函数)
信号列表 SIGABRT 进程停止运行 SIGALRM 警告钟 SIGFPE 算述运算例外 SIGHUP 系统挂断 SIGILL 非法指令 SIGINT 终端中断 SIGKILL 停止进程(此信号不能 ...
- (译)详解javascript立即执行函数表达式(IIFE)
写在前面 这是一篇译文,原文:Immediately-Invoked Function Expression (IIFE) 原文是一篇很经典的讲解IIFE的文章,很适合收藏.本文虽然是译文,但是直译的 ...
- 《Windows驱动开发技术详解》之派遣函数
驱动程序的主要功能是负责处理I/O请求,其中大部分I/O请求是在派遣函数中处理的.用户模式下所有对驱动程序的I/O请求,全部由操作系统转化为一个叫做IRP的数据结构,不同的IRP数据会被“派遣”到不同 ...
- [二] java8 函数式接口详解 函数接口详解 lambda表达式 匿名函数 方法引用使用含义 函数式接口实例 如何定义函数式接口
函数式接口详细定义 package java.lang; import java.lang.annotation.*; /** * An informative annotation type use ...
- 详解MySQL中concat函数的用法(连接字符串)
MySQL中concat函数 使用方法: CONCAT(str1,str2,…) 返回结果为连接参数产生的字符串.如有任何一个参数为NULL ,则返回值为 NULL. 注意: 如果所有参数均为非二进制 ...
- 详解javascript立即执行函数表达式(IIFE)
立即执行函数,就是在定义函数的时候直接执行,这里不是申明函数而是一个函数表达式 1.问题 在javascript中,每一个函数在被调用的时候都会创建一个执行上下文,在函数内部定义的变量和函数只能在该函 ...
随机推荐
- 如何使用Arduino创建摩尔斯电码生成器
摩尔斯电码工作原理 摩尔斯电码发明于19世纪,使用非常简单的长短脉冲序列(通常为电和划)来远距离发送消息.通过将字母表中的字母编码为电和划的组合,信息可以只用一个单一的电子或声音信号来表达. 为了说明 ...
- 11g编译bbed
报错如下: make -f ins_rdbms.mk $ORACLE_HOME/rdbms/lib/bbed Linking BBED utility (bbed) rm -f /u01/app/or ...
- oracle下载安装教程(带安装包)
废话不多说上连接: 链接:https://pan.baidu.com/s/1ukUjxbTpodxwxoGQUKl8KA?pwd=y6ju 提取码:y6ju oracle下载速度太慢了我存在了百度网盘 ...
- Java核心知识体系5:反射机制详解
Java核心知识体系1:泛型机制详解 Java核心知识体系2:注解机制详解 Java核心知识体系3:异常机制详解 Java核心知识体系4:AOP原理和切面应用 1 介绍 无论是那种语言体系,反射都是必 ...
- Spring扩展接口(4):InstantiationAwareBeanPostProcessor
在此系列文章中,我总结了Spring几乎所有的扩展接口,以及各个扩展点的使用场景.并整理出一个bean在spring中从被加载到最终初始化的所有可扩展点的顺序调用图.这样,我们也可以看到bean是如何 ...
- 二。docker安装mysql 并配置
1.docker安装mysql 1.1使用docker拉取mysql的镜像 docker pull mysql:5.7 1.2通过镜像启动 docker run -p 3306:3306 --name ...
- JVM Stack and Frame
Overview Sharing a single thread within the district: PC Register/JVM Stack/Native Method Stack.All ...
- 2022/07/16暑期集训考试 day1
T1 取餐号 看到数据范围 直接锁定埃氏筛和线性筛 我打的是一个优化一点的埃氏筛 #include<bits/stdc++.h> using namespace std; #define ...
- Rasa NLU中的组件
Rasa NLU部分主要是解决NER(序列建模)和意图识别(分类建模)这2个任务.Rasa NLP是一个基于DAG的通用框架,图中的顶点即组件.组件特征包括有顺序关系.可相互替换.可互斥和可同时使 ...
- 初窥门径,从大模型到内容生成看AI新次元
视频云AI进化新纪元. 最近Gartner发布2024年十大战略技术趋势,AI显然成为其背后共同的主题.全民化的生成式人工智能.AI增强开发.智能应用......我们正在进入一个AI新纪元. 从Cha ...