WSDM Cup 2020大赛金牌参赛方案全解析
近日,在美国休斯敦闭幕的第13届网络搜索与数据挖掘国际会议(WSDM 2020)上,华为云语音语义创新Lab带领来自华南理工大学、华中科技大学、江南大学、武汉大学的四位学生组成的联合团队“Xiong团队”,摘得WSDM Cup 2020大赛“论文引用意图识别任务”金牌(Gold Medal)。
WSDM被誉为全球信息检索领域最有影响力也最权威的会议之一,会议关注社交网络上的搜索与数据挖掘,尤其关注搜索与数据挖掘模型、算法设计与分析、产业应用和提升准确性与效果的实验分析。今年已经是WSDM的第十三届会议。
本文将详细介绍本次获奖的解决方案。
1、背景
几个世纪以来,社会技术进步的关键在于科学家之间坦诚的学术交流。新发现和新理论在已发表的文章中公开分发和讨论,有影响力的贡献则通常被研究界以引文的形式认可。然而,随着科研经费申请竞争日趋激烈,越来越多的人把学术研究当成一种资源争夺的手段,而不是单纯为了推动知识进步。
部分期刊作者“被迫”在特定期刊中引用相关文章,以提高期刊的影响因子,而论文审稿人也只能增加期刊的引用次数或h指数。这些行为是对科学家和技术人员所要求的最高诚信的冒犯,如果放任这种情况发展,可能会破坏公众的信任并阻碍科学技术的未来发展。因此,本次WSDM Cup 2020赛题之一将重点放在识别作者的引文意图:要求参赛者开发一种系统,该系统可以识别学术文章中给定段落的引文意图并检索相关内容。
华为云语音语义创新Lab在自然语言处理领域有着全栈的技术积累,包括自然语言处理基础中的分词、句法解析,自然语言理解中的情感分析、文本分类、语义匹配,自然语言生成,对话机器人,知识图谱等领域。其中和本次比赛最相关的技术是语义匹配技术。Xiong团队通过对赛题任务进行分析,针对该问题制定了一种“整体召回+重排+集成”的方案,该方案以轻量化的文本相似度计算方法(如BM25等)对文章进行召回,然后基于深度学习的预训练语言模型BERT等进行重排,最后通过模型融合进行集成。
2、赛题介绍
本次比赛将提供一个论文库(约含80万篇论文),同时提供对论文的描述段落,来自论文中对同类研究的介绍。参赛选手需要为描述段落匹配三篇最相关的论文。
例子:
描述:
An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced.
相关论文:
[1] BERT: Pre-training of deep bidirectional transformers for language understanding.[2] Relational inductive biases, deep learning, and graph networks.
评测方案:

3、数据分析
本次赛题共给出80多万条候选论文,6万多条训练样本和3万多条本测试样本,候选论文包含paper_id,title,abstract,journal,keyword,year这六个字段的信息,训练样本包含description_id,paper_id,description_text这三个字段的信息,而测试数据则给出description_id和description_text两个字段,需要匹配出相应的paper_id。
我们对数据中候选论文的title,abstract以及描述文本的长度做了一些统计分析,如图1所示,从图中我们可以看到文本长度都比较长,并且针对我们后续的单模型,我们将模型最大长度从300增加到512后,性能提升了大约1%。
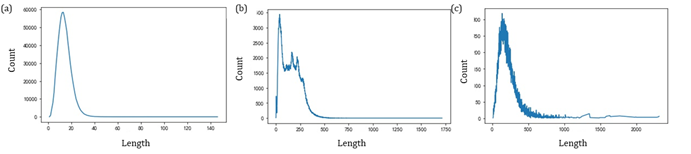
图1 候选论文的Title(a),Abstract(b)以及描述文本(c)的长度分布
4、整体方案
我们方案的整体架构如图2所示,整体方案分为四个部分:数据处理,候选论文的召回,候选论文的重排以及模型融合。
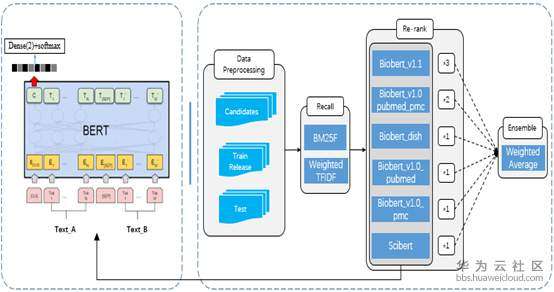
图2 整体方案架构(部分图引自[5])
4.1 数据处理
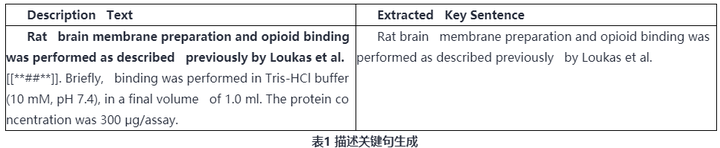
通过观察数据我们发现,在标题给出的描述语句中,有许多相同的描述文本,但是参考标记的位置却不同。也就是说,在同一篇文章中,不同的句子引用了不同的论文。为此,我们抽取句子中引用标记位置处的语句作为新的描述语句生成候选集。
如表1所示,我们选取描述中[[**##**]]之前的句子作为描述关键句。
4.2候选论文召回
如图3所示,我们运用BM25和TF-IDF来进行论文的召回,选取BM25召回的前80篇论文和TF-IDF召回的前20篇论文构成并集组成最终的召回论文。

图3 召回示意图
4.3候选论文重排
在本方案中,我们用BERT模型作为基础模型,BERT是一种能在基于查询的文章重排任务中取得良好性能的语义表示模型。通过观察数据发现,论文主要数据生物医学领域,于是我们聚焦到采用生物医学领域数据训练预训练模型。然后将查询与描述字段以句子对的形式输入进BERT模型进行训练。我们的实验表明,在该任务上,单个的BioBERT的性能要比BERT性能高5个百分点。如图4为BioBERT的结构图。
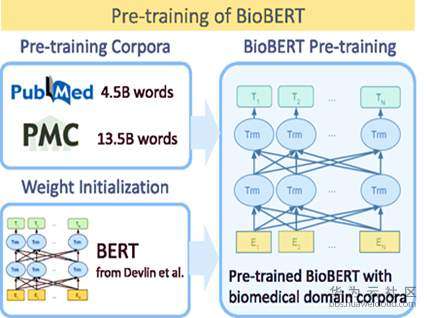
图4 BioBERT结构图 (图引自[6])
4.4 模型融合
在模型融合的过程中,我们运用了6种共9个经过科学和生物医药语料库训练的预训练模型分别为:BioBERT_v1.1* 3, BioBERT_v1.0_PubMed_PMC * 2, BioBERT_v1.0_PubMed* 1,BioBERT_v1.0_PMC * 1, BioBERT_dish*1,SciBERT* 1。他们的单模型在该任务中的性能如表2所示。
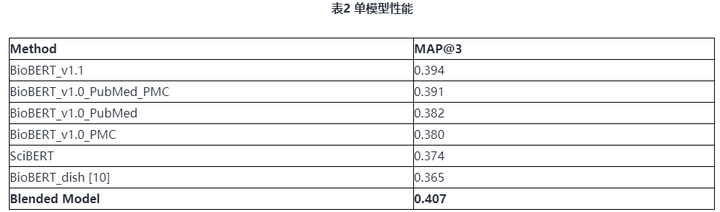
然后我们对单模型输出的概率结果进行blending操作如图5所示,得到最后的模型结果,其比最好的单模型结果提升了1个百分点左右。
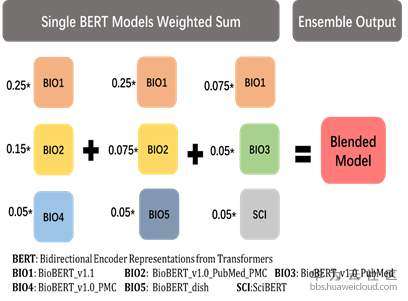
图5 模型融合
5、总结与展望
本文主要对比赛中所使用的关键技术进行了介绍,如数据处理,候选论文的召回与重排,模型融合等。在比赛中使用专有领域训练后的预训练模型较通用领域预训练模型效果有较大的提升。由于比赛时间的限制,许多方法还没来得及试验,比如在比赛中由于正负样本不平衡,导致模型训练结果不理想,可以合理的使用上采样或下采样来使样本达到相对平衡,提升模型训练效果。
参考文献
[1] Yang W, Zhang H, Lin J. Simple applications of BERT for ad hoc document
retrieval[J]. arXiv preprint arXiv:1903.10972, 2019.
[2] Gupta V, Chinnakotla M, Shrivastava M. Retrieve and re-rank: A simple and
effective IR approach to simple question answering over knowledge
graphs[C]//Proceedings of the First Workshop on Fact Extraction and
VERification (FEVER). 2018: 22-27.
[3] Peters M E, Neumann M, Iyyer M, et al. Deep contextualized word
representations[J]. arXiv preprint arXiv:1802.05365, 2018.
[4] Radford A, Wu J, Child R, et al. Language models are unsupervised multitask
learners[J]. OpenAI Blog, 2019, 1(8): 9.
[5] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. (2018)
BERT: Pre-training of Deep Bidirectional Transformers for Language
Understanding. arXiv preprint arXiv:1810.04805,.
[6] Jinhyuk Lee, Wonjin Yoon, Sungdong Kim, Donghyeon Kim, Sunkyu Kim,
Chan Ho So, Jaewoo Kang,(2019) BioBERT: a pre-trained biomedical language
representation model for biomedical text mining, Bioinformatics,
[7] Iz Beltagy, Kyle Lo, Arman Cohan. (2019) SciBERT: A Pretrained Language
Model for Scientific Text, arXiv preprint arXiv:1903.10676SciBERT: A
Pretrained Language Model for Scientific Text, arXiv preprint arXiv:1903.10676,
2019.
[8] Nogueira R, Cho K.(2019) Passage Re-ranking with BERT. arXiv preprint
arXiv:1901.04085.
[9] Alsentzer E, Murphy J R, Boag W, et al. Publicly available clinical BERT
embeddings[J]. arXiv preprint arXiv:1904.03323, 2019.
WSDM Cup 2020大赛金牌参赛方案全解析的更多相关文章
- 【独家】阿里天池IJCAI17大赛第四名方案全解析(附代码)
[独家]阿里天池IJCAI17大赛第四名方案全解析(附代码) https://mp.weixin.qq.com/s?__biz=MzAxMzA2MDYxMw==&mid=2651560625& ...
- Spring-Boot-操作-Redis,三种方案全解析!
在 Redis 出现之前,我们的缓存框架各种各样,有了 Redis ,缓存方案基本上都统一了,关于 Redis,松哥之前有一个系列教程,尚不了解 Redis 的小伙伴可以参考这个教程: Redis 教 ...
- 美团:WSDM Cup 2019自然语言推理任务获奖解题思路
WSDM(Web Search and Data Mining,读音为Wisdom)是业界公认的高质量学术会议,注重前沿技术在工业界的落地应用,与SIGIR一起被称为信息检索领域的Top2. 刚刚在墨 ...
- 【转载】Fragment 全解析(1):那些年踩过的坑
http://www.jianshu.com/p/d9143a92ad94 Fragment系列文章:1.Fragment全解析系列(一):那些年踩过的坑2.Fragment全解析系列(二):正确的使 ...
- Android图片加载框架最全解析(六),探究Glide的自定义模块功能
不知不觉中,我们的Glide系列教程已经到了第六篇了,距离第一篇Glide的基本用法发布已经过去了半年的时间.在这半年中,我们通过用法讲解和源码分析配合学习的方式,将Glide的方方面面都研究了个遍, ...
- Android图片加载框架最全解析(三),深入探究Glide的缓存机制
在本系列的上一篇文章中,我带着大家一起阅读了一遍Glide的源码,初步了解了这个强大的图片加载框架的基本执行流程. 不过,上一篇文章只能说是比较粗略地阅读了Glide整个执行流程方面的源码,搞明白了G ...
- Gson全解析(上)-Gson基础
前言 最近在研究Retrofit中使用的Gson的时候,发现对Gson的一些深层次的概念和使用比较模糊,所以这里做一个知识点的归纳整理. Gson(又称Google Gson)是Google公司发布的 ...
- select节点clone全解析
select节点clone全解析 2009-12-18 在开发ns-log项目中,统计分类有复制的功能.由于之前的统计分类中的数据是通过JS赋值进去的,之后用户可能又进行了修改,发现进行节点克隆时,出 ...
- [转]Visual Studio 2017各版本安装包离线下载、安装全解析
Visual Studio 2017各版本安装包离线下载.安装全解析 2017-3-10 11:15:03来源:IT之家作者:寂靜·櫻花雨责编:晨风评论:165 感谢IT之家网友 寂靜·櫻花雨的投 ...
- Google Guava Cache 全解析
Google guava工具类的介绍和使用https://blog.csdn.net/wwwdc1012/article/details/82228458 LoadingCache缓存使用(Loadi ...
随机推荐
- [NSSRound#1 Basic]basic_check
打开网站,发现啥也没有: 就用dirsearch扫了一遍.发现还是没有有用信息: 只有再另找方法: 再用nikto扫一次: 发现一个put方法,就用put上传一个一句话木马:可以用插件restlien ...
- osx12.6设置全屏
首先安装VMWARE TOOLS就是unlocker208下的tool的darwin.iso 然后进入终端命令,这里要说一下,好多资料说按COMMAND键,反正我是没有进去,直接在vmware菜单里选 ...
- 从零用VitePress搭建博客教程(2) –VitePress默认首页和头部导航、左侧导航配置
2. 从零用VitePress搭建博客教程(2) –VitePress默认首页和头部导航.左侧导航配置 接上一节: 从零用VitePress搭建博客教程(1) – VitePress的安装和运行 四. ...
- js性能优化解决办法
1. 减少http请求次数:CSS Sprites, JS.CSS 源码压缩.图片大小控制合适:网页 Gzip,CDN 托管,data 缓存 ,图片服务器 2. 前端模板 JS + 数据,减少由于HT ...
- Godot - 通过C#实现类似Unity协程
参考博客Unity 协程原理探究与实现 Godot 3.1.2版本尚不支持C#版本的协程,仿照Unity的形式进行一个协程的尝试 但因为Godot的轮询函数为逐帧的_Process(float del ...
- c# 光学三原色混合,颜色叠加-dong
东的备注: 光的三原色:红.绿.蓝 红+绿=黄 红+蓝=品红 蓝+绿=青 红+绿+蓝=白 无颜色为黑 下看代码 Bitmap image1 = new Bitmap(500, 500);//红 Bit ...
- Acwing周赛102
倍增 这是一道简单数论题 using namespace std; typedef long long LL; const int N = 1e5 + 10; int a[N], n; int div ...
- Codeforces Round 848 (Div. 2)C
B. The Forbidden Permutation 一定要注意题目中说的是对于all i满足才算不好的,我们做的时候只要破坏一个i这个a就不算好的了,被这一点坑了,没注意到all. #inclu ...
- windows上时间项目时间正常,Ubuntu16.04上时间错误
项目本次测试时间正常,放到服务器上时间差8个小时 1.查看Ubuntu系统时间,发现时间设置错误 date -R 该命令会把我们系统的时间还有时区显示出来,我们是属于东八区,如下图: 如果不是 +08 ...
- QT线程问题
QT线程问题 (一)QThread (二)QMutex和QMutexLocker (end)后面会更新 (一)QThread 文章 (二)QMutex和QMutexLocker 通俗理解 QMutex ...