PTA 21级数据结构与算法实验4—字符串和数组
7-1 字符串模式匹配(KMP)
给定一个字符串 text 和一个模式串 pattern,求 pattern 在text 中的出现次数。text 和 pattern 中的字符均为英语大写字母或小写字母。text中不同位置出现的pattern 可重叠。
输入格式:
输入共两行,分别是字符串text 和模式串pattern。
输出格式:
输出一个整数,表示 pattern 在 text 中的出现次数。
输入样例1:
zyzyzyz
zyz
输出样例1:
3
输入样例2:
AABAACAADAABAABA
AABA
输出样例2:
3
数据范围与提示:
1≤text, pattern 的长度 ≤106, text、pattern 仅包含大小写字母。
代码
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int ne[N];
char s[N], p[N]; // s[] 是主串, p[] 是模式串
int main() {
scanf("%s %s", s + 1, p + 1); // 让字符串从下标 1 开始存
int n = strlen(s + 1), m = strlen(p + 1);
// 获取 ne[] 数组
int j = 0;
for (int i = 2; i <= m; i++) {
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
int ans = 0;
for (int i = 1, j = 0; i <= n; i++) {
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j++;
// 如果模式串匹配到最后, 记录后继续匹配
if (j == m) ans++, j = ne[j];
}
cout << ans << endl;
return 0;
}
7-2 【模板】KMP字符串匹配
给出两个字符串text和pattern,其中pattern为text的子串,求出pattern在text中所有出现的位置。
为了减少骗分的情况,接下来还要输出子串的前缀数组next。
输入格式:
第一行为一个字符串,即为text。
第二行为一个字符串,即为pattern。
输出格式:
若干行,每行包含一个整数,表示pattern在text中出现的位置。
接下来1行,包括length(pattern)个整数,表示前缀数组next[i]的值,数据间以一个空格分隔,行尾无多余空格。
输入样例:
ABABABC
ABA
输出样例:
1
3
0 0 1
样例说明:
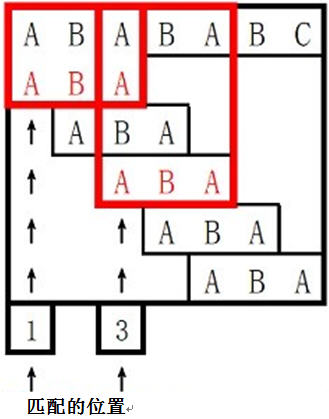
代码
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int ne[N];
char s[N], p[N];
int main() {
scanf("%s %s", s + 1, p + 1);
int n = strlen(s + 1), m = strlen(p + 1);
int j = 0;
for (int i = 2; i <= m; i++) {
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
for (int i = 1, j = 0; i <= n; i++) {
while (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j++;
if (j == m) cout << i - m + 1 << endl, j = ne[j];
}
for (int i = 1; i <= m; i++) {
if (i == 1) cout << ne[i];
else cout << " " << ne[i];
}
return 0;
}
7-3 统计子串
编写算法,统计子串t在主串s中出现的次数。
输入格式:
首先输入一个整数T,表示测试数据的组数,然后是T组测试数据。每组测试数据在第一行中输入主串s,在第二行中输入子串t,s和t中不包含空格。
输出格式:
对于每组测试,若子串t在主串s中出现,则输出t在s中的子串位置和出现总次数,否则输出“0 0”。引号不必输出。
输入样例:
2
abbbbcdebb
bb
abcde
bb
输出样例:
2 4
0 0
代码
#include<bits/stdc++.h>
using namespace std;
const int N = 1e6 + 10;
int ne[N];
char s[N], p[N];
int main() {
int t;
cin >> t;
while (t--) {
scanf("%s %s", s + 1, p + 1);
int n = strlen(s + 1), m = strlen(p + 1);
int j = 0;
memset(ne, 0, sizeof(ne));
for (int i = 2; i <= m; i++) {
if (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
int cnt = 0;
bool flag = 0;
int num = 0;
for (int i = 1, j = 0; i <= n; i++) {
if (j && s[i] != p[j + 1]) j = ne[j];
if (s[i] == p[j + 1]) j++;
if (j == m) {
cnt++, j = ne[j];
// 记录第一次匹配的位置
if (!flag) flag = 1, num = i - m + 1;
}
}
if (cnt) cout << num << " " << cnt << endl;
else cout << "0 0" << endl;
}
return 0;
}
7-4 好中缀
我们称一个字符串S的子串T为好中缀,如果T是去除S中满足如下条件的两个子串p和q后剩余的字符串。
(1)p是S的前缀,q是S的后缀;
(2)p=q;
(3)p和q是满足条件(1)(2)的所有子串中的第二长者。
注意一个字符串不能称为自己的前缀或后缀。好中缀至少为空串,其长度大于等于0,不能为负数。
输入格式:
输入为一个字符串S,包含不超过100000个字母。
输出格式:
输出为一个整数,表示好中缀的长度。
输入样例1:
abcabcxxxabcabc
输出样例1:
9
输入样例2:
xacbacba
输出样例2:
8
输入样例3:
aaa
输出样例3:
1
代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
int ne[N];
char p[N];
int main() {
scanf("%s", p + 1);
int m = strlen(p + 1);
int j = 0;
for (int i = 2; i <= m; i++) {
while (j && p[i] != p[j + 1]) j = ne[j];
if (p[i] == p[j + 1]) j++;
ne[i] = j;
}
int ans = m - 2 * ne[ne[m]];
if (ans <= 0) cout << "0" << endl;
else cout << ans << endl;
return 0;
}
7-5 病毒变种
病毒DNA可以表示成由一些字母组成的字符串序列,且病毒的DNA序列是环状的。例如,假设病毒的DNA序列为baa,则该病毒的DNA序列有三种变种:baa,aab,aba。试编写一程序,对给定的病毒DNA序列,输出该病毒所有可能的DNA序列(假设变种不会重复)。
输入格式:
输入第一行中给出1个整数i(1≤i≤11),表示待检测的病毒DNA。 输入i行串序列,每行一个字符串,代表病毒的DNA序列,病毒的DNA序列长度不超过500。
输出格式:
依次逐行输出每个病毒DNA所有变种,各变种之间用空格分隔。
输入样例1:
1
baa
输出样例1:
baa aab aba
输入样例2:
2
abc
baac
输出样例2:
abc bca cab
baac aacb acba cbaa
代码
C++
#include<bits/stdc++.h>
using namespace std;
int main() {
int t;
cin >> t;
while (t--) {
string a;
cin >> a;
int len = a.size();
for (int i = 0 ; i < len; i++) {
string x = a.substr(0, i);
string y = a.substr(i);
cout << y << x << " ";
}
cout << endl;
}
return 0;
}
C语言
#include <bits/stdc++.h>
using namespace std;
char a[510];
int main() {
int t;
scanf("%d", &t);
while (t--) {
scanf("%s", a);
int len = strlen(a);
for (int i = 0; i < len; i++) {
for (int j = i; j < len; j++) printf("%c", a[j]);
for (int j = 0; j < i; j++) printf("%c", a[j]);
printf(" ");
}
printf("\n");
}
return 0;
}
7-6 判断对称矩阵
将矩阵的行列互换得到的新矩阵称为转置矩阵。
把 m × n 矩阵的行列互换之后得到的矩阵,称为 A 的转置矩阵,记作 AT
由定义可知, A 为m×n 矩阵,则 AT为 n×m 矩阵。
n×n矩阵称之为 n阶方阵
如果 n 阶方阵和它的转置相等,即 AT= A ,则称矩阵 A 为对称矩阵。
输入格式:
在第一行内给出n值(1<n<100)。
从第二行以后给出n阶矩阵所有行的元素值。
输出格式:
当输入的n阶矩阵是对称矩阵,输出“Yes”,否则输出“No”。
输入样例1:
3
1 0 2
-2 1 3
4 3 2
输出样例1:
No
输入样例2:
3
1 -2 4
-2 1 3
4 3 2
输出样例2:
Yes
代码
#include<bits/stdc++.h>
using namespace std;
int a[111][111];
int main() {
int n;
cin >> n;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
cin >> a[i][j];
}
}
bool flag = 1;
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
if (a[i][j] != a[j][i]) {
flag = 0;
break;
}
}
if (!flag) break;
}
if (flag) cout << "Yes" << endl;
else cout << "No" << endl;
return 0;
}
7-7 三元组顺序表表示的稀疏矩阵转置运算Ⅰ
三元组顺序表表示的稀疏矩阵转置。
输入格式:
输入第1行为矩阵行数m、列数n及非零元素个数t。
按行优先顺序依次输入t行,每行3个数,分别表示非零元素的行标、列标和值。
输出格式:
输出转置后的三元组顺序表结果,每行输出非零元素的行标、列标和值,行标、列标和值之间用空格分隔,共t行。
输入样例:
3 4 3
0 1 -5
1 0 1
2 2 2
输出样例:
0 1 1
1 0 -5
2 2 2
代码
#include<bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
struct node {
int x, y, w;
}p[N];
bool cmp(node x, node y) {
if (x.x != y.x) return x.x < y.x;
return x.y < y.y;
}
int main() {
int n, m, t;
cin >> n >> m >> t;
// 直接 x 和 y 交换输入, 相当于转置后了
for (int i = 0; i < t; i++) cin >> p[i].y >> p[i].x >> p[i].w;
sort(p, p + t, cmp);
for (int i = 0; i < t; i++) cout << p[i].x << " " << p[i].y << " " << p[i].w << endl;
return 0;
}
7-8 三元组顺序表表示的稀疏矩阵加法
三元组顺序表表示的稀疏矩阵加法。
输入格式:
输入第1行为两个同型矩阵的行数m、列数n,矩阵A的非零元素个数t1,矩阵B的非零元素个数t2。
按行优先顺序依次输入矩阵A三元组数据,共t1行,每行3个数,分别表示非零元素的行标、列标和值。
按行优先顺序依次输入矩阵B三元组数据,共t2行,每行3个数,分别表示非零元素的行标、列标和值。
输出格式:
输出第1行为相加后矩阵行数m、列数n及非零元素个数t。
输出t行相加后的三元组顺序表结果,每行输出非零元素的行标、列标和值,每行数据之间用空格分隔。
输入样例:
4 4 3 4
0 1 -5
1 3 1
2 2 1
0 1 3
1 3 -1
3 0 5
3 3 7
输出样例:
4 4 4
0 1 -2
2 2 1
3 0 5
3 3 7
代码
#include<bits/stdc++.h>
using namespace std;
map<pair<int, int>, int> mp;
int main() {
int n, m, t1, t2;
cin >> n >> m >> t1 >> t2;
int x, y, w;
for (int i = 0; i < t1; i++) {
cin >> x >> y >> w;
mp[{x, y}] += w;
}
for (int i = 0; i < t2; i++) {
cin >> x >> y >> w;
mp[{x, y}] += w;
}
int cnt = 0;
for (auto it : mp) {
if (it.second) cnt++;
}
cout << n << " " << m << " " << cnt << endl;
for (auto it : mp) {
if (it.second) cout << it.first.first << " " << it.first.second << " " << it.second << endl;
}
return 0;
}
7-9 三元组顺序表表示的稀疏矩阵转置Ⅱ
三元组顺序表表示的稀疏矩阵转置Ⅱ。设a和b为三元组顺序表变量,分别表示矩阵M和T。要求按照a中三元组的次序进行转置,并将转置后的三元组置入b中恰当的位置。
输入格式:
输入第1行为矩阵行数m、列数n及非零元素个数t。
按行优先顺序依次输入t行,每行3个数,分别表示非零元素的行标、列标和值。
输出格式:
按置入b中的顺序输出置入的位置下标,转置后的三元组行标、列标和值,数据之间用空格分隔,共t行。
输入样例:
3 4 3
0 1 -5
1 0 1
2 2 2
输出样例:
1 1 0 -5
0 0 1 1
2 2 2 2
代码
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 10;
struct node {
int x, y, w;
} p[N];
map<pair<int, int>, int> mp;
vector<node> v;
bool cmp(node a, node b) {
if (a.x != b.x) return a.x < b.x;
return a.y < b.y;
}
int main() {
int n, m, t;
cin >> n >> m >> t;
for (int i = 0; i < t; i++) cin >> p[i].y >> p[i].x >> p[i].w;
for (int i = 0; i < t; i++) v.push_back({p[i].x, p[i].y});
sort(v.begin(), v.end(), cmp);
for (int i = 0; i < t; i++) mp[{v[i].x, v[i].y}] = i;
for (int i = 0; i < t; i++) {
int x = p[i].x, y = p[i].y, w = p[i].w;
cout << mp[{x, y}] << " " << x << " " << y << " " << w << endl;
}
return 0;
}
7-10 最大子矩阵和问题
最大子矩阵和问题。给定m行n列的整数矩阵A,求矩阵A的一个子矩阵,使其元素之和最大。
输入格式:
第一行输入矩阵行数m和列数n(1≤m≤100,1≤n≤100),再依次输入m×n个整数。
输出格式:
输出第一行为最大子矩阵各元素之和,第二行为子矩阵在整个矩阵中行序号范围与列序号范围。
输入样例:
5 6
60 3 -65 -92 32 -70
-41 14 -38 54 2 29
69 88 54 -77 -46 -49
97 -32 44 29 60 64
49 -48 -96 59 -52 25
输出样例:
输出第一行321表示子矩阵各元素之和,输出第二行2 4 1 6表示子矩阵的行序号从2到4,列序号从1到6
321
2 4 1 6
代码
#include <bits/stdc++.h>
using namespace std;
// 题目给 100, 但实际得开 1e3 才能过
const int N = 1e3 + 10;
int a[N][N];
int d[N][N];
int t[N];
int x, y, xx, yy;
int main() {
int n, m;
cin >> n >> m;
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= m; j++) {
scanf("%d", &a[i][j]);
d[i][j] = d[i - 1][j] + a[i][j];
}
}
int Max = 0;
for (int i = 0; i < n; i++) {
for (int j = i + 1; j <= n; j++) {
for (int k = 1; k <= m; k++) t[k] = d[j][k] - d[i][k];
int sum = 0;
int l = 1, r = 1;
for (int k = 1; k <= m; k++) {
sum += t[k];
if (sum < 0) {
sum = t[k];
l = r = k;
} else {
r = k;
}
if (sum > Max) {
Max = sum;
x = i + 1;
y = l;
xx = j;
yy = r;
}
}
}
}
printf("%d\n", Max);
printf("%d %d %d %d\n", x, xx, y, yy);
return 0;
}
PTA 21级数据结构与算法实验4—字符串和数组的更多相关文章
- 数据结构与算法实验题 6.1 s_sin’s bonus
数据结构与算法实验题 6.1 s_sin's bonus ★实验任务 正如你所知道的 s_sin 是一个非常贪玩的人 QAQ(如果你非常讨厌他请直接从第二段开 始看),并且令人感到非常遗憾的是,他是一 ...
- 数据结构与算法实验题 9.1 K 歌 DFS+剪枝
数据结构与算法实验题 K 歌 ★实验任务 3* n 个人(标号1~ 3 * n )分成 n 组 K 歌.有 m 个 3 人组合,每个组合都对应一个分数,你能算出最大能够得到的总分数么? ★数据输入 输 ...
- 数据结构与算法实验题 4.2 Who is the strongest
数据结构与算法实验题 4.2 Who is the strongest ★实验任务 在神奇的魔法世界,召唤师召唤了一群的魁偶.这些魁偶排成一排,每个魁偶都有一个 战斗值.现在该召唤师有一个技能,该技能 ...
- HDU 3791 二叉搜索树 (数据结构与算法实验题 10.2 小明) BST
传送门:http://acm.hdu.edu.cn/showproblem.php?pid=3791 中文题不说题意. 建立完二叉搜索树后进行前序遍历或者后序遍历判断是否一样就可以了. 跟这次的作业第 ...
- Java数据结构和算法(二):数组
上篇博客我们简单介绍了数据结构和算法的概念,对此模糊很正常,后面会慢慢通过具体的实例来介绍.本篇博客我们介绍数据结构的鼻祖——数组,可以说数组几乎能表示一切的数据结构,在每一门编程语言中,数组都是重要 ...
- 为什么我要放弃javaScript数据结构与算法(第二章)—— 数组
第二章 数组 几乎所有的编程语言都原生支持数组类型,因为数组是最简单的内存数据结构.JavaScript里也有数组类型,虽然它的第一个版本并没有支持数组.本章将深入学习数组数据结构和它的能力. 为什么 ...
- 《数据结构与算法之美》 <03>数组:为什么很多编程语言中数组都从0开始编号?
提到数组,我想你肯定不陌生,甚至还会自信地说,它很简单啊. 是的,在每一种编程语言中,基本都会有数组这种数据类型.不过,它不仅仅是一种编程语言中的数据类型,还是一种最基础的数据结构.尽管数组看起来非常 ...
- 【学习总结】java数据结构和算法-第三章-稀疏数组和队列
相关链接 [学习总结]尚硅谷2019java数据结构和算法 github:javaDSA 目录 稀疏数组 队列 稀疏数组 稀疏数组介绍 图示 应用实例 代码实现 SparseArray.java:与二 ...
- javascript 数据结构和算法读书笔记 > 第二章 数组
这章主要讲解了数组的工作原理和其适用场景. 定义: 一个存储元素的线性集合,元素可以通过索引来任意存取,索引通常是数字,用来计算元素之间存储位置的偏移量. javascript数组的特殊之处: jav ...
- 数据结构与算法实验题6.1 s_sin’s bonus byFZuer
玩家从n 个点n-1 条边的图,从节点1 丢下一个小球,小球将由于重力作用向下落,而从小球所在点延伸出的每一条边有一个值pi 为小球通过该条边的概率(注意从同一个节点向下延伸的所有边的pi 的和可以小 ...
随机推荐
- 谷歌浏览器配置vue调试工具
1.下载调试工具 下载地址:Vue Devtools_6.1.4_chrome扩展插件下载_极简插件 点击推荐下载 2.解压下载的压缩文件: 3.打开chrome浏览器,进入chrome://exte ...
- Nginx 面试题总结大全
转载请注明出处: 1 介绍下nginx特点与常用模块 2 nginx特点详细 3 反向代理和正向代理 4 负载均衡策略有哪些 5 Nginx如何实现动静分离? 6 Nginx 常用命令有哪些? 7 ...
- Mysql列转行, group_concat的使用
开始业务的查询的时候碰到一个sql的查询语句问题,主要是 group_concat 之前没用过,现在记录一下怎么用 group_concat 用法, 可以将相同的行组合起来 group_concat( ...
- 2022-09-18:以下go语言代码输出什么?A:1;B:15;C:panic index out of range;D:doesn’t compile。 package main import
2022-09-18:以下go语言代码输出什么?A:1:B:15:C:panic index out of range:D:doesn't compile. package main import ( ...
- 2021-04-03:给定两个字符串str1和str2,想把str2整体插入到str1中的某个位置,形成最大的字典序,返回字典序最大的结果。
2021-04-03:给定两个字符串str1和str2,想把str2整体插入到str1中的某个位置,形成最大的字典序,返回字典序最大的结果. 福大大 答案2021-04-03: 1.暴力法. 2.DC ...
- 从前后端的角度分析options预检请求
摘要:options预检请求是干嘛的?options请求一定会在post请求之前发送吗?前端或者后端开发需要手动干预这个预检请求吗?不用文档定义堆砌名词,从前后端角度单独分析,大白话带你了解! 本文分 ...
- Error in render: “TypeError: Cannot read property ‘0‘ of null“
我们web的同学运行程序时经常会遇到如下错误,而查找起来却相当费劲 看错误提示第一反应会想到是不是我的js 方法中的某个对象取值错误了,如: 但完全错了,当你把方法里的js 翻来覆去找了一遍又一遍,任 ...
- web自动化10-窗口截图、验证码处理
窗口截图 1.是什么 说明:把当前操作的页面,截图保存到指定位置 2.代码中怎么使用? 说明:在Selenium中,提供了截图方法,我们只需要调用即可 方法: driver.get_screensho ...
- /etc/netplan/network-manager-all.yaml 配置服务器ip
本文为博主原创,转载请注明出处: /etc/netplan 是用于配置 Ubuntu 系统网络接口的目录.在 Ubuntu 中,网络配置的默认工具为 Netplan,而 /etc/netplan 则 ...
- wireshark基本使用
Wireshark 是一种开源.跨平台的网络数据包分析工具,能够嗅探和调查实时流量并检查数据包捕获 (PCAP).它通常 被用作最好的数据包分析工具之一. 数据包过滤操作 ip过滤器 IP 过滤器帮助 ...