Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)论文阅读
深度估计问题
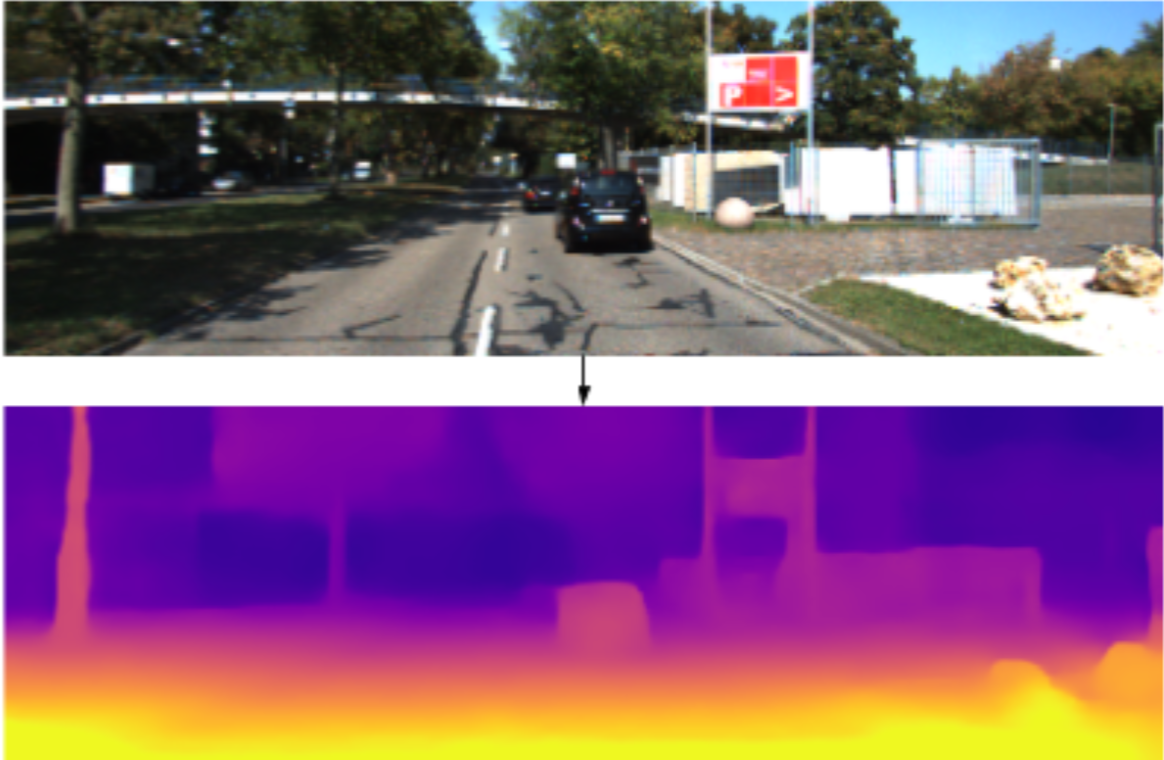
从输入的单目或双目图像,计算图像物体与摄像头之间距离(输出距离图),双目的距离估计应该是比较成熟和完善,但往单目上考虑主要还是成本的问题,所以做好单目的深度估计有一定的意义。单目的意思是只有一个摄像头,同一个时间点只有一张图片。就象你闭上一只眼睛,只用一只眼睛看这个世界的事物一样,距离感也会同时消失。
深度估计与语义分割的区别,及监督学习的深度估计问题
深度估计与语义分割有一定的联系,但也有一些区别。
- 图像的语义分割是识别每个像素的类别,不管这个像素出现在图像的那个位置,是一个分类任务。
- 而深度估计是识别每个像素与当前摄像头的距离,相同的车出现在图像的不同位置,其距离有可能不一样,是一个回归任务。
在深度估计上直接使用语义分割的方案,是可以达到一定的效果,但因为以上的区别,所以要把深度估计做好还是值得探讨。另外,
深度估计有监督学习的方案,但深度估计的监督学习存在两个问题:
- 监督学习所需要的label,制作上的代价比较大,不利于把方案应用到更多情境或验证;
- 如果以激光雷达的数据作为label,但激光雷达的探测距离比视觉近,一些超越探测距离的区域无法训练。
基于这些问题,本论文提出一种不需要真实深度label的自监督方法。
基本原理
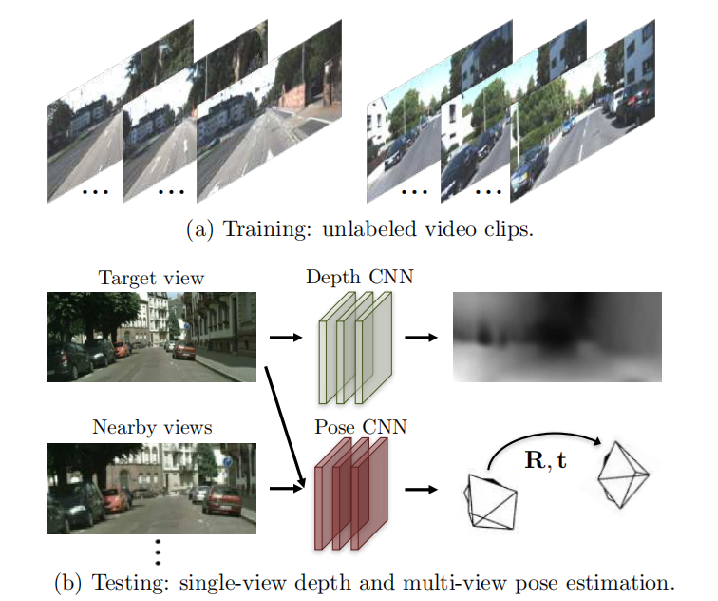
作者巧妙地利用SFM(Structure from motion)原理同时训练DepthNet(深度估计网络)和PoseNet(姿态估计网络),使用它们的输出重构图像$\hat I$与原图像$I$进行比较,免除真实深度label的需要。
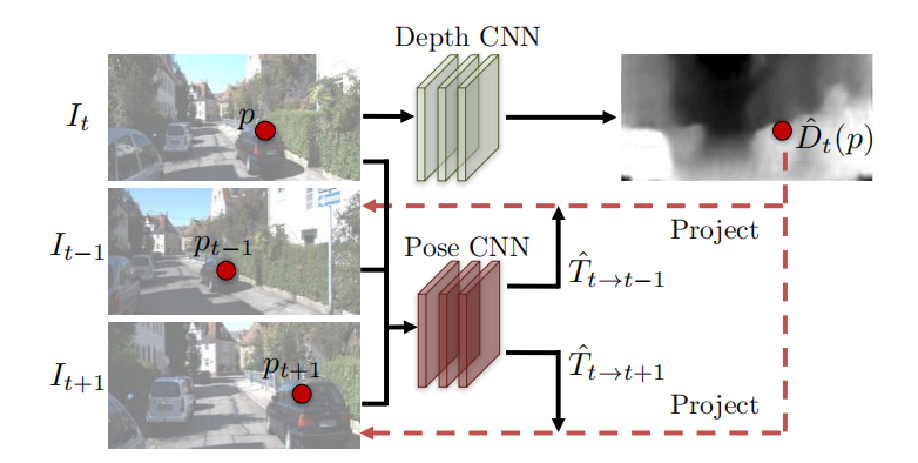
选择从时间上连续的三张图像,分别是$I_{t-1}$,$I_t$,$I_{t+1}$。DepthNet学习$I_t$的深度并输出深度图$\hat D_t$,PoseNet从$I_t$分别到$I_{t-1}$和$I_{t+1}$学习转换矩阵$\hat T_{t \to t-1}$和$\hat T_{t \to t+1}$,如上图,图像$I_t$里的$p$点可以通过对应的深度值$\hat D_t(p)$和转换矩阵$\hat T_{t \to t-1}$投影到$I_{t-1}$上对应位置$p_{t-1}$。
$p_s \sim K \hat T_{t \to s} \hat D_t(p_t)K^{-1}p_t$
其中,$K$是摄像头的内参矩阵(出厂时进行标定或自己标定)。
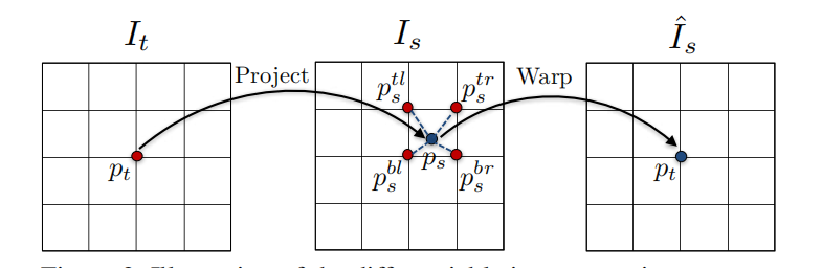
投影到的位置后使用相邻像素进行双线性插值进行图像重建,以光度重建缺失同时训练两个网络。
$L_{vs} = \sum_s{\sum_p | I_t(p) - \hat I_s(p)|}$
局限性
应用在视频时,方案包含了三个假设前提
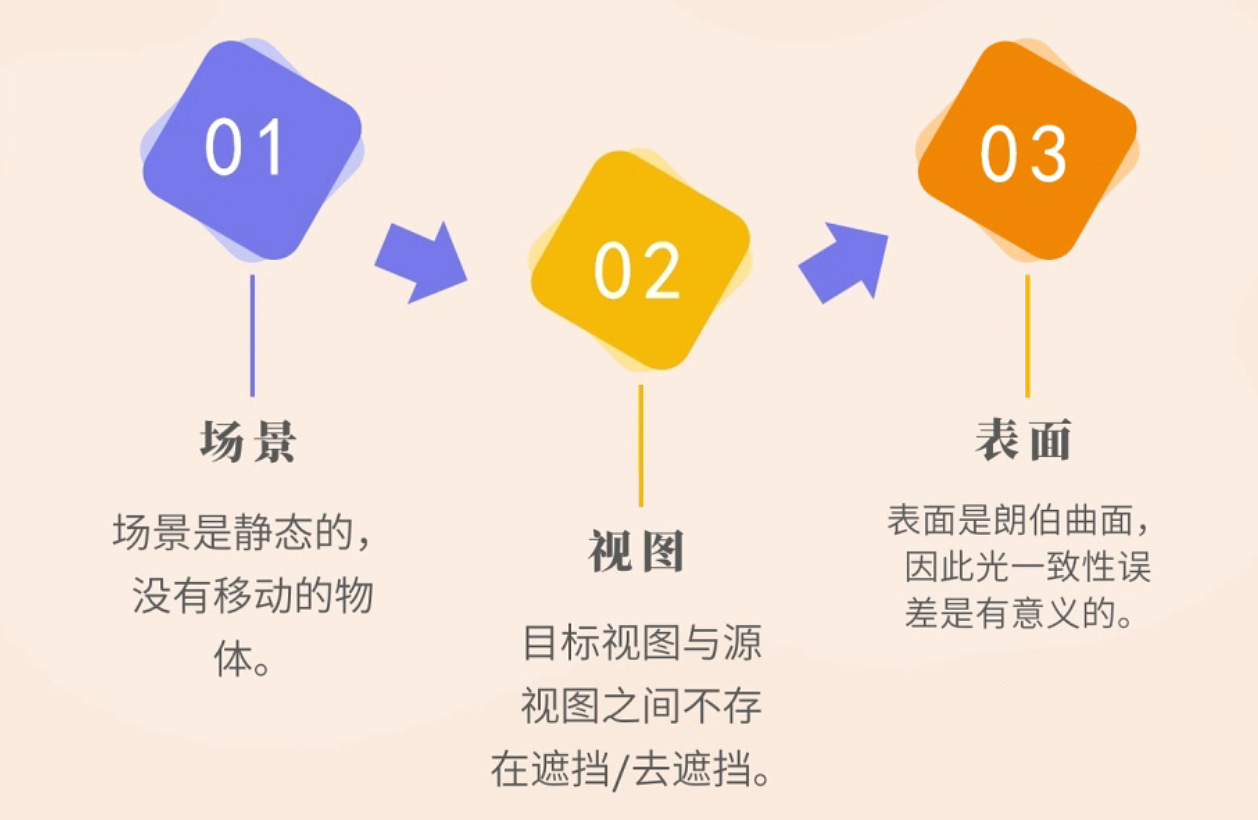
1. 依赖于SFM,如果图像里的物体是“静止”,其实是该物体和本身的运动速度一致,那个该物体在不同时间上的视图里,不会发生变化,固“静止”。
2. 不考虑遮挡,是先把要处理的问题简单化。
3. 重建损失的前提。
局限性解决
1. 解决静止和遮挡
增加一个可解释性预测网络,该网络为每个目标-源对输出每个像素的软掩码$\hat E_s$,表明网络信任那些目标像素能进行视图合成。基于$\hat E_s$后的损失函数为
$L_{vs} = \sum_{<I_1,...,I_N> \in S}{\sum_p{\hat E_s(p)|I_t(p) - \hat I_s(p)|}}
由于不能对$\hat E_s$直接监督,使用上述的损失进行训练将导致网络总是预测$\hat E_s$为零(就最小化了损失)。为了解决这个问题,添加一个正则项$L_{reg}(\hat E_s)$,通过在每个像素位置上使用常数标签1最小化交叉熵损失来鼓励非零预测。
2. 克服梯度局部性
上述的学习方式还有一个遗留问题,梯度主要来自$I(p_t)$和它4个邻居之间的像素强度差,如果像素位于低纹理区域或远离当前估计,则会抑制训练。解决这个问题有两个方案:
1. 使用总面积encoder-deconder架构,深度网络的输出隐含地约束全局平滑,并促进梯度从有意义的区域传播到附近的区域。
2. 明确的多尺度和平滑损失,允许直接从更大的空间区域导出梯度。
作者选择第二种方案,原因是它对架构选择不太敏感。为了平滑,作者最小化预测深度图的二阶梯度的L1范数。最终的损失函数为:
$L_{final} = \sum_l{L_{vs}^l} + \lambda_s L_{smooth}^l + \lambda_e \sum_s{L_{reg}(\hat E_s^l)}$
总结
在作者提出该方案前,已经存在基于深度值的监督学习和基于姿态的监督学习,他的出发点是以多种有相关性的任务同时学习,从而融合它们的学习结果可以回归到原图像,这使一方面同时训练多个相关模型,另一方面能起到自监督的效果。
Unsupervised Learning of Depth and Ego-Motion from Video(CVPR2017)论文阅读的更多相关文章
- Learning under Concept Drift: A Review 概念漂移综述论文阅读
首先这是2018年一篇关于概念漂移综述的论文[1]. 最新的研究内容包括 (1)在非结构化和噪声数据集中怎么准确的检测概念漂移.how to accurately detect concept dri ...
- SfMLearner论文笔记——Unsupervised Learning of Depth and Ego-Motion from Video
1. Abstract 提出了一种无监督单目深度估计和相机运动估计的框架 利用视觉合成作为监督信息,使用端到端的方式学习 网络分为两部分(严格意义上是三个) 单目深度估计 多视图姿态估计 解释性网络( ...
- Unsupervised learning, attention, and other mysteries
Unsupervised learning, attention, and other mysteries Get notified when our free report “Future of M ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- Unsupervised Learning: Use Cases
Unsupervised Learning: Use Cases Contents Visualization K-Means Clustering Transfer Learning K-Neare ...
- Unsupervised Learning and Text Mining of Emotion Terms Using R
Unsupervised learning refers to data science approaches that involve learning without a prior knowle ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- Unsupervised learning无监督学习
Unsupervised learning allows us to approach problems with little or no idea what our results should ...
- PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning --- 论文笔记
PredNet --- Deep Predictive coding networks for video prediction and unsupervised learning ICLR 20 ...
- 131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类
@(131 - Machine Learning | 机器学习) 零. Goal How Unsupervised Learning fills in that model gap from the ...
随机推荐
- Android 通过scheme跳转支付宝实现支付
原文地址: Android 通过scheme跳转支付宝实现支付 - Stars-One的杂货小窝 需求的来源是支付功能,由于支付宝不允许个人开通具有webhook的支付服务,所以是对接了一个支付系统( ...
- 如何在Godot中使用ParallaxBackground实现稳定的2d游戏背景[一问随笔]
问题: 我尝试给2d游戏添加静态的背景,当角色运动速度很快时相机的渲染就跟不上角色了,背景会发生这样巨大的位移. 我将Camera2d节点和背景节点绑在一起,但根本无法解决这个问题. 我还尝试制作天空 ...
- InnoSetup打包 添加.NET环境安装
这是封装出来的针对.NET环境安装的精简流程 根据流程新建一个配置文件 教程都是很简单的,可以参考<InnoSetup 客户端程序打包教程> 添加.NET安装基本的函数及辅助方法 在[Se ...
- Python 项目:外星人入侵--第三部分
1.项目内容: 在屏幕左上角添加一个外星人,并指定合适的边框,根据第一个外星人的边距和屏幕尺寸计算屏幕上可容纳多少个外星人. 让外星人群向两边和下方移动,直到外星人被全部击落,有外星人撞到飞船,或有外 ...
- Vue实战案例
Vue项目案例 结合之前学习的 vue.js.脚手架.vuex.vue-router.axios.elementui 等知识点,来开发前端项目案例(仅前端不含后端). 1.项目搭建 其实就是将我们项目 ...
- 解密Elasticsearch:深入探究这款搜索和分析引擎
作者:京东保险 管顺利 开篇 最近使用Elasticsearch实现画像系统,实现的dmp的数据中台能力.同时调研了竞品的架构选型.以及重温了redis原理等.特此做一次es的总结和回顾.网上没看到有 ...
- 2022-07-22:以下go语言代码输出什么?A:1;B:1.5;C:编译错误;D:1.49。 package main import “fmt“ func main() { var i
2022-07-22:以下go语言代码输出什么?A:1:B:1.5:C:编译错误:D:1.49. package main import "fmt" func main() { v ...
- 2022-07-01:某公司年会上,大家要玩一食发奖金游戏,一共有n个员工, 每个员工都有建设积分和捣乱积分, 他们需要排成一队,在队伍最前面的一定是老板,老板也有建设积分和捣乱积分, 排好队后,所有
2022-07-01:某公司年会上,大家要玩一食发奖金游戏,一共有n个员工, 每个员工都有建设积分和捣乱积分, 他们需要排成一队,在队伍最前面的一定是老板,老板也有建设积分和捣乱积分, 排好队后,所有 ...
- 2021-06-18:已知数组arr,生成一个数组out,out的每个元素必须大于等于1,当arr[cur]>arr[cur-1]时,out[cur]>out[cur-1];当arr[cur]>arr
2021-06-18:已知数组arr,生成一个数组out,out的每个元素必须大于等于1,当arr[cur]>arr[cur-1]时,out[cur]>out[cur-1]:当arr[cu ...
- vue全家桶进阶之路19:webpack资源打包工具
Vue.js 是一个前端开发框架,它可以帮助我们快速构建单页应用和复杂的交互界面.而 Webpack 则是一个前端资源打包工具,它可以将多个 JavaScript.CSS.HTML.图片等资源打包成一 ...