Jax计算框架的NamedSharding的reshape —— namedsharding-gives-a-way-to-express-shardings-with-names
本篇post的主要讲解的是:
jax.device_put(x, mesh_sharding(P(('a', 'b'), None)))
与
jax.device_put(x, mesh_sharding(P(('b', 'a'), None)))
的不同:
主机的四个CPU情况:
代码:
import os
import functools
from typing import Optional
import numpy as np
import jax
import jax.numpy as jnp
from jax.experimental import mesh_utils
from jax.sharding import PositionalSharding
# Create a Sharding object to distribute a value across devices:
sharding = PositionalSharding(mesh_utils.create_device_mesh((4,)))
# Create an array of random values:
x = jax.random.normal(jax.random.PRNGKey(0), (8192, 8192))
# and use jax.device_put to distribute it across devices:
y = jax.device_put(x, sharding.reshape(2, 2))
jax.debug.visualize_array_sharding(y)
运行结果:
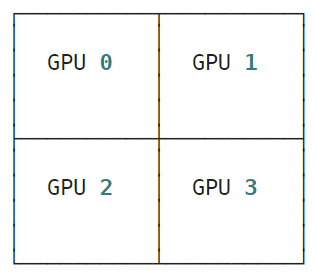
jax.device_put(x, mesh_sharding(P(('a', 'b'), None)))
代码:(行优先的方式展开GPU)
点击查看代码
from typing import Optional
import jax
from jax.sharding import Mesh
from jax.sharding import PartitionSpec
from jax.sharding import NamedSharding
from jax.experimental import mesh_utils
P = PartitionSpec
devices = mesh_utils.create_device_mesh((2, 2))
mesh = Mesh(devices, axis_names=('a', 'b'))
from jax.sharding import PositionalSharding
sharding = PositionalSharding(devices)
x = jax.random.normal(jax.random.PRNGKey(0), (8192, 8192))
x = jax.device_put(x, sharding.reshape(4, 1))
devices = mesh_utils.create_device_mesh((2, 2))
default_mesh = Mesh(devices, axis_names=('a', 'b'))
def mesh_sharding(
pspec: PartitionSpec, mesh: Optional[Mesh] = None,
) -> NamedSharding:
if mesh is None:
mesh = default_mesh
return NamedSharding(mesh, pspec)
y = jax.device_put(x, mesh_sharding(P(('a', 'b'), None)))
jax.debug.visualize_array_sharding(y)
运行结果:
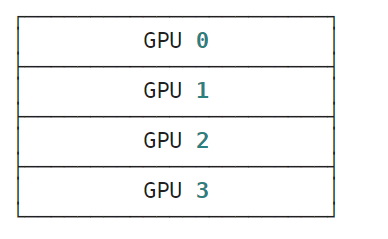
jax.device_put(x, mesh_sharding(P(('b', 'a'), None)))
代码:(列优先的方式展开GPU)
点击查看代码
from typing import Optional
import jax
from jax.sharding import Mesh
from jax.sharding import PartitionSpec
from jax.sharding import NamedSharding
from jax.experimental import mesh_utils
P = PartitionSpec
devices = mesh_utils.create_device_mesh((2, 2))
mesh = Mesh(devices, axis_names=('a', 'b'))
from jax.sharding import PositionalSharding
sharding = PositionalSharding(devices)
x = jax.random.normal(jax.random.PRNGKey(0), (8192, 8192))
x = jax.device_put(x, sharding.reshape(4, 1))
devices = mesh_utils.create_device_mesh((2, 2))
default_mesh = Mesh(devices, axis_names=('a', 'b'))
def mesh_sharding(
pspec: PartitionSpec, mesh: Optional[Mesh] = None,
) -> NamedSharding:
if mesh is None:
mesh = default_mesh
return NamedSharding(mesh, pspec)
y = jax.device_put(x, mesh_sharding(P(('b', 'a'), None)))
jax.debug.visualize_array_sharding(y)
运行结果:
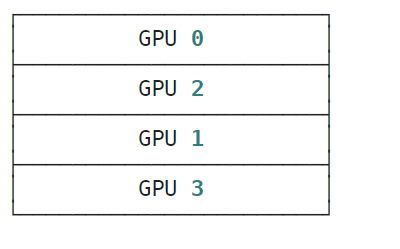
Jax计算框架的NamedSharding的reshape —— namedsharding-gives-a-way-to-express-shardings-with-names的更多相关文章
- Storm分布式实时流计算框架相关技术总结
Storm分布式实时流计算框架相关技术总结 Storm作为一个开源的分布式实时流计算框架,其内部实现使用了一些常用的技术,这里是对这些技术及其在Storm中作用的概括介绍.以此为基础,后续再深入了解S ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- Storm实时计算框架的编程模式
storm分布式流式计算框架. nimbus:主进程服务(职责就是任务的分配的,程序的分发) supervisor:工作进程服务(职责就是启动线程池,接受任务,运行任务,报告任务的运行状态) 注意容错 ...
- 开源图计算框架GraphLab介绍
GraphLab介绍 GraphLab 是由CMU(卡内基梅隆大学)的Select 实验室在2010 年提出的一个基于图像处理模型的开源图计算框架.框架使用C++语言开发实现. 该框架是面向机器学习( ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- (第4篇)hadoop之魂--mapreduce计算框架,让收集的数据产生价值
摘要: 通过前面的学习,大家已经了解了HDFS文件系统.有了数据,下一步就要分析计算这些数据,产生价值.接下来我们介绍Mapreduce计算框架,学习数据是怎样被利用的. 博主福利 给大家赠送一套ha ...
- Dream_Spark-----Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码
Spark 定制版:005~贯通Spark Streaming流计算框架的运行源码 本讲内容: a. 在线动态计算分类最热门商品案例回顾与演示 b. 基于案例贯通Spark Streaming的运 ...
- 【流处理】Kafka Stream-Spark Streaming-Storm流式计算框架比较选型
Kafka Stream-Spark Streaming-Storm流式计算框架比较选型 elasticsearch-head Elasticsearch-sql client NLPchina/el ...
- 【codenet】代码相似度计算框架调研 -- 把内容与形式分开
首发于我的gitpages博客 https://helenawang.github.io/2018/10/10/代码相似度计算框架调研 代码相似度计算框架调研 研究现状 代码相似度计算是一个已有40年 ...
- Storm:分布式流式计算框架
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 由于Storm的处理组件都是分布式的,而且处理 ...
随机推荐
- ARC169
A 我们定义 \(dp_{dep}\) 为第 \(dep\) 层会对上一层产生多少的影响. 如果有一层的影响大于 \(0\),在足够次计算后那么肯定是正号.如果小于零那就一定是负号. 由于越久影响到的 ...
- 如何基于R包做GO分析?实现秒出图
GO分析 基因本体论(Gene Ontology, GO)是一个用于描述基因和基因产品属性的标准术语体系.它提供了一个有组织的方式来表示基因在生物体内的各种角色.基因本体论通常从三个层面对基因进行描述 ...
- mongodb数据库连接格式
mongodb数据库连接格式 mongodb://账号:密码@mongodb服务器IP:27017/数据库名称
- Navicat 连接SQL Server LocalDB的方法
截止2021年11月,Sql Server LocalDB的资料网上并不多见,出来了其实也有一段年头了. SqlServerManagerStudio自带的工具进行查询使用体验并不好,Navicat是 ...
- 关于 Jupyter Nbconvert 自定义 LaTeX 模板,中文兼容与格式设置,从 Notebook 构建 LaTeX PDF 文档
目录 为什么会有这篇随笔的内容? 简述一下我遇到的问题 Nbconvert 转换 .ipynb 文件的基本方法 Jupyter Nbconvert 构建中文 \(\LaTeX\) 文档的痛点 Jupy ...
- JSP四个作用域和九个对象
一.四个作用域 (1)Requset 请求作用域,就是客户端的一次请求 (2)Session 会话作用域,当用户首次访问时,产生一个新的会话,以后服务器就可以记住这个会话状态.生命周期:会话超时,或者 ...
- Android系统启动:.rc文件
Android系统启动:.rc文件 reference : https://www.jianshu.com/p/a4c17f0110d0 以init.rc为例. .rc文件 init.rc文件由系统第 ...
- arm linux 移植 e2fsprogs
背景 之前在zynq平台下处理系统分区,用到了SPI-FLASH以及EMMC. 根据ZYNQ平台的特性以及产品升级需要,规划了 SPI-FLASH放置BootLoader EMMC中分为2个区,一个F ...
- Coap 协议学习:具体协议介绍具体
协议框架 CoAP默认运行在UDP上,但它也支持运行在SMS,TCP等数据传输层上.本文主要是基于UDP上的CoAP协议介绍 1.消息模型 Messages COAP协议通信是通过在UDP上传输消息类 ...
- 模拟用户登录-cookes
import requests url = 'https://www.xread8.com/user/login.json' headers = { 'User-Agent': 'Mozilla/5. ...