关于Linux系统下zookeeper集群的搭建
1.集群概述
1.1什么是集群
1.1.1集群概念
集群是一种计算机系统, 它通过一组松散集成的计算机软件和/或硬件连接起来高度紧密地协作完成计算工作。在某种意义上,他们可以被看作是一台计算机。集群系统中的单个计算机通常称为节点,通常通过局域网连接,但也有其它的可能连接方式。集群计算机通常用来改进单个计算机的计算速度和/或可靠性。一般情况下集群计算机比单个计算机,比如工作站或超级计算机性能价格比要高得多。

1.1.2集群的特点
集群拥有以下两个特点:
1. 可扩展性:集群的性能不限制于单一的服务实体,新的服务实体可以动态的添加到集群,从而增强集群的性能。
2. 高可用性:集群当其中一个节点发生故障时,这台节点上面所运行的应用程序将在另一台节点被自动接管,消除单点故障对于增强数据可用性、可达性和可靠性是非常重要的。
1.1.3集群的两大能力
1. 负载均衡:负载均衡把任务比较均匀的分布到集群环境下的计算和网络资源,以提高数据吞吐量。
2. 错误恢复:如果集群中的某一台服务器由于故障或者维护需要无法使用,资源和应用程序将转移到可用的集群节点上。这种由于某个节点的资源不能工作,另一个可用节点中的资源能够透明的接管并继续完成任务的过程,叫做错误恢复。
负载均衡和错误恢复要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图必须是相同的。
补充:可能会有人问服务器集群是怎么实现负载均衡的?
当系统面临大量用户访问,负载过高的时候,通常会使用增加服务器数量来进行横向扩展,使用集群和负载均衡提高整个系统的处理能力。
而我们讨论的负载均衡一般分为两种,一种是基于DNS,另一种基于IP报文。
利用DNS实现负载均衡,就是在DNS服务器配置多个A记录,不同的DNS请求会解析到不同的IP地址。大型网站一般使用DNS作为第一级负载均衡。
缺点是DNS生效时间略长,扩展性差。
基于IP的负载均衡,早期比较有代表性并且被大量使用的的就是LVS了。原理是LVS在Linux内核态获取到IP报文后,根据特定的负载均衡算法将IP报文转发到整个集群的某台服务器中去。
缺点是LVS的性能依赖Linux内核的网络性能,但Linux内核的网络路径过长导致了大量开销,使得LVS单机性能较低。
那么有没有更好的负载均衡技术呢?当然有。详情请参照知乎https://www.zhihu.com/question/22610352/answer/126894813
从Google Maglev说起,如何造一个牛逼的负载均衡?
1.2集群与分布式的区别
说到集群,可能大家会立刻联想到另一个和它很相近的一个词----“分布式”。那么集群和分布式是一回事吗?有什么联系和区别呢?
相同点:
分布式和集群都是需要有很多节点服务器通过网络协同工作完成整体的任务目标。
不同点:
分布式是指将业务系统进行拆分,即分布式的每一个节点都是实现不同的功能。而集群每个节点做的是同一件事情。
2.Zookeeper集群
2.1 Zookeeper集群简介
2.1.1为什么搭建Zookeeper集群
大部分分布式应用需要一个主控、协调器或者控制器来管理物理分布的子进程。目前,大多数都要开发私有的协调程序,缺乏一个通用机制,协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器,zookeeper提供通用的分布式锁服务,用以协调分布式应用。所以说zookeeper是分布式应用的协作服务。
zookeeper作为注册中心,服务器和客户端都要访问,如果有大量的并发,肯定会有等待。所以可以通过zookeeper集群解决。
下面是zookeeper集群部署结构图:

2.1.2了解Leader选举
Zookeeper的启动过程中leader选举是非常重要而且最复杂的一个环节。那么什么是leader选举呢?zookeeper为什么需要leader选举呢?zookeeper的leader选举的过程又是什么样子的?
首先我们来看看什么是leader选举。其实这个很好理解,leader选举就像总统选举一样,每人一票,获得多数票的人就当选为总统了。在zookeeper集群中也是一样,每个节点都会投票,如果某个节点获得超过半数以上的节点的投票,则该节点就是leader节点了。
以一个简单的例子来说明整个选举的过程.
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的.假设这些服务器依序启动,来看看会发生什么 。
1) 服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态
2) 服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1,2还是继续保持LOOKING状态.
3) 服务器3启动,根据前面的理论分析,服务器3成为服务器1,2,3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader.
4) 服务器4启动,根据前面的分析,理论上服务器4应该是服务器1,2,3,4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了.
5) 服务器5启动,同4一样,当小弟
2.2搭建Zookeeper集群
2.2.1搭建要求
真实的集群是需要部署在不同的服务器上的,但是在我们测试时同时启动十几个虚拟机内存会吃不消,所以这里我们搭建伪集群,也就是把所有的服务都搭建在一台虚拟机上,用端口进行区分。
我们这里要求搭建一个三个节点的Zookeeper集群(伪集群)。
2.2.2准备工作
重新部署一台虚拟机作为我们搭建集群的测试服务器。(虚拟机的准备详见我在CSDN写的一篇文章:Zookeeper集群安装之虚拟机准备)
(1)安装JDK 【此步骤省略】。
(2)Zookeeper压缩包上传到服务器
(3)将Zookeeper解压 ,创建data目录 ,将 conf下zoo_sample.cfg 文件改名为 zoo.cfg【mv zoo_sample.cfg zoo.cfg】
(4)建立/usr/local/zookeeper-cluster目录,将解压后的Zookeeper复制到以下三个目录
[root@mini1 ~]# cp -r zookeeper-3.4. /usr/local/zookeeper-cluster/zookeeper-
[root@mini1 ~]# cp -r zookeeper-3.4. /usr/local/zookeeper-cluster/zookeeper-
[root@mini1 ~]# cp -r zookeeper-3.4. /usr/local/zookeeper-cluster/zookeeper-
(5) 配置每一个Zookeeper 的dataDir(zoo.cfg) clientPort 分别为2181 2182 2183
修改/usr/local/zookeeper-cluster/zookeeper-1/conf/zoo.cfg
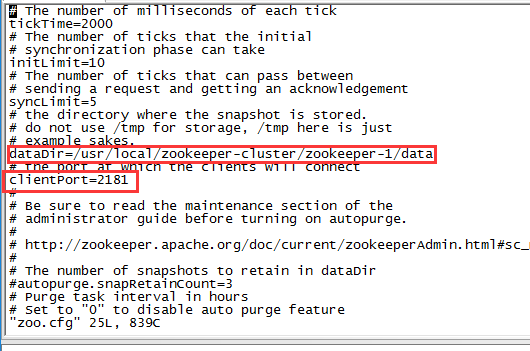
修改/usr/local/zookeeper-cluster/zookeeper-2/conf/zoo.cfg
clientPort=
dataDir=/usr/local/zookeeper-cluster/zookeeper-/data
修改/usr/local/zookeeper-cluster/zookeeper-3/conf/zoo.cfg
clientPort=
dataDir=/usr/local/zookeeper-cluster/zookeeper-/data
2.2.3配置集群
(1)在每个zookeeper的 data 目录下创建一个 myid 文件,内容分别是1、2、3 。这个文件就是记录每个服务器的ID
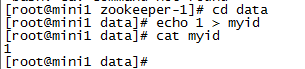
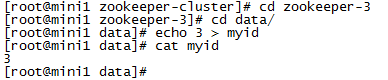
(2)在每一个zookeeper 的 zoo.cfg配置客户端访问端口(clientPort)和集群服务器IP列表。
server.=192.168.75.10::
server.=192.168.75.10::
server.=192.168.75.10::
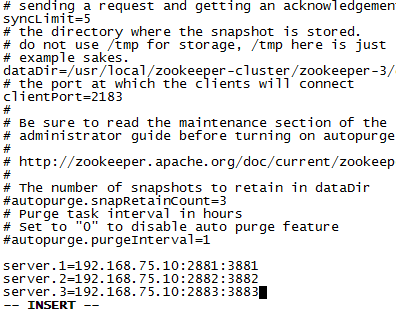
解释:server.服务器ID=服务器IP地址:服务器之间通信端口:服务器之间投票选举端口
2.2.4启动集群
启动集群就是分别启动每个实例。
cd /usr/local/zookeeper-cluster/zookeeper-/bin/
./zkServer.sh start cd /usr/local/zookeeper-cluster/zookeeper-/bin/
./zkServer.sh start cd /usr/local/zookeeper-cluster/zookeeper-/bin/
./zkServer.sh start
启动后我们查询一下每个实例的运行状态
先查询第一个服务

Mode为follower表示是跟随者(从)
再查询第二个服务Mod 为leader表示是领导者(主)

查询第三个为跟随者(从)

之前在CSDN上写了一篇SolrCloud 分布式集群安装部署(solr+ zookeeper +tomcat)有兴趣的朋友可以看一下!
关于Linux系统下zookeeper集群的搭建的更多相关文章
- Linux环境下ZooKeeper集群环境搭建关键步骤
ZooKeeper版本:zookeeper-3.4.9 ZooKeeper节点:3个节点 以下为Linux环境下ZooKeeper集群环境搭建关键步骤: 前提条件:已完成在Linux环境中安装JDK并 ...
- Linux环境下SolrCloud集群环境搭建关键步骤
Linux环境下SolrCloud集群环境搭建关键步骤. 前提条件:已经完成ZooKeeper集群环境搭建. 一.下载介质 官网下载地址:http://www.apache.org/dyn/close ...
- Linux环境下HDFS集群环境搭建关键步骤
Linux环境下HDFS集群环境搭建关键步骤记录. 介质版本:hadoop-2.7.3.tar.gz 节点数量:3节点. 一.下载安装介质 官网下载地址:http://hadoop.apache.or ...
- linux环境(CentOS-6.7)下redis集群的搭建全过程
linux环境下redis集群的搭建全过程: 使用mount命令将光盘挂载到/mnt/cdrom目录下: [root@hadoop03 ~]# mount -t iso9660 -o ro /dev/ ...
- Linux下zookeeper集群搭建
Linux下zookeeper集群搭建 部署前准备 下载zookeeper的安装包 http://zookeeper.apache.org/releases.html 我下载的版本是zookeeper ...
- Centos6下zookeeper集群部署记录
ZooKeeper是一个开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名服务等. Zookeeper设计目的 最终一致性:client不论 ...
- 原创:centos7.1下 ZooKeeper 集群安装配置+Python实战范例
centos7.1下 ZooKeeper 集群安装配置+Python实战范例 下载:http://apache.fayea.com/zookeeper/zookeeper-3.4.9/zookeepe ...
- Linux环境下Hadoop集群搭建
Linux环境下Hadoop集群搭建 前言: 最近来到了武汉大学,在这里开始了我的研究生生涯.昨天通过学长们的耐心培训,了解了Hadoop,Hdfs,Hive,Hbase,MangoDB等等相关的知识 ...
- centos7下安装zookeeper&zookeeper集群的搭建
一.centos7下安装zookeeper 1.zookeeper 下载地址 https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/ 2.安装步骤 ...
随机推荐
- Sqoop环境安装
环境下载 首先将下载的 sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz放到 /usr/hadoop/目录下(该目录可以自定义,一般为Hadoop集群安装目录),然 ...
- 64位wampserver开启curl扩展失败的问题
今天在运行程序时报错: Fatal error:Call to undefined function curl_init()... 在网上查了一下,是因为php_curl.dll扩展没有开启的缘故,于 ...
- SpringBoot | 第九章:Mybatis-plus的集成和使用
前言 本章节开始介绍数据访问方面的相关知识点.对于后端开发者而言,和数据库打交道是每天都在进行的,所以一个好用的ORM框架是很有必要的.目前,绝大部分公司都选择MyBatis框架作为底层数据库持久化框 ...
- 让我们把KBEngine玩坏吧!如何定制我们自己的C++函数(一)
为什么不更新kbe warring的代码解读了,因为在我看来那个demo讲完了实体就没东西可讲了,如果专心的看官方文档和PPT的话demo的代码后面没任何难点了已经,单纯的复制黏贴代码实在太过无聊.程 ...
- linux启动mysql报错 Starting MySQL... ERROR! The server quit without updating PID file (XXXX pid文件位置)
最近在云服务器上安装mysql 启动时报错了,从错误中可以看出,定位在pid文件上,有三种解决方案 1.重启服务器:因为服务器更新时,可能会禁用某些守护进程,重启后即可恢复 2.删除配置文件,重启试 ...
- spring的工厂方法
http://blog.csdn.net/nvd11/article/details/51542360
- enable orgmode latex preview to support retina on mac
Table of Contents 1. enable orgmode latex preview to support retina on mac 1.1. get the proper versi ...
- es6声明对象以及作用域与es5对比
es6声明变量: let x=1;//声明一个变量 const y=2;//声明一个只读常量,声明时必须赋值,之后值不可修改 es5声明变量: var z=3;//声明一个变量 区别: let不存在变 ...
- Vue.js(2.x)之插值
看了一些友邻写的文章,不少是基于1.0版本的,有些东西在2.x版本应该已经废除了(如属性插值.单次插值在2.x版本上运行根本不执行).对于不理解的东东,找起资料来就更麻烦了.不得不老老实实线下测试并整 ...
- pure响应式布局
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...