python3爬虫之Urllib库(一)
上一篇我简单说了说爬虫的原理,这一篇我们来讲讲python自带的请求库:urllib
在python2里边,用urllib库和urllib2库来实现请求的发送,但是在python3种在也不用那么麻烦了,因为只有一个库了:Urllib.
urllib库是python的标准库,简而言之就是不用自己安装,使用时只需要import一下就好。
urllib库包含4个模块:
request: 最基本的HTTP请求模块,用来发起请求,就和人们在浏览器上输入网址来访问网页一样。
error: 异常处理模块,如果在请求时出现错误,用这个模块来抓住异常,保证程序不会因为抛出异常而挂掉。
parse: 一个工具模块,提供了许多URL处理方法,比如URL的拆分、合并等等。
robotparser:主要用来识别目标网站的robot.txt文件(基本用不上)
使用request模块可以发送请求,主要有两个方法: urlopen() Request()
urlopen()
首先来举个栗子:我们来使用urlopen方法来请求“笔趣阁”网站
这是urllib()的API:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
from urllib import request target_url = 'http://www.biquge9.com/'
result = request.urlopen(target_url)
print(result.read().decode('utf-8'))
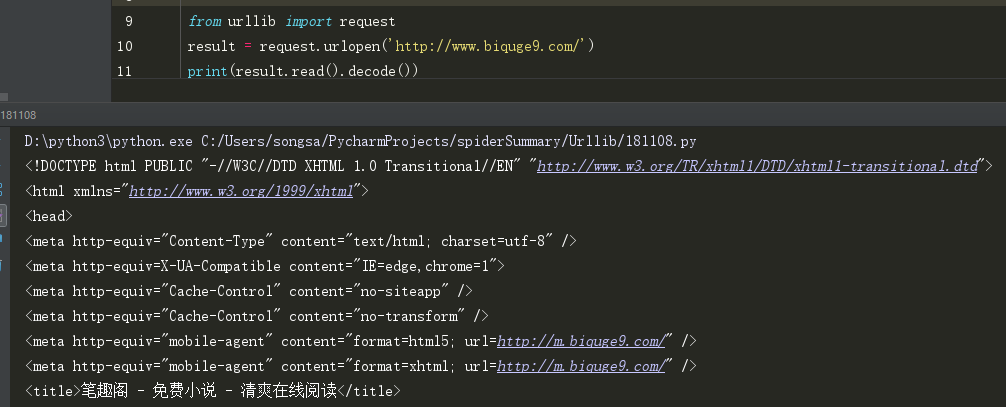
部分结果截图(整个网页内容太多放不下,我仅仅把网页的头部截了下来):

是不是很强大?几行代码就可以扒下想要网页源代码,只要源码在手,里边的内容还不是想怎么拿怎么拿
urllib库的request模块提供了最基本的用来构造HTTP请求的方法,整个请求过程已经完全封装好了,我们只需要调用固定的方法,传给相应的参数就可以发起请求了。
下边我们来分析一下刚刚那几行代码:
from urllib import request # 用来导入urllib库的request模块
result = request.urlopen(target_url) # 使用urlopen方法来请求网页
我们打印一下result的格式:
<class 'http.client.HTTPResponse'> 这是一个HTTPOResponse类型的对象。这个对象我们是无法直接获取网页内容的,但是或者对象包含了许多方法与属性:如 read() readinto() getheader(name) getheaders() fileno() geturl() info() getcode() 等方法和msg version status reason debuglevel closed等属性,通过调用这些方法和属性,我们就可以获取到关于html页面的信息。
方法:
(1)read() 调用read()方法就可以查看到网页的源代码了。但是得到的是bytes字节的类型。

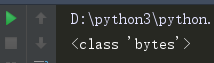
所以我们要用decode()将bytes进行解码得到最终的html源代码
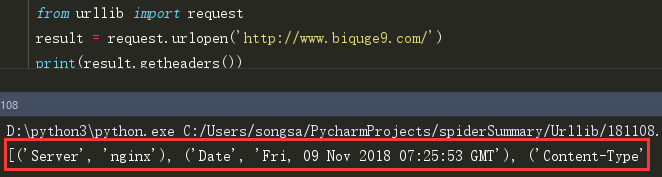
(2)getheaders() 获取返回的rsponse Headers,是一个列表:
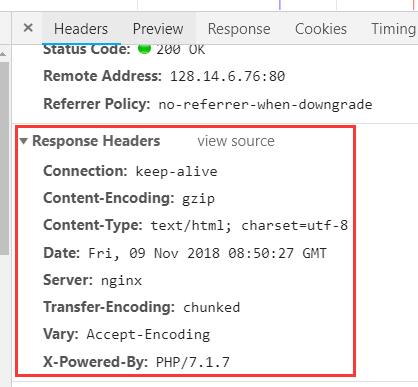
这是我在浏览器种输入网址 再按下F12,在控制台种看到的rsponse Header:
(3)getheader('Server') 获取rsponse Headers中的某一个参数
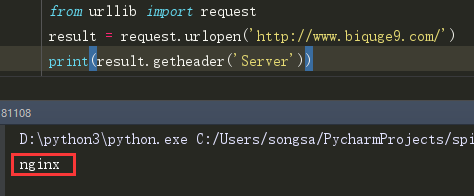
(4)geturl() 获取请求的目标页面的url:
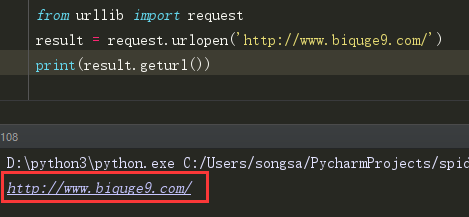
(5)fileno() 以整数的形式返回文件描述符
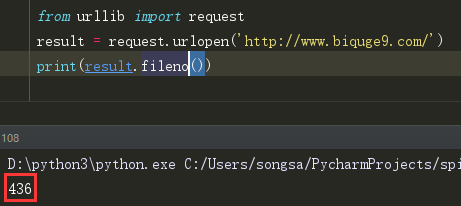
(6)info() 也是返回rsponse Headers种的内容,但并不是以列表的形式。
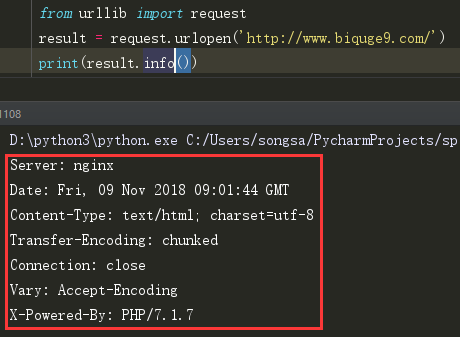
(7)getcode() 获取请求的响应码,如200, 403, 404等待。
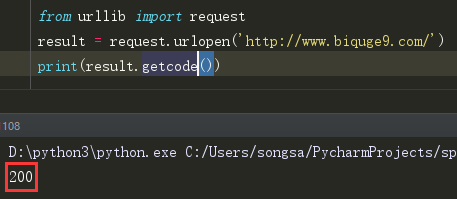
属性:
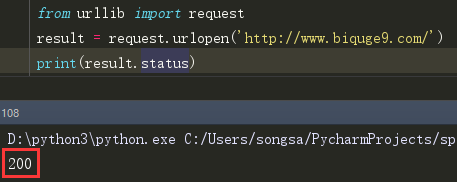
status 这个属性的作用和哪个getcode()方法一样,都是返回响应码
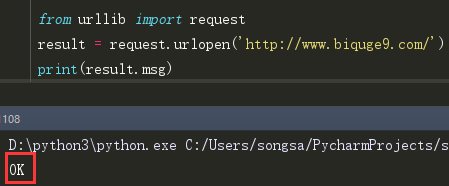
msg 这个属性用来判断请求成不成功,成功的话会返回 “OK”
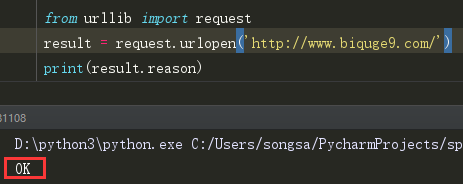
reason 这个和那个msg一样,也是在判定请求是否成功
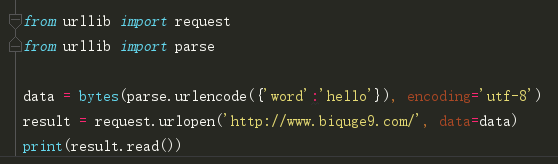
data参数
可选参数,当你在发起请求时想要传递数据,就可用它,
但是数据需要使用bytes()方法将参数转化为字节流编码,且当传递参数后,请求方式就由get变成post了
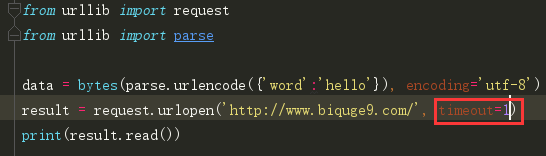
timeout参数
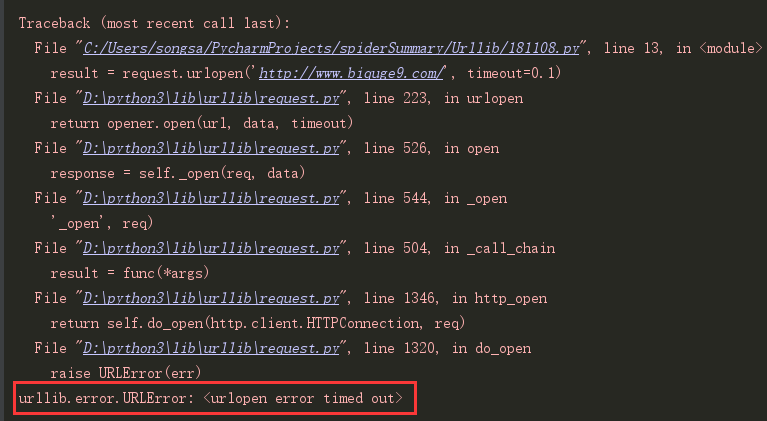
用于设置超时时间,单位是秒,如果请求超出了设置时间还没有响应,就会抛出异常,如果不指定参数,就是用全局默认时间,它支持HTTP、HTTPS、FTP请求。
其他参数:
还有其他参数,如context参数, 他必须是ssl。SSLContext类型, 用来指定SSL设置。
cafile和capath参数 用来指定CA证书和他的路径。
Request()
虽然urllib可以发起请求,但是几个简单的参数并不能构建一个完整的请求,比如它就无法加入headers信息,所以才有的Request()
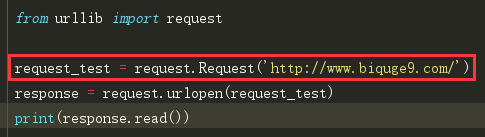
我们同样是使用urlopen()来发起请求,但是并不是直接请求url,而是请求一个Request对象,这样可以将一个请求独立封装为一个对象,而且可以在这个请求对象中配置参数。
这是Request()的构造方法:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
除了第一个url参数必传,其他都是选传参数
第二个data参数,和urlopen()请求中的data参数一样,必须穿bytes()类型,如果它是字典,就得先用urllib.parse模块中的urlencode()编码。
第三个headers是一个字典,他就是请求头,我们用来来传入请求头,可以在参数中直接传,也可以利用add_header()方法进行添加。而请求头中最重要的就是User-Agent和Cookies 这个咱们以后再说。
第四个参数origin_req_host指的是请求方的HOST莫名称或者IP地址。
第五个unverifiable表示这个请求是否无法被验证,默认为False
第六个参数method表示请求方式, 如GET、POST、PUT等
好了,urllib库的第一节就先到这儿,不然篇幅太长了。
想了解更多Python关于爬虫、数据分析的内容,欢迎大家关注我的微信公众号:悟道Python

python3爬虫之Urllib库(一)的更多相关文章
- python3爬虫之Urllib库(二)
在上一篇文章中,我们大概讲了一下urllib库中最重要的两个请求方法:urlopen() 和 Request() 但是仅仅凭借那两个方法无法执行一些更高级的请求,如Cookies处理,代理设置等等 ...
- 6.python3爬虫之urllib库
# 导入urllib.request import urllib.request # 向指定的url发送请求,并返回服务器响应的类文件对象 response = urllib.request.urlo ...
- python爬虫之urllib库(三)
python爬虫之urllib库(三) urllib库 访问网页都是通过HTTP协议进行的,而HTTP协议是一种无状态的协议,即记不住来者何人.举个栗子,天猫上买东西,需要先登录天猫账号进入主页,再去 ...
- python爬虫之urllib库(一)
python爬虫之urllib库(一) urllib库 urllib库是python提供的一种用于操作URL的模块,python2中是urllib和urllib2两个库文件,python3中整合在了u ...
- python爬虫之urllib库(二)
python爬虫之urllib库(二) urllib库 超时设置 网页长时间无法响应的,系统会判断网页超时,无法打开网页.对于爬虫而言,我们作为网页的访问者,不能一直等着服务器给我们返回错误信息,耗费 ...
- 爬虫之urllib库
一.urllib库简介 简介 Urllib是Python内置的HTTP请求库.其主要作用就是可以通过代码模拟浏览器发送请求.它包含四个模块: urllib.request :请求模块 urllib.e ...
- python爬虫之urllib库介绍
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
- Python爬虫学习:Python内置的爬虫模块urllib库
urllib库 urllib库是Python中一个最基本的网络请求的库.它可以模拟浏览器的行为发送请求(都是这样),从而获取返回的数据 urllib.request 在Python3的urllib库当 ...
- 爬虫中urllib库
一.urllib库 urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urllib. ...
随机推荐
- 初学makefile
makefile 需要用到 常用命令.shell.正则表达式.gcc,比较综合. 今天写了一个做一个记录,以后系统总结一下. 目录结构:russia---------include.src.mian. ...
- .NET Core微服务 权限系统+工作流(二)工作流系统
一.前言 接上一篇 .NET Core微服务 权限系统+工作流(一)权限系统 ,再来一发 工作流,我在接触这块开发的时候一直好奇它的实现方式,翻看各种工作流引擎代码,探究其实现方式,个人总结出来一个核 ...
- jquery的.get方法说解
·Customer类 public class Customer { public int Unid { get; set; } public string CustomerName { get; s ...
- springboot 学习笔记(九)
springboot整合activemq,实现broker集群部署(cluster) 1.为实现jms高并发操作,需要对activemq进行集群部署,broker cluster就是activemq自 ...
- 学习笔记:location.hash和history.pushState()
在浏览器中改变地址栏url,将会触发页面资源的重新加载,这使得我们可以在不同的页面间进行跳转,得以浏览不同的内容.但随着单页应用的增多,越来越多的网站采用ajax来加载资源.因为异步加载的特性,地址栏 ...
- UEditor百度编辑器
第一步:首先下载ueditor编译器,地址:http://ueditor.baidu.com/website/ 下载完解压之后就这个: 第二步:我会把文件名utf-8-jsp这个文件名改为uedito ...
- NIO(一)缓冲区
I/O的基本概念 同步和异步的概念: 所谓的同步就是在发出一个请求的时候,如果没有得到结果,就不返回.即调用者主动等待返回结果. 所谓的异步:调用之后直接返回结果,一般通过回调函数来处理这个应用. 阻 ...
- python3基础04(requests常见请求)
#!/usr/bin/env python# -*- coding:utf-8 -*- import requestsimport jsonimport reimport urllib3from ur ...
- UVA Stacks of Flapjacks 栈排序
题意:给一个整数序列,输出每次反转的位置,输出0代表排序完成.给一个序列1 2 3 4 5,这5就是栈底,1是顶,底到顶的位置是从1~5,每次反转是指从左数第i个位置,将其及其左边所有的数字都反转,假 ...
- HDU 1059 Dividing 分配(多重背包,母函数)
题意: 两个人共同收藏了一些石头,现在要分道扬镳,得分资产了,石头具有不同的收藏价值,分别为1.2.3.4.5.6共6个价钱.问:是否能公平分配? 输入: 每行为一个测试例子,每行包括6个数字,分别对 ...